
昨天我們談到萃取法(Extractive Method),從本文中擷取相對重要的字句,當作整篇文章的摘要,雖然可行,但不是我們平常處理的方式,較普遍的作法,應該是消化整篇文章的內容,融會貫通,再以自創的字句描述大意,這就是所謂的『抽象法』(Abstractive Method),作法通常分兩階段:
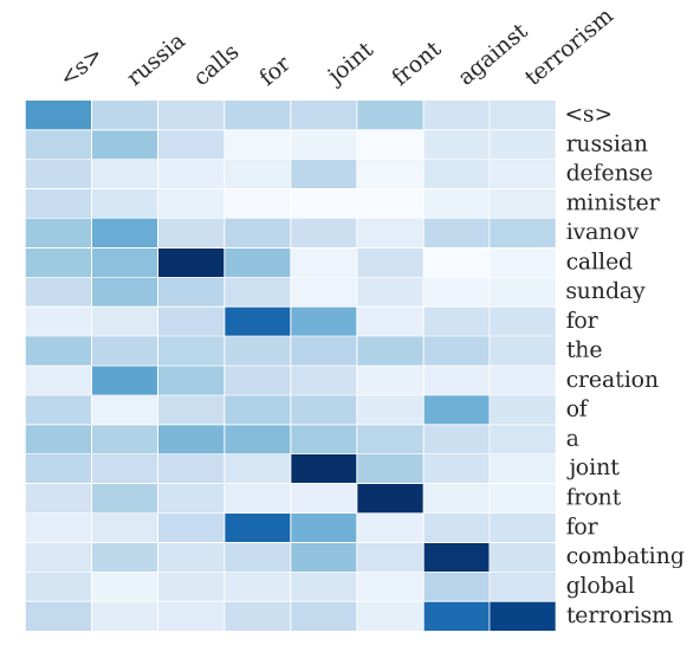
擷取摘要的處理過程如下圖:
圖. 擷取摘要的處理過程,圖片來源:『A Neural Attention Model for Abstractive Sentence Summarization』
除了採取 Neural Network 演算法外,以 Machine Learning 領域而言,也有人使用 Naive-Bayes 分類器,計算 tf-idf,統計 NER 數量,或者使用『決策樹』(Decision Tree)、『隱藏馬可夫模型』(Hidden Markov Model,HMM) 等知名的 data mining 演算法處理,額外考慮字句的位置、相似性,作法相當多,有興趣可參閱『A Survey on Automatic Text Summarization』。
以下我們僅就 Neural Network 演算法作一概念性的介紹,包括Facebook AI Research (FAIR)及 Stanford/Google 合作的模型,兩者都是以 seq2seq encoder-decoder 為基礎,再加上一些其他的概念衍生而成。
這個模型編碼器(encoder)額外實驗三種模型:
最後,再結合 beam-search decoder 技術產生摘要,它使用條件機率計算下一個output,『seq2seq中的beam search算法过程』一文有很清楚的解釋。模型訓練時,使用紐約時報新聞(DUC-2014)資料集,產生14個字的摘要,與資料集與人工撰寫的摘要作比對,以評估其適當性。另外,也用 Gigaword 新聞資料集,它含有950萬條新聞比較。
詳細的說明可參閱『A Neural Attention Model for Abstractive Sentence Summarization』一文。
他們基本上是採用雙向(Bidirectional) LSTM 模型,加上 Attention,如下圖: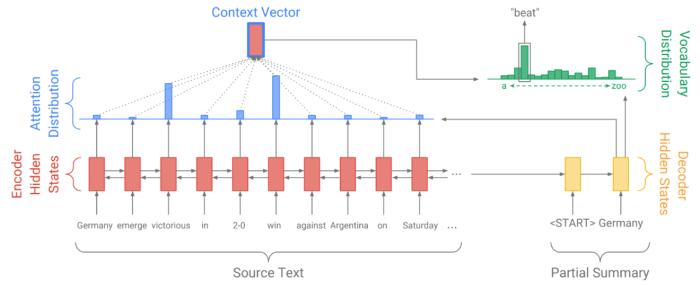
圖. Stanford/Google 模型,圖形來源:Get To The Point:Summarization with Pointer-Generator Networks
模型特點是可以產生在原始本文中未出現的單字,例如,上圖的 beat,就不在本文中,但也因此可能造成摘要不精準,所以,模型略做修改,將上述模型產生的單字與本文的相對位置作比較,誰的機率大,就採用那個單字,公式如下: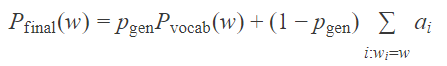
基本上要判斷摘要是否切中命題,就不能以準確率評比了,目前大概有幾個指標:
LCS(longest common subsequence) 指的是預測與實際的摘要相似的單字序列數,n-gram單字比較要連續,LCS不需要。
目前以 ROUGE 為主要評估標準,Stanford/Google 模型用 Gigaword 新聞資料集測試的準確率如下:
ROUGE-1 Average_R: 0.38272 (95%-conf.int. 0.37774 - 0.38755)
ROUGE-1 Average_P: 0.50154 (95%-conf.int. 0.49509 - 0.50780)
ROUGE-1 Average_F: 0.42568 (95%-conf.int. 0.42016 - 0.43099)
ROUGE-2 Average_R: 0.20576 (95%-conf.int. 0.20060 - 0.21112)
ROUGE-2 Average_P: 0.27565 (95%-conf.int. 0.26851 - 0.28257)
ROUGE-2 Average_F: 0.23126 (95%-conf.int. 0.22539 - 0.23708)
部分測試結果如下:
原文: novell inc. chief executive officer eric schmidt has been named chairman of the internet search-engine company google .
人工撰寫的摘要: novell ceo named google chairman
自動擷取的摘要: novell chief executive named to head internet company
======================================
原文: gulf newspapers voiced skepticism thursday over whether newly re - elected us president bill clinton could help revive the troubled middle east peace process but saw a glimmer of hope .
人工撰寫的摘要: gulf skeptical about whether clinton will revive peace process
自動擷取的摘要: gulf press skeptical over clinton 's prospects for peace process
Google 模型有提供Tensorflow範例,要執行必須先安裝 bazel,它類似 Maven,是一個建置程式的腳本工具,程式過長,不適合在此說明,另外,Gigaword 新聞資料集是有版權的,筆者未實際測試,僅參考『Taming Recurrent Neural Networks for Better Summarization』說明,該文認為目前技術能達到的程度如下:
本篇沒有相對的程式可供實驗,感覺有點吃不飽的感覺,如讀者有同感,筆者在此致歉。

