昨天導入鳶尾花資料集,今天就再詳細的了解一下這個資料的描述吧。當然這個資料集是dict格式(可以花時間了解一下字典格式)
from sklearn import datasets
iris = datasets.load_iris()
for key,value in iris.items() :
try:
print (key,value.shape)
except:
print (key)
print (iris['feature_names']) #鳶尾花的特徵
print (iris['DESCR']) #英翻中當然就是檔案描述囉
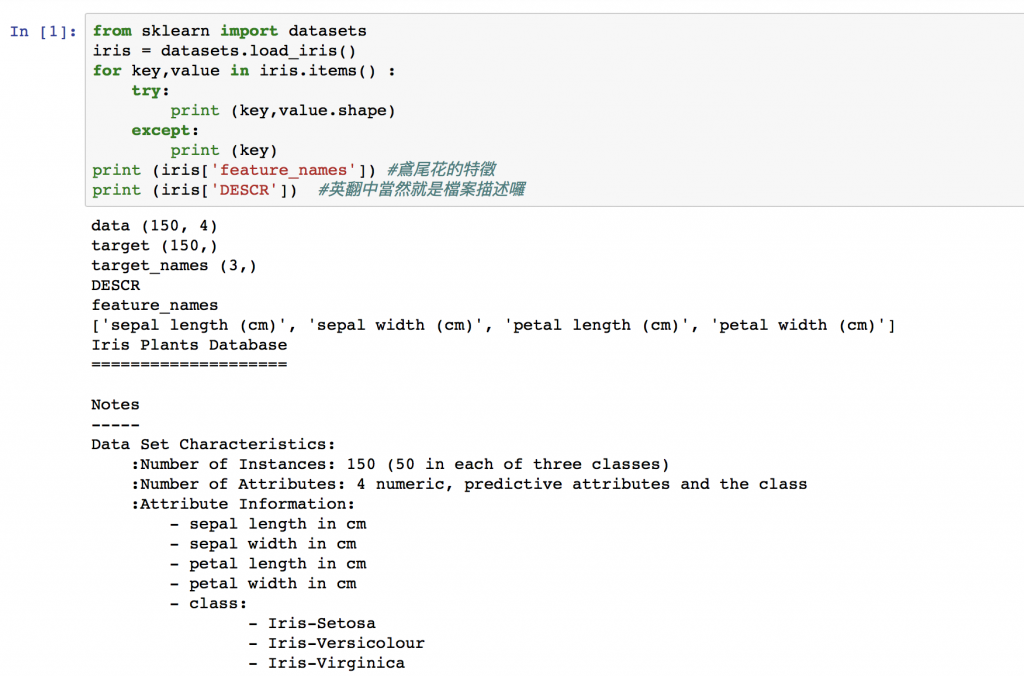
簡單的說這筆資料是從1936年由Fisher建立,分別用花瓣的四種特徵(sepal length,sepal width,petal length,petal width)來分類三種鳶尾花(Setosa, Versicolor, Virginica)總用150筆(target)資料。

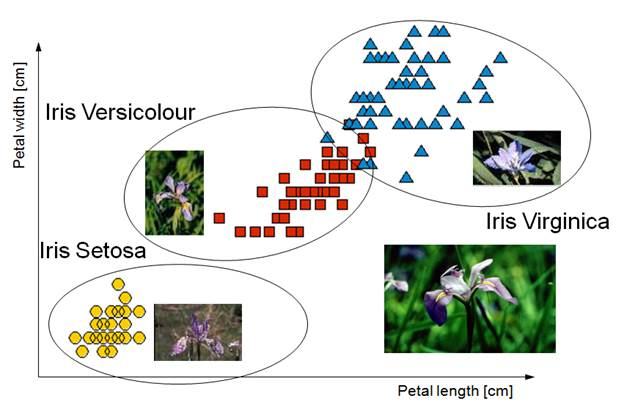
先熟悉一下pandas幾個常用的功能~
首先先把資料轉成Dataframe格式,以後幾乎所有資料都會轉成這種很像excel格式
import pandas as pd
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) # 轉換為 data frame
iris_df.loc[:, "species_label"] = iris.target # 將品種代號加入 data frame
iris_df.head() # 觀察前五個觀測值
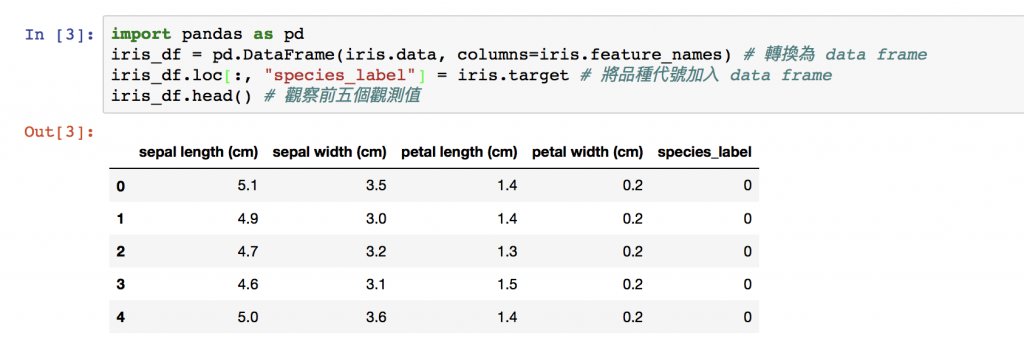
