SQL的基本寫法,在此只會簡單帶過,往後的部分,會當作大家已經懂一定程度的資料庫知識和SQL基本語法:
很明顯的,這是英文文法,判斷依序是:
先2(資料從哪來)
接著3(篩選那些值要進來)
最後1+4(呈現哪些內容出來)
我使用的是PostgreSQL語法,先說明五個我慣用的SQL寫法,以利後續說明理解:
資料的匯入無論文字數字日期時間,我習慣都先匯成文字(varchar),有2個原因:
- 數字(及時間)類型非常多,有整數、小數等等,還必須考量長度,與其匯入就要耗時思考,不如等真的要用這資料時,再透過習慣的方式處理,況且相同欄位,處理方式不見得一樣。
- 相較於char,varchar比較不占空間,雖然變動的長度會較吃資源,但資料清洗(Data Cleansing)有說過我非常厭惡空格,char絕對不會是我的選擇,況且選擇什麼長度,不就又要頭痛?
所以若遇上數字的運算,很常看到我必須加上::numeric,意思就是必須先轉成數字才能做加減乘除運算。而這並不是整個資料處理的重點所在,所以先知道這件事,之後在我SQL中看到,就不要太困惑這到底在幹嘛了。
偶爾會看到一些人的寫法,把子句(select ... from ... where)寫在自己語法的where後面,或是select後面,小馬我非常不喜歡這樣,這會讓自己語法架構非常混亂,也會讓人不易理解、不易接手、不易解讀。
我個人常用的方式,只會把子句放在from之後,這是為了讓所有人,清楚理解自己每一層的內容,從最裡層,瞭解後,當作 temp table 或暫存的概念,再往後針對這個暫存做其他處理。一層一層如洋蔥般的包覆,架構完整且邏輯清楚,因此小馬我很常有如下的寫法1:
#寫法1
select A.*
------------以下A層----------
from(
select ... from ... where
) A
------------以上A層----------
雖然有人會爭論說,按照我所謂「A層」的邏輯,應該是這樣才對:
#寫法2
select A.*
from(
------------以下A層----------
select ... from ... where
------------以上A層----------
) A
是沒錯,按邏輯來說是寫法2這樣,但我就覺得前面自己寫法1的那樣,以視覺效果來說,比較乾淨俐落呢!這無所謂對錯,就是一種習慣問題吧!
所以如果加了B層,我寫法會如下:
select B.*
------------以下B層----------
from(
select A.*
------------以下A層----------
from(
select ... from ... where
) A
------------以上A層----------
where A.xxx = ...
group by ...
) B
------------以上B層----------
假想把A層收起來
select B.*
------------以下B層----------
from(
select A.*
------------以下A層----------
------------以上A層----------
where A.xxx = ...
group by ...
) B
------------以上B層----------
假想把B層收起來
select B.*
------------以下B層----------
------------以上B層----------
可以發現,我子句無論如何一定寫在from的位置,而不會寫在select和where,甚至group by之處。
以下會不斷提到 OVER (PARTITON BY...) 這個用法,這邊先簡稱為「OP」,往下文字較簡潔。有3個原因:
- Join語句是資料處理過程中,會讓效能變差的原因之一。當然,某些狀況下,以OP寫的效能會更差,例如一次join可以OK的,用OP必須拆成三段以上時,效能就會比較差;但大多數時候,一段OP能完成的事情,會比一次join的效能來得好。(小馬有實測過的,不過有時候還是得視資料型態和處理種類而定。)
- 要做join,表示我必須先把某張表做出來,才能被我拿來join,換句話說,當我在檢查一串語法有沒有問題時,或我在debug時,我要檢查兩份資料,還包括join key等等,這會讓資料顯得複雜不好驗證。
- 語法版面較乾淨,就是一層層資料處理上去,而不會需要又去join某資料進來。
因此,能不用join我都盡量不用,而常用如上所述,一層層洋蔥般包覆加上OP這個視窗函數。絕對必學的視窗函數,這可以讓一堆亂七八糟狗屁倒灶的join,省略成乾乾淨淨的一句語法,使用方式如下: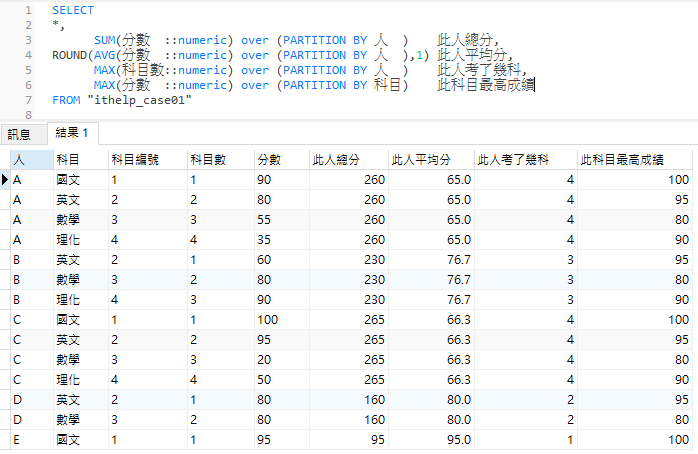
這如果讓join來做,後面4個欄位必須先寫成4個select子句,再join回原表,而OP卻只要寫在同一層即可,就像直接新增四個欄位,讓這個欄位依據某個欄位去gourp by,那樣簡單。
如果是要加入本來就不存在於原始資料的內容,那本來就必須join,沒啥好爭議;這段的意思,指的是那些本來就存在於原始資料,只是必須整理過,很常時候會先把它處理成另外一份小資料,再把它join回來,這種狀況下的join大部分都可以用OP去取代掉。
因此,OVER (PARTITON BY...)是必學的SQL語法!必學!必學!必學!
如果你是SQL同行,肯定眼尖發現上圖寫法不太對勁:沒錯,我select的逗號習慣寫在欄位的後面。我當然知道大家會說把逗號寫在前面,如果你要加雙減號--註釋說明,或是要新增欄位,就不用再移動位置去後面加逗號。
但不知道為何,我看到一行語法的最前面是逗號,心裡就是不舒服。就像是所有比較好一點的文件軟體(例如word)或文字排版(例如這篇文章),肯定不會讓你的逗號出現在一行字的最前面。這是一種視覺上的潔癖和習慣吧我猜......
不過當然啦~因為把逗號寫前面的原因我完全認同,所以各位還是按照自己習慣就好囉。
能 group by 的,絕對不會寫成distinct!
在你的SQL人生中,可以沒有distinct,但不可能沒有group by吧?
事實上我覺得distinct是一種取巧,可以運用在當你想要快速了解某個欄位時;但若一份資料是以資料清洗和資料採礦為目標,擁有多個欄位,那distinct用起來是很不踏實的,尤其是有類似SUM, AVG等聚合運算出現時,group by絕對可以解決所有邏輯運算的概念問題,但distinct不行。
大家有什麼很常用的小技巧、小撇步,
或是對於寫法有什麼特殊見解或判斷,都歡迎留言或私訊我喔~
上一篇:
人工智慧(A.I. Artificial Intelligence) -從Data角度出發
下一篇:
SQL迴圈實作 -2.二種迴圈
感謝大大的分享~
二、子句,只用在from
#寫法2 select A.* from( ------------以下A層---------- select ... from ... where ------------以上A層---------- ) A
對於這部分想分享一下我的作法 我可能會用 WITH clause 去達同樣的效果
e.g.
with
A as (select * from (values (1), (2), (3)) as A(c1)),
B as (select * from A)
select *
from B;
個人覺得這樣又比使用 subquery 更好理解一些

