這個題目其實我去年失敗的挑戰中也有講過,大家可以去回味一下。
這裏就用一張圖來帶出常用的Libray。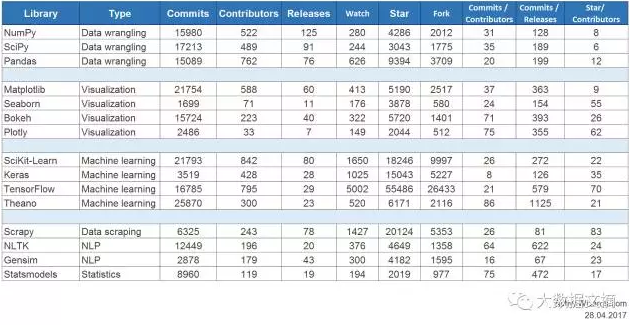
首先是SciPy Stack,應該是指這類的Library的集合
我個人先把他分成幾類
基本上Numpy是比較底層的操作、Scipy是基於Numpy一些進階的數學函數、Pandas比較像是資料操作在用的
ML中,除了SciKit-Learning外,都是Deep Learning的技術,目前還不打算挖那麼深。
目前先把把基礎打好,Numpy, Scipy和Pandas算必選,Sci-kit learning也是我們解題必須學習東西,另外會再看一個視覺化的工具,應該會是Matplotlib為主。
參考資料:
2017 年 15 個最好用 Python 庫,學習資料科學、機器學習絕對不容錯過
[[Day 10] Kaggle的解題挑戰 - Python資料分析相關Library]([Day 10] Kaggle的解題挑戰 - Python資料分析相關Library)


 iThome鐵人賽
iThome鐵人賽