機器學習的技術已經發展了非常久的時間,我們有非常多的模型可以幫我們做預測,包含像是 regression、classification、clustering、semi-supervised learning、reinforcement learning。這些都可以幫助我們去做出預測,或是從資料當中去挖掘知識跟資訊。這些模型需要數學與統計作為基礎。
當你使用這些模型之後你會發現,你輸入的資料會大大的影響整個成效,像是你給的特徵不夠好,模型的表現就變得很糟糕,或是模型要預測的資訊根本不在這些資料當中,那麼模型根本就預測不出來,所以玩過機器學習的人就會知道特徵工程的重要性。
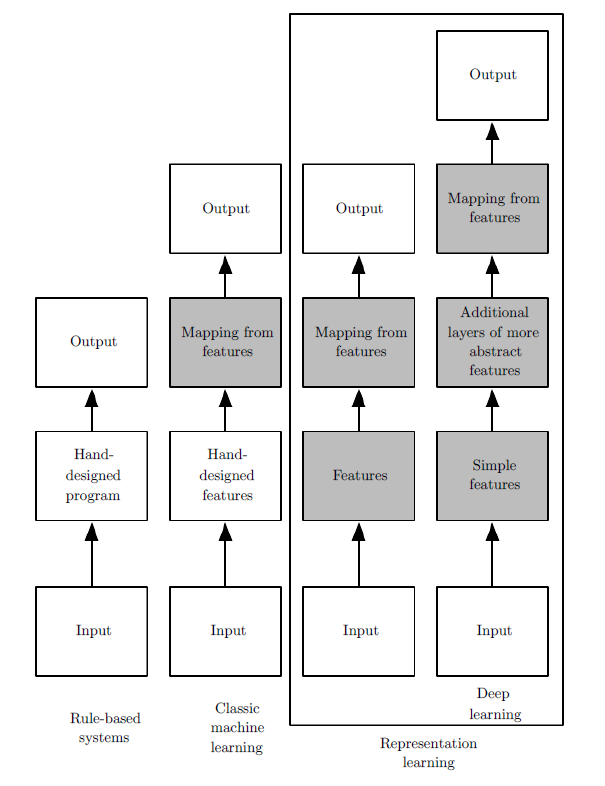
以往特徵工程是需要人自己手動處理的,如今我們也希望由機器學習的模型中自動學出來。大家可以看到我們的技術進展:從以往的手寫程式進展到經典的機器學習技術,這是一個巨大的飛躍。
From Deep Learning by Ian Goodfellow and Yoshua Bengio and Aaron Courville
以往的手寫程式需要工程師非常的聰明,他需要知道在 input 與 output 之間的所有規則,然後把這些規則化成可以執行的程式,這些實作的過程需要花非常大量的人力跟腦力。

然而,我們進展到機器學習的技術,我們試圖去收集一些資料,這些資料符合我們預期的 input 與 output 之間的關係。

他可以幫我們將中間的 過程 連接起來,我們不需要去 手刻 或是 事先知道 這些過程,更何況自然界很多過程都是 人類沒辦法理解的 或是 還不知道的。

這些過程在數學家的眼中就稱為 函數,對於機器學習專家來說,input 與 output 之間有無限多種函數的可能。哪一種可能才是最符合我們資料的長相的?我們希望挑出最有可能的那一種,就把那就把那一種當成是模型,並且輸出,這樣我們就能讓機器自動去學出 input 與 output 的對應關係,這是一個飛躍性的進展。
接著我們意識到:我們還是需要手動去處理特徵。經典的機器學習模型只幫我們處理了 將特徵對應到輸出的關係,我們還是得藉由特徵萃取的技術來轉換,而我們很難知道什麼樣的特徵萃取才真正能夠把資料中我們想要的資訊萃取出來,這部分就進到 representation Learning 的範疇。
在特徵萃取的過程中,常常我們面對的是高維度的向量,由於我們很難去理解高維度的向量之間的轉換,導致我們在轉換的時候會遇上困難,我們根本不知道需要轉換成什麼樣維度的向量,我們也不知道中間需要什麼樣的轉換函數。在數學領域當中,有相關的領域稱為微分幾何,所以常常我們會討論在數學上的流形(manifold),representation learning 就是希望連同特徵萃取以及模型可以一併處理,也就是藉由模型的過程會到回饋(從 gradient descent 等等方法),去引導特徵萃取的過程,進而去學到 特徵-特徵 之間轉換的模式。
深度學習就是一種 representation Learning。他希望資料在高維度的轉換當中,可以去萃取出足夠而抽象的資訊,去進行預測。而深度學習只是將特徵-特徵之間的轉換模式以 層-層 之間的轉換實現,而高維的特徵向量以 層 的形式呈現。所以越深的網路代表著經過多次的函數處理跟萃取,所萃取的資訊的抽象程度越高,抽象程度越高,就越接近人類所想像的。
如同前面描述到的,我們需要更少對於特徵工程的依賴,增加自動化特徵萃取的使用。所以我們用"學習"的方式讓模型自動去學到他要的特徵,自動去做特徵萃取。那麼 representation learning 更深層的意思是什麼呢?
你需要的不是一個答案,而是一個表示方式。
以上是我在工研院的課程對學員們講過的話,一句話解釋 representation learning 大概是這個意思。
舉個例子好了,人類在照片中可以辨識出當中的狗狗,人們在交談的時候可以以語言的"狗"來描述同一個概念,基本上他們都擁有相同的資訊量。對於狗的概念來說,照片中的圖像只是這個概念的一種表示方式,語言中也有對應的表現方式。讓機器學會狗的概念,就是要讓他可以從圖像或是語言中可以萃取出有相同資訊量的東西,這樣的東西可以是以資料結構的方式表示,或是以一個向量表示,所以你需要的不是一個答案,而是一種表示方式,讓你可以看的懂的表示方式。
最終極的情況來說,在人類腦中很多既定的概念都已經存在,並沒有什麼新的概念出現了。出現的只有新的概念以不同的形式或是姿態出現,這互相之間都是可以轉換的,當然,轉換伴隨著資訊量的流失。
記得有個實驗在測試在發展成熟的社會是不是比原始社會的人們更聰明,實驗者設計了類似配對記憶遊戲,在卡牌上畫上各種現代日常生活中會看到的物件,分別測試了都市的人們以及原始部落的人們,果然在都市的人們有比較好的成績。不過這個實驗有個為人詬病的地方,都市人當然熟悉日常生活周遭的物件,原始部落的人們卻從來也沒有看過這些東西。所以又有另一組人馬將實驗換成在原始部落中常常看到的植物的葉子,對都市的人們來說,那些葉子根本無從分辨,但是原始部落的人們的測驗結果卻跟都市的人們對日常生活物件有一樣高的分數。代表人的腦袋並沒有差別,只是認得的東西不同。
或許在人們的腦袋中,有某些概念是一樣的,但是有不同的表現形式。

