大致上的流程圖如下 數字些許不同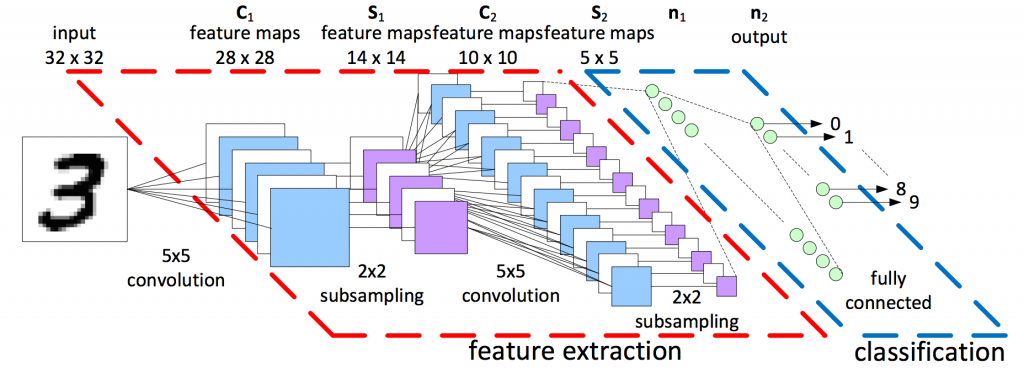 參考網站1
參考網站1
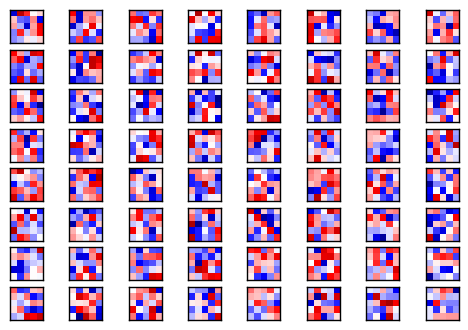
今天要來看一下第二卷積層的樣子,基本上構造跟第一層一樣filter也是5x5但數量變成了64個。然後MAXpooling再一次將像素(第一層之後是14x14)降為7x7
# 印出第二層的filter
plot_conv_weights(W_conv2, 64)
# 第二層filter後的結果
plot_conv_layer(conv2d(h_pool1, W_conv2), mnist.test.images[0], 64)

# 第二層經過 ReLU 的結果
plot_conv_layer(tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2), mnist.test.images[0], 64)

# 第二層經過 MaxPooling 的結果
plot_conv_layer(max_pool_2x2(tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)), mnist.test.images[0], 64)

像素愈少愈看不出來了...但運算完結果機器分得出來就好...
最後全連結層(Fully Connected Layer),Dropout先前講過就是避免某個神經元權重過大因此隨機關掉再作training,而在全連結層之後會接一個 dropout 函數來避免overfitting。

