數據科學家和機器學習工程師經常收集數據以解決問題。因為他們試圖解決的問題通常是高度相關的並且存在並且在這個混亂的世界中自然發生,用於表示問題的數據也可能非常混亂和未經過濾,並且通常是不完整的。
這就是為什麼在過去的幾年中,數據工程師等職位的職位出現了。這些工程師的工作內容,旨在處理原始數據並將其轉換為公司其他部門可用的東西,特別是數據科學家和機器學習工程師。這項工作不僅與機器學習的流程同等重要,而且經常被忽視和低估。該領域的數據科學家進行的一項調查顯示,超過80%的時間用於清理和組織數據,其餘不到20%的時間用於創建機器學習流程。
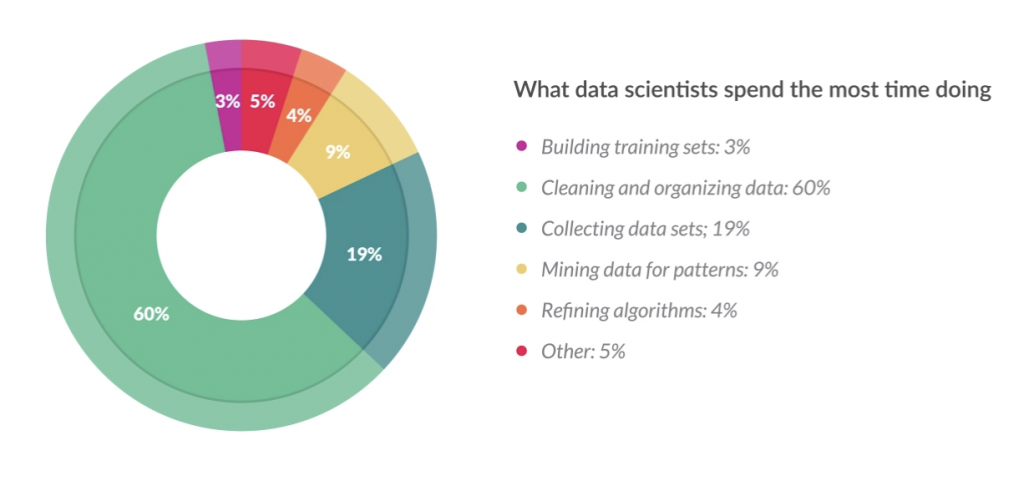
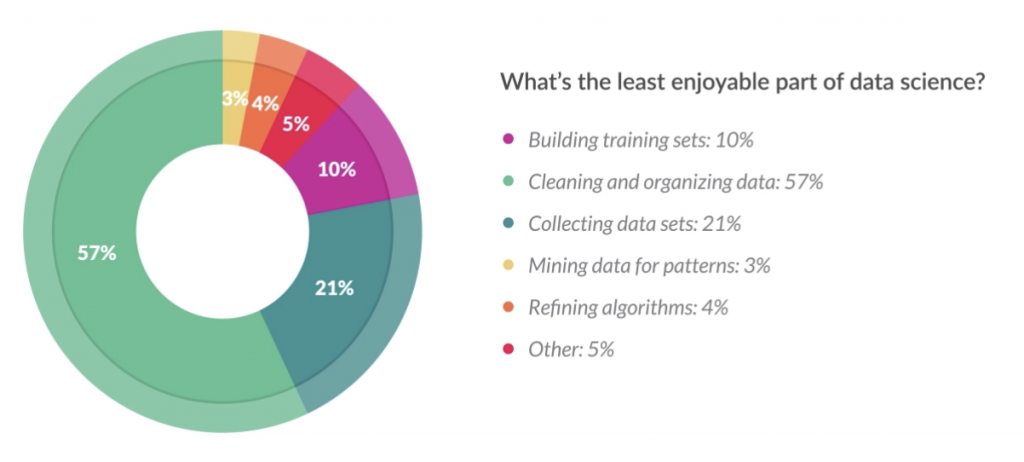
準備數據佔用了每個資料科學項目大部分時間,是一個艱鉅的過程,並且可能是不愉快的。
如前言有提到的,機器學習競賽和學術資源經常會開源清潔完畢的數據,讓使用者無需顧慮過而直接使用。但是超過90%的原始數據,卻是以雜亂無章的形式存在,等待我們對其進行特徵工程,以挖掘出其中蘊含的資訊。
