接下來我們想要透過 tf-idf 來建立一個 document retrieval system
import graphlab
# load some text data from wiki pages on people
people = graphlab.SFrame('/home/user/nylon7/machine_learning/week4/people_wiki.gl')
people.head()
| URI | name | text |
|---|---|---|
| http://dbpedia.org/resource/Digby_Morrell ... | Digby Morrell | digby morrell born 10october 1979 is a former ... |
| http://dbpedia.org/resource/Alfred_J._Lewy ... | Alfred J. Lewy | alfred j lewy aka sandylewy graduated from ... |
| http://dbpedia.org/resource/Harpdog_Brown ... | Harpdog Brown | harpdog brown is a singerand harmonica player who ... |
| http://dbpedia.org/resource/Franz_Rottensteiner ... | Franz Rottensteiner | franz rottensteiner bornin waidmannsfeld lower ... |
| http://dbpedia.org/resource/G-Enka ... | G-Enka | henry krvits born 30december 1974 in tallinn ... |
| http://dbpedia.org/resource/Sam_Henderson ... | Sam Henderson | sam henderson bornoctober 18 1969 is an ... |
| http://dbpedia.org/resource/Aaron_LaCrate ... | Aaron LaCrate | aaron lacrate is anamerican music producer ... |
接著我們要做的是瀏覽資料,我們先具體的關注某一個人的資料
# explore the dataset and checkout the text it contains
obama = people[people['name'] == 'Barack Obama']
obama['text']
# barack hussein obama ii brk husen bm born august 4 1961 is the 44th and current president of the united states and the first african american.....
# Get the word count for obama article
obama['word_count'] = graphlab.text_analytics.count_words(obama['text'])
print obama['word_count']

# Sort the word count for obama article
# Turning dictonary of word counts into a table
obama_word_count_table = obama[['word_count']].stack('word_count', new_column_name = ['word','count'])
# Sorting the word counts to show most common words at the top
obama_word_count_table.sort('count',ascending=False)
從中可以發現,有很多單字都是沒有意義的(the、in、and、of...),除了obama
| word | count |
|---|---|
| the | 40 |
| in | 30 |
| and | 21 |
| of | 18 |
| to | 14 |
| his | 11 |
| obama | 9 |
| act | 8 |
| he | 7 |
| a | 7 |
我們無法只針對 obama 做 TF-IDF 因為它是基於全部的文檔,你需要把那些在每篇文章中出現過的文字標準化( normalizer)
# Compute TF-IDF for the corpus
# step 1:get word counts
people['word_count'] = graphlab.text_analytics.count_words(people['text'])
