

今天要來介紹一些進階的 Type syntax 並且實作 Resolver 一個強大的特性,也就是 Field Resover 。這一個強大的設計讓 GraphQL 在資料處理上做到了相當好的隔離效果,也讓 GraphQL 真正能做到 Data Driven (依照資料需求) 而非 Database Driven。
經過昨天的例子,想必大家已經抓到 Object Type 的精髓,接下來我們要錦上添花,介紹更多小工具 (syntax) 來增強 Object Type 的功能!我將會介紹:
[]: 一個不夠,可以放兩個啊在開發 User Type 的過程中,如果遇到像 friends 這種 field ,本質上是另一個 User Type 但需要 用 array 形式展現,只要在定義時用 [] 來圍繞 type 就可以了。
如 friends: [User] 就代表一個 User Type 的 Array 。
同樣地, names: [String] 代表 names 這個 field 值會是一個 String Array。
接下來讓我們看例子:
type User {
...
"朋友列表 ([] 代表 array 之意)"
friends: [User]
}
被 Query 到時會得到
"data": {
"me": {
"friends": [
{
...
},
{
...
}
]
}
}
可發現 friends: [User] 回傳的值就會是一個 Object Array
! 保證期待不落空在定義時後面加上 ! 代表說此項 field 的值不能為 null,比如定義 User 時,正所謂「 DB 在走、 ID 要有」,因此 id 是不可缺少。
type User {
id: ID!
...
}
如此一來,若是 client 端 query 到 id 這個 field 時, server 端就不能讓 id 為 Null,否則 GraphQL 就會報錯。 如圖:
Non-null 好處是讓前端可以確保一定可以從特定 field 得到 non-null 的資料,減少開發的不確定性。
小問題 1: 所以每次 query 到 User Type 時都一定要選 id 這項 field 嗎?
解答在文章末
這時候難題來了,如果 Array Type 配上 Not-null 又會變成怎樣呢? 讓我們看以下的例子
field: User
[O] null
field 為 nullable
fields: [User]
[O] null, [], [null]
fields 為 nullable, array 裡的值也為 nullable
fields: [User!]
[O] null, []
[X] [null], [obj, null, obj]
fields 為 nullable, array 裡的值為 non-null
fields: [User!]!
[O] [], [{ id: ... }]
[X] null, [null], [obj, null, obj]
fields 為 non-null, array 裡面的值也為 non-null
還有更基八一點的: [[User!]]! XDD, 這個就留給讀者自行思考囉~~
但 Non-Null 就完美無缺嗎? 別忘了 GraphQL 要服務各式各樣的 Client 端,不是每個 Client 端的 Query 需求都相同,而當 Client 端相信你給的值的時候卻獲得一個 Null ...他也會無情的回報你一堆 bug 。因此一旦修改 Not-Null field 就會是 Breaking Change。
實戰經驗談:添加 Not-Null 時都要非常小心,因為一旦修改就會是 breaking change。
所以建議是:剛開始設計時,除了 ID 以外的欄位都不要加上!
延伸閱讀:When To Use GraphQL Non-Null Fields
配合以上的 Array Type Syntax ,我們可以擴展我們的 Schema:
type User {
id: ID!
name: String
age: Int
friends: [User]
}
type Query {
hello: String
me: User
users: User
}
接下來就教大家如何實作以上的 Resolver。
上面 Query 中 users 的實作很簡單,只要在 Resolver 新增一個對應的 function 回傳 user data 即可 ;
難就難在 User type 中的 friends 到底要怎麼處理?
這裡有兩種方法,第一種是回傳的 user data 需附上 friends 的所有資料如下:
const resolvers = {
...
me: () => ({
id: 1,
name: 'Fong',
age: 23,
friends: [
{ id: 2, name: 'Kevin', age: 40, friends: [...] },
{ id: 3, name: 'Mary', age: 18, friends: [...] },
]
})
}
此時有沒有發現怪怪的地方?沒錯這裡有兩大問題,第一個是如果今天需要 friends 的 friends 的 friends 話,那你的資料複雜度會高到難以處理 ; 第二是如果你是使用 Relational Database ,你就要先實作一系列的 join 來確保資料的完整性,但最後可能根本沒有被 query 到 friends 這個 field , 另外也無法處理層數更深的 query 。
於是就需要我們的第二種處理方式 : Field Resolver 。
Field Resolver 顧名思義就是針對單一 Field 做資料取得的實作,而其實 Resolver Function 中的 hello, me, user 都算是 Field Resolver ,不過我們將使用這個概念在更細的資料上,也就是
每一個 Field 都可以擁有自己的 Field Resolver ,不管是 Object Type 或是 Scalar Type
小問題 2 : 所以如果 GraphQL 在處理回傳資料時發現有一個 field 早已有值卻也有自己的 Field Resolver 的話是使用誰的結果?