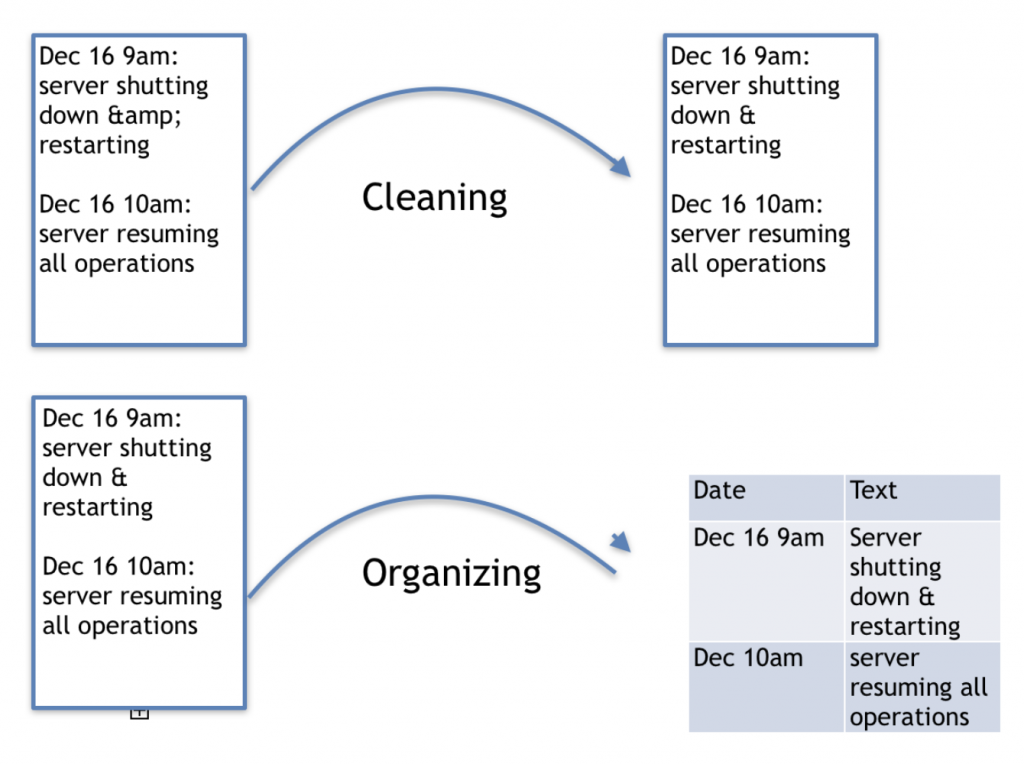
用以上的上下兩張圖分別作為資料清洗以及組織的例子。原始資料取樣自伺服器的日誌,以文字的形式解釋了伺服器發生的事件紀錄。
重點在以下轉換:
Server shutting down “&” restarting -> Server shutting down & estarting
原始文字數據當中,有著“&”的Unicode字元,被轉換成為人為可讀性較高的形式。現在我們看得出伺服器經歷了關閉以及重啟的過程,代替“&”這個意義不明的字元。
接續了資料清洗後的結果,資料組織的過程將其轉換成了類似資料庫table的行與欄位形式。將原本混在一起做撒尿牛丸的文字內容區分成代表時間以及伺服器事件的文字敘述的屬性,也因此此兩屬性便能獨立成為兩個欄位。
未來一個星期預計探討的主題為資料的認識:
圖片及資料出處: https://whatsthebigdata.com/2016/05/01/data-scientists-spend-most-of-their-time-cleaning-data/.