# step 2:#calculate tf-idf & normalizer
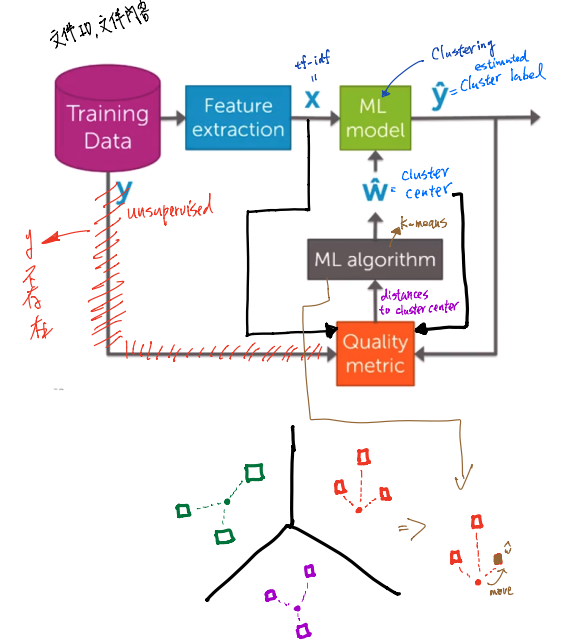
tfidf = graphlab.text_analytics.tf_idf(people['word_count'])
people['tfidf'] = tfidf
tfidf
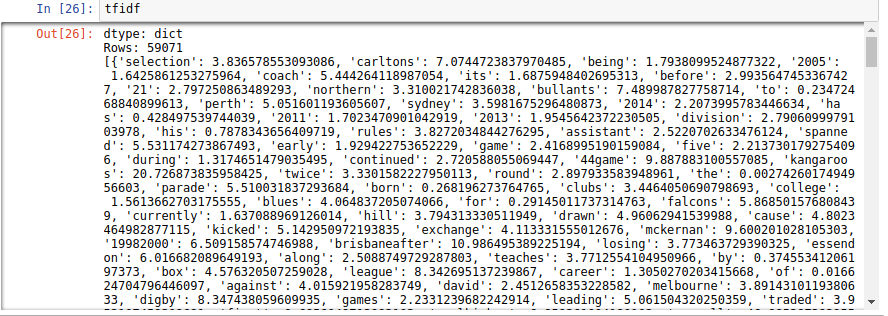
接著我們就可以檢查 Obama 的 tf-idf
# Examine the TF-IDF for the Obama article
obama[['tfidf']].stack('tfidf',new_column_name['word','tfidf']).sort('tfidf',ascending=False)
| word | tfidf |
|---|---|
| obama | 43.2956530721 |
| act | 27.678222623 |
| iraq | 17.747378588 |
| control | 14.8870608452 |
| law | 14.7229357618 |
| ordered | 14.5333739509 |
| military | 13.1159327785 |
| involvement | 12.7843852412 |
| response | 12.7843852412 |
| democratic | 12.4106886973 |
先前我們也做過類似的事情,只不過有意義的單字只有 obama ,但是這次你可以發現單字中充滿了關聯性
先看看目標與觀測點間距離是如何展示的
我們選擇了 Bill Clinton 與 David Beckham ,理論上 Clinton 應該跟 obama 比較近
原因是兩個都是政治人物、前美國總統並且同為民主黨的黨員
# Manually compute distances between a few people
clinton = people[people['name'] == 'Bill Clinton']
beckham = people[people['name'] == 'David Beckham']
# Is Obama closer to Clinton than to Beckham?
graphlab.distances.cosine(obama['tfidf'][0],clinton['tfidf'][0])
# 0.8339854936884276
graphlab.distances.cosine(obama['tfidf'][0],beckham['tfidf'][0])
# 0.9791305844747478
這裡呈現的數字意含著,數字越小代表越接近,因此由結果來看合乎推測
從剛剛到現在我們已經針對個別的人來算出其距離,接下來我想做到的是一篇文章與其他篇文章的距離
在前面的課程中我們有討論過 nearest neighbors model 以及若何將之用於文章檢索上
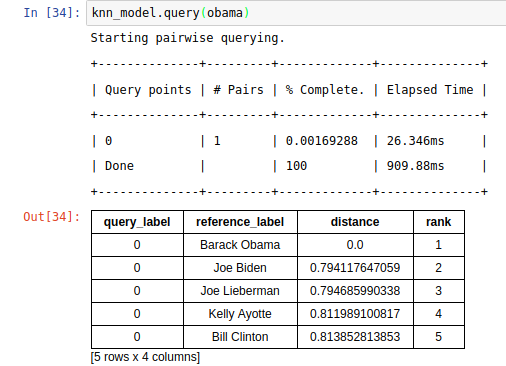
# Build a nearest neighbor model for document retrieval
knn_model = graphlab.nearest_neighbors.create(people,features=['tfidf'],label='name')
# Applying the nearest-neighbors model for retrieval
knn_model.query(obama)
Other examples of document retrieval
jolie = people[people['name'] == 'Angelina Jolie']
knn_model.query(jolie)
| query_label | reference_label | distance | rank |
|---|---|---|---|
| 0 | Angelina Jolie | 0.0 | 1 |
| 0 | Brad Pitt | 0.784023668639 | 2 |
| 0 | Julianne Moore | 0.795857988166 | 3 |
| 0 | Billy Bob Thornton | 0.803069053708 | 4 |
| 0 | George Clooney | 0.8046875 | 5 |
從結果來看,毫無疑問 obama 離自己最近,而 Joe Biden 則是他之前的副手(前美國副總統)
而離 Angelina Jolie 最近的是 Brad Pitt(丈夫),不過我想主因是兩個人都是美國好萊塢影音,而不是因為夫妻關係