以下就進入 Coding 部分直接帶大家了解:
Query 裡新增 usersUser 並包含 friends 的 field resolverconst { ApolloServer, gql } = require('apollo-server');
// 1. 在假資料中補充朋友資訊
const users = [
{ id: 1, name: 'Fong', age: 23, friendIds: [2, 3] },
{ id: 2, name: 'Kevin', age: 40, friendIds: [1] },
{ id: 3, name: 'Mary', age: 18, friendIds: [1] }
];
// The GraphQL schema
// 2. 在 Schema 添加新 fields
const typeDefs = gql`
"""
使用者
"""
type User {
"識別碼"
id: ID
"名字"
name: String
"年齡"
age: Int
"朋友們"
friends: [User]
}
type Query {
"A simple type for getting started!"
hello: String
"取得當下使用者"
me: User
"取得所有使用者"
users: [User]
}
`;
// A map of functions which return data for the schema.
const resolvers = {
Query: {
hello: () => 'world',
me: () => users[0],
// 3-1 在 `Query` 裡新增 `users`
users: () => users
},
// 3-2 新增 `User` 並包含 `friends` 的 field resolver
User: {
// 每個 Field Resolver 都會預設傳入三個參數,
// 分別為上一層的資料 (即 user)、參數 (下一節會提到) 以及 context (全域變數)
friends: (parent, args, context) => {
// 從 user 資料裡提出 friendIds
const { friendIds } = parent;
// Filter 出所有 id 出現在 friendIds 的 user
return users.filter(user => friendIds.includes(user.id));
}
}
};
const server = new ApolloServer({
typeDefs,
resolvers
});
server.listen().then(({ url }) => {
console.log(`? Server ready at ${url}`);
});
這邊要補充一下大家一定會有的疑問: friends(parent, args, context) 是什麼? 這是 GraphQL 會自動幫我們傳入的參數,其實在 Query 中的 hello, me, users 三個 function 的參數裡也會是這個形式,不過為了閱讀方便且並未用到所以我就省略了。
那我們就來啟動 Server 然後再輸入 Query 吧:
{
me {
name
friends {
id
name
}
}
}
會得到
{
"data": {
"me": {
"name": "Fong",
"friends": [
{
"id": "2",
"name": "Kevin"
},
{
"id": "3",
"name": "Mary"
}
]
}
}
}
如圖:
此外也可以 query users 看會得到什麼結果喔 !
有人一定會說,每遇到一次 field resolver 就要訪問一次 database 的話不是會造成效能負擔?沒錯,但基本上一定比你 RESTful 的 multiple round trip 來得省時。
但如果你一次要拿超大量資料的話,仍會造成 N + 1 problem 的問題,不過別擔心,之後會教大家如何克服 ,可先參考 這篇 (基本上公司系統有使用過,效果不賴)
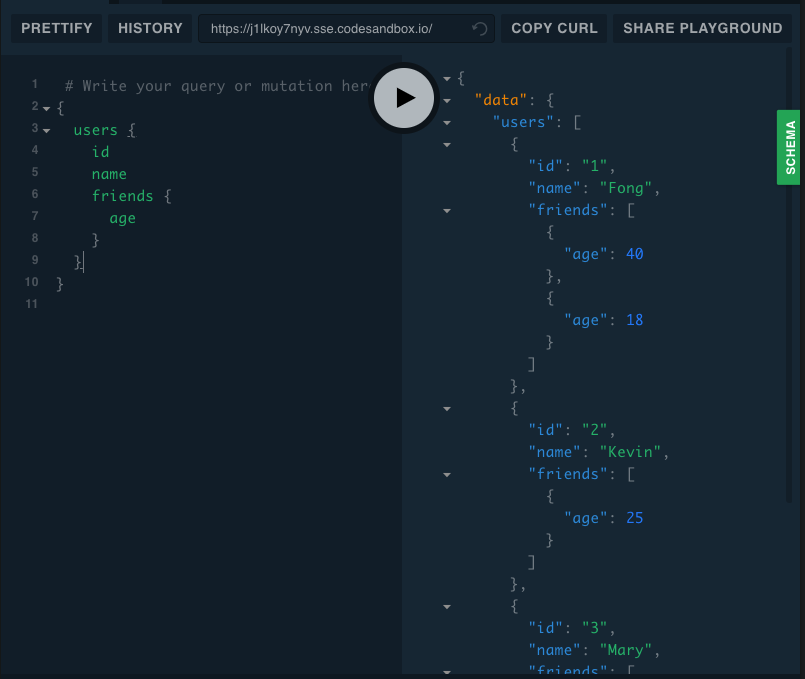
請 query 出所有 user 的 id, name 以及 friends 的 age 。答案 點開圖
今天就到這邊,想必大家都已經掌握了基本的 GraphQL 技巧,可以再學習更進階的 query 技巧以及相對應的 Schema + Resolvers ,那就明天見~
小問題 1: 所以每次 query 到 User Type 時都一定要選 id 這項 field 嗎?
Not-Null ! 只代表說 如果有選到,那 Server 對於這項 field 就不能給出規定的 Type 以外的選項包括 Null,所以 query 時若沒有挑選這項 field ,就不會有影響。
小問題 2 : 所以如果 GraphQL 在處理回傳資料時發現有一個 field 早已有值卻也有自己的 Field Resolver 的話是使用誰的結果?
在處理程序上,GraphQL 是一層層處理,在以上例子中 GraphQL 會先處理 Query 的 me field Resolver ,拿到資料後才會進入 User 的 field Resolver。所以決定最終值的當然是後者。
小問題 3: 咦?所以說好的對於 Scalar Type 的 Field Resolver 呢
通常很少會對 Scalar Type 做 Field Resolver ,等下一篇介紹 Argument 後才比較有機會。但還是可以給你範例:
const resolver = {
...,
User: {
...,
name: (parent, args, context) => {
const date = new Date();
// 假如今天萬聖節
if (date.getMonth() + 1 === 10 && date.getDate() === 31) {
return parent.name + ' ~~ Happy Halloween';
}
return parent.name;
}
}
}

{kind=link}