未來世界裡資料是石油是鑽石,那要選擇什麼挖礦機器才能符合我們呢。這裡有列了十種可以用上的語言與他們的優劣,對於資料分析來說或許R與Python都是不錯的選擇,不過從Python在各大書局架上火紅程度就選用它來學習吧。這邊也參考了2017年的BigDATA組冠軍 tonykuoyj 的文章條理分明很適合初學Python的人~~~因為時間關係python一些基本操作就先不介紹了,等有用到再來說明。我們就直接進入機器學習網站scikit-learn,快速了解一下如何從資料建立model並且對未知的資料做預測。我們可以根據scikit-learn地圖得知手中的data與要解決的問題決定適合哪一類的演算法。
scikit-learn 首頁也將機器學習分六大類方便使用者學習
上面所需要的套件我們只需要安裝Anaconda它是python的懶人包,大部分資料分析、機器學習、視覺化所需要的套件都準備好了,工欲善其事必先利其器!今天就先把這隻大蟒蛇灌入電腦中(根據電腦選定MacOS或Windows~)磨刀霍霍向Data~安裝流程參考
抓資料是一開始的必經之路然而python也有好用的爬蟲可以來爬資料,如何將網頁上的資料爬進來再轉成訓練的通用格式不是現在的重點,我們就先用已經準備好的資料像是sklearn資料集或者是kaggle資料集先來認識一下機器學習資料通常的格式吧,就用著名的鳶尾花資料集來了解一下常用的coding介面:Jupyter與Spyder,這裡有資料集詳細的解說~
from sklearn import datasets
import pandas as pd
iris = datasets.load_iris() #導入鳶尾花資料集
x = pd.DataFrame(iris['data'],columns=iris['feature_names']) #這裡的特徵是花瓣的長寬
x
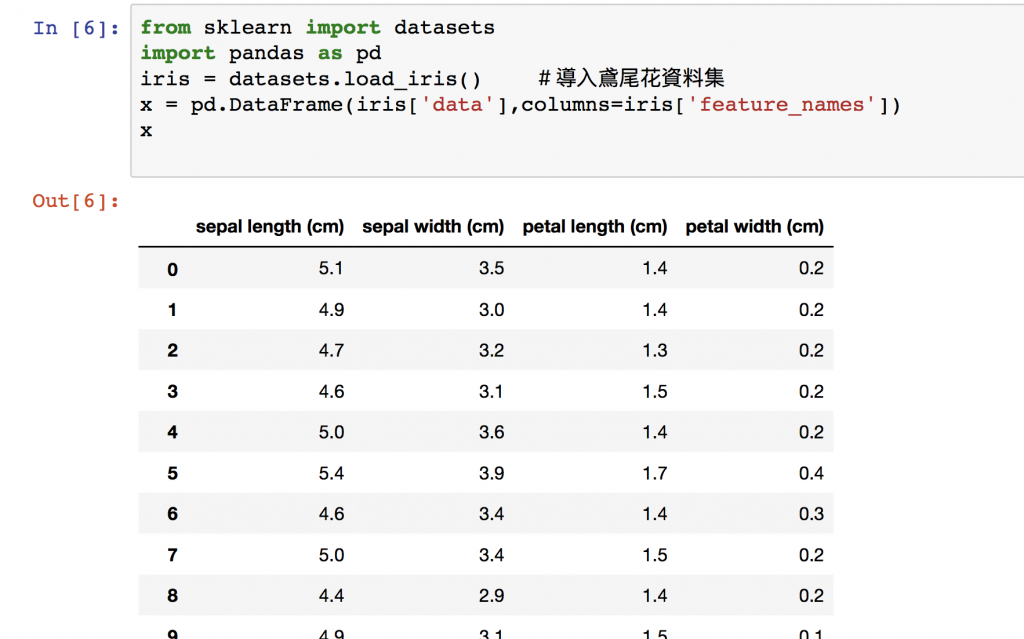
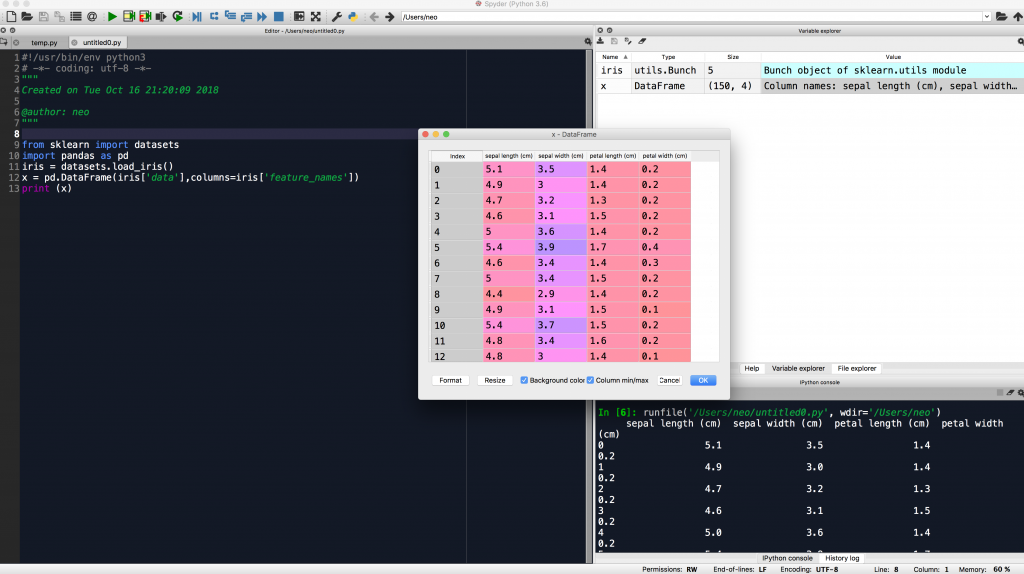
上面兩個介面是資料分析很常用的IDE,Jupyter Notebook 最大的優點就是程式碼可以分段執行,而Spyder則是可以看到變數的改變。各有優缺點在一開始行數比較少的時候使用Jupyter Notebook,當逐漸龐大的時候再轉到Spyder也行。今天就先介紹到這裡,明天再來學習一下Pandas一些常用功能~~



 iThome鐵人賽
iThome鐵人賽