在一頭栽入特徵工程之前,了解資料的特性是第一步。透過了解資料的特性才能幫助我們在進行特徵工程時,充分發揮不同的資料的原生特點,因為資料類型決定了用於分析和提取結果的方法,不同類型有截然不同的路。使用資料集之前,應先對資料有深入的了解。此舉會讓我們在特徵工程時事半功倍。
在[瞭解資料特徵]中將要提到的幾個主題為:
資料類型決定了用於分析和提取結果的方法,不同類型有截然不同的路,因此使用資料集之前,應先對資料有深入的了解。
本文將是[瞭解資料特徵]系列的開始,瞭解結構化和非結構化資料。
觀測(Observation):一次觀測的結果是指資料中關於某一元素所有表徵的資訊。
表徵(characteristics):是對研究觀察或調查有價值(興趣)的特徵或特質,也稱為變數。
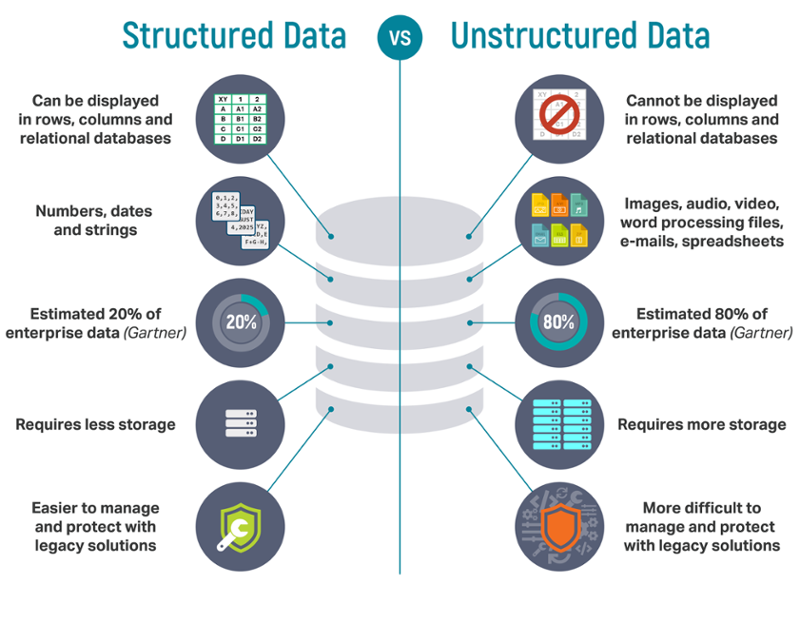
雖然結構化數據(如數字,日期和字符串)可以用行和列表示,但非結構化數據卻不能。非結構化數據的示例包括圖像,音頻,視頻,電子郵件,電子表格和文字處理文檔 - 實質上是存儲為文件的東西。非結構化數據往往比結構化數據更大,佔用更多存儲空間
在開放的github專案中找到的一份資料,是一份只有兩個行(紀錄)的伺服器日誌,格式是純文字檔,以資料庫的角度來看是兩筆單欄位的紀錄,以統計術語解釋則是兩個單表徵的觀測。而該單一表徵是由不同屬性之表徵組成(時間、伺服器狀態),所以是一非結構化資料。
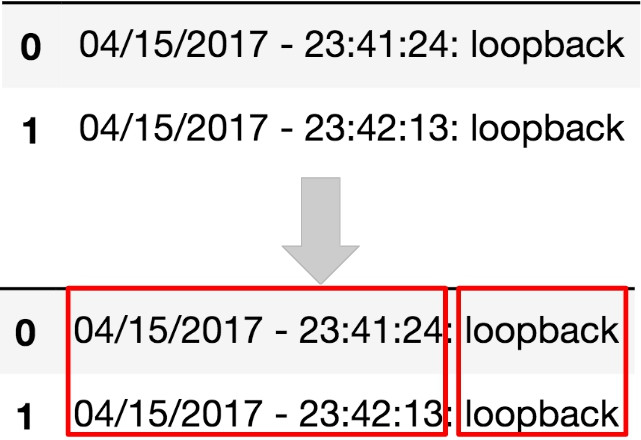
考慮以下是一份資料裡的幾個觀測值:
{
ame:David
age:30
sex:Male
weight:80
},
{
name:Alice
age:30
sex:female
address:somewhere
height:1.64
},
{
name:Bob
sex:Male
phone:0800-520240
},
...
每一個觀測中都有其表徵,但是整體表徵並無一致,因此也是非結構化資料。
由於非結構化與結構化資料的性質差異,有各自的優缺點,也因此流程上需要採用不同的方法。因此在使用資料集之前很重要的一件事就是需要觀察資料的類型,視任務導向決定特徵工程的流程。值得一提的是,此系列文章將專注在結構化資料的特徵工程上。
Kevin 的MongoDB 工作筆記中有一篇關於結構化與非結構化資料的文章,舉例相當鮮明易懂,推薦。
https://kevinwang.gitbooks.io/bigdata/content/general/structured-data.html
統計名詞解釋參考_1: http://web.ntpu.edu.tw/~wtp/statpdf/Ch_03.pdf 統計名詞解釋參考_2: https://zh.wikibooks.org/zh-tw/%E7%B5%B1%E8%A8%88%E5%AD%B8/%E7%B5%B1%E8%A8%88%E8%B3%87%E6%96%99 結構化資料與非結構化資料:https://www.igneous.io/blog/structured-data-vs-unstructured-data


