今天要帶大家認識Google Trends API。
Google Trends大家應該蠻熟悉,它可以查詢特定關鍵字在不同國家、不同時間點的搜尋熱度;通常被用來比較像似關鍵字或相同關鍵字在不同國家的表現。
原本Google Trends有官方的API,不過很不幸已經broken了...後來有人自己作unofficial版本,Python和NodeJS都有,今天我們用Jupyter Notebook來練習這個前人已經造好的輪子:)
user@ubuntu: ~$ jupyter notebook
from pytrends.request import TrendReq
import json
pytrend = TrendReq(hl='en-US', tz=360)
tz=timezone
pytrend.build_payload(kw_list=['Donald Trump', 'Obama'], cat=0, timeframe='today 12-m', geo='US', gprop='')
kw_list=放入想搜尋的字串,最多5個(但有方法可以hack,之後的文章在講XD)
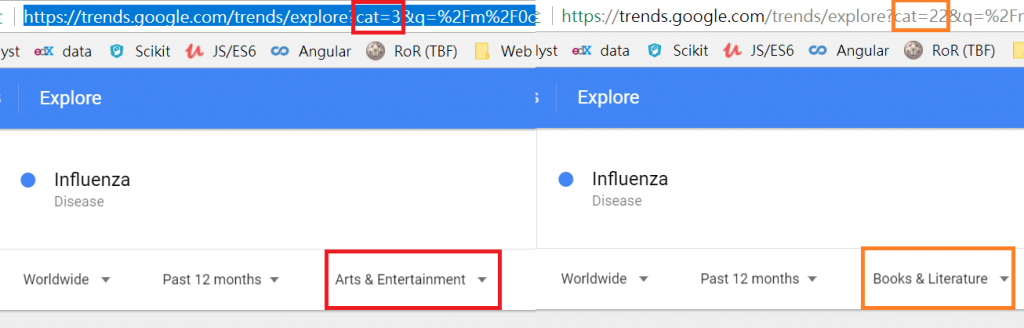
cat=類別,要google trends網站看一下你要的類別編號是什麼(如下圖)
timeframe=時間區段
geo=地理區域,台灣是TW,遇到比較不熟的區域用前面講過的方式來找即可
gprop=Google property,搜尋結果的類型,有image, news, youtube...
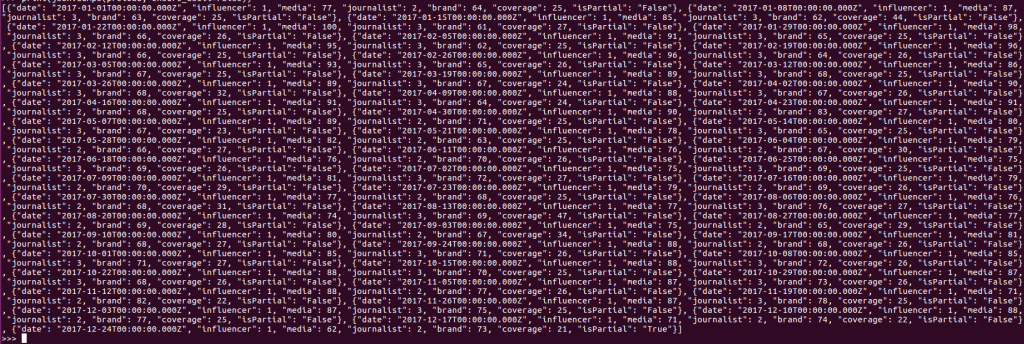
pytrend.interest_over_time()
你會看到日期和"Donald Trump"、"Obama"相對應的搜尋數據分別被列出。假如我們只想看其中一個可以這麼做:
pytrend.interest_over_time().get('Obama')
preload = json.loads(pytrend.interest_over_time().to_json(orient='table'))['data']
print(json.dumps(preload, ensure_ascii=False))
為什麼要先json.loads再json.dumps?
* → 因為一開始生成json時使用的方法如果不用table,日期和排列都會不合適。*
最後你會得到一串搜尋數據(如下圖)