嘗試把品種名稱再加進去,所以先設計一個品種與其對應數字代號的dataframe,再用Merge功能結合起來所以我們有了文字與數字型態共存的dataframe~
species_data = {
'species_label': [ 0 , 1 , 2 ],
'species': ['Setosa', 'Versicolor', 'Virginica']
} #設計一個品種對應編號的Dataframe
df_z = pd.DataFrame(species_data, columns = ['species_label', 'species'])
iris_df=pd.merge(iris_df, df_z, on='species_label') #根據編號來merge
iris_df.head() # 觀察前五個觀測值
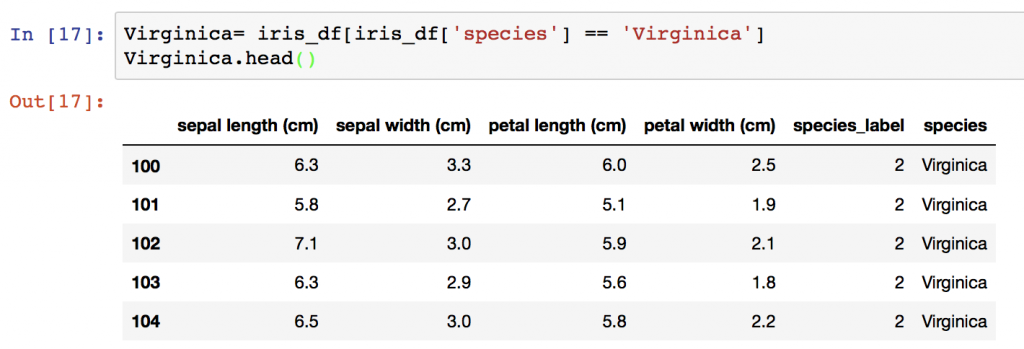
假設只想觀察Virginica的資料
Virginica= iris_df[iris_df['species'] == 'Virginica']
Virginica.head()
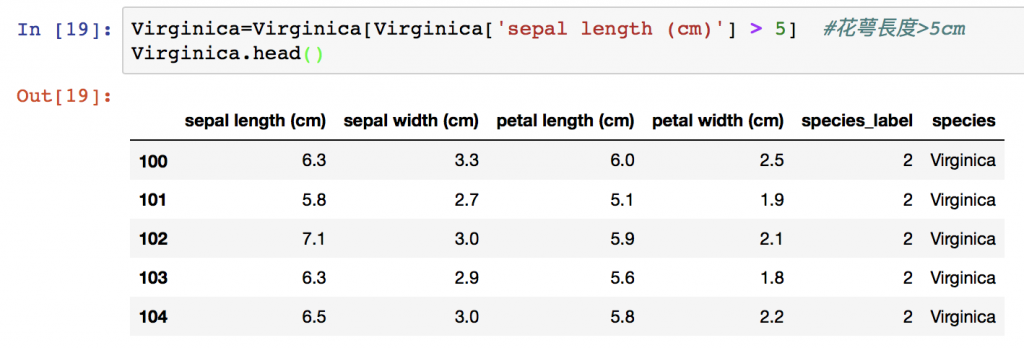
或是只想看花萼長度大於5cm的Virginica
Virginica=Virginica[Virginica['sepal length (cm)'] > 5] #花萼長度>5cm
Virginica.head()
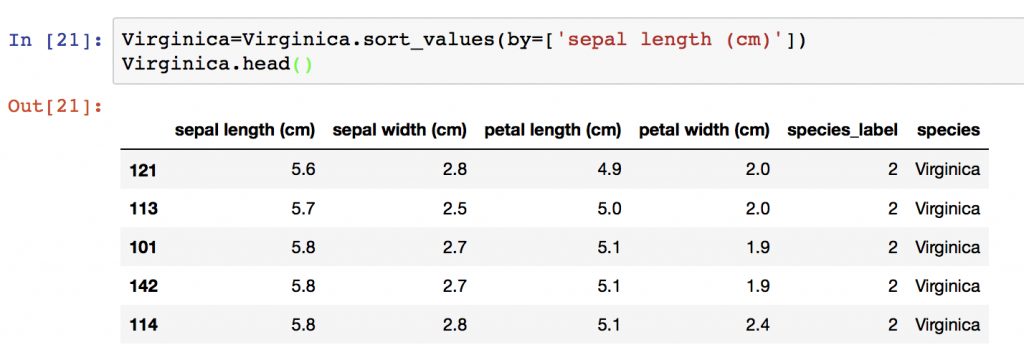
然後再對花萼長度由小到大排列
Virginica=Virginica.sort_values(by=['sepal length (cm)'])
Virginica.head()
今天稍微摸索一下資料處理常用的幾個指令,其他功能在官網以後需要再來查,明天要開使學一些資料視覺化的套件囉~~


