其實這篇應該先寫於《精進魔法》系列之前的,但沒關係,只要有 [地圖] 深度學習世界的魔法陣們 指引,你能夠照你想要挑戰的項目去學習。
以下介紹深度學習的魔王們,這些是我們在優化模型時可能遇到的挑戰:
Ill-Conditioning
是指訓練過程中,目標函數的表現不規律,因此很難用當前的梯度去預測最佳點所在的位置,只能慢慢地逼近最佳點,因此訓練時需要更多的迭代次數。
雖然在神經網絡之外可以用牛頓法( Newton’s method)來避免,但對於深度學習來說,牛頓法需要額外進行修改才能應用於神經網絡。
Local Minima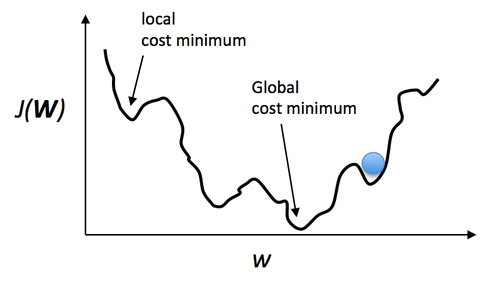
圖片來源:https://sebastianraschka.com/faq/docs/logisticregr-neuralnet.html
指的是在做梯度下降時,最佳點落在了局部最低處,而非 Global Minima。可以用 Momentum 來降低困在 Local Minima 的機率。
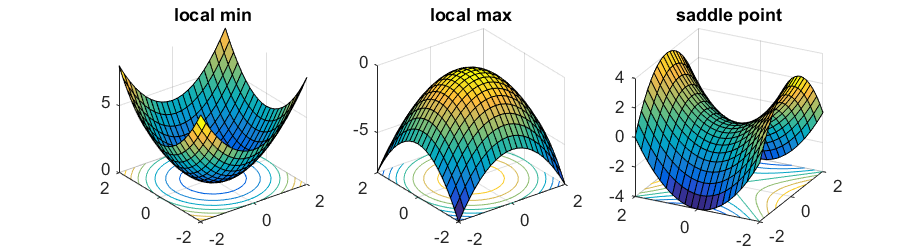
圖片來源&延伸閱讀:https://www.offconvex.org/2016/03/22/saddlepoints/
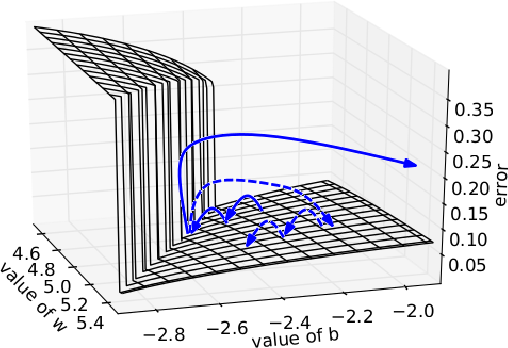
圖片來源:https://www.semanticscholar.org/paper/Understanding-the-exploding-gradient-problem-Pascanu-Mikolov/728d814b92a9d2c6118159bb7d9a4b3dc5eeaaeb
Long-Term Dependencies
當神經網絡結構變深可能會遇到另一個大魔王就是 Long-Term Dependencies(長期依賴)問題,由於經過多階段傳播(propagation)後,可能導致梯度消失或者爆炸(vanishing and exploding gradient problem),使模型喪失先前學習到的能力,讓優化變得非常困難。
Inexact Gradients
在某些情況,目標函數是難以處理的,當目標梯度不存在或者計算複雜度非常高,我們只能採用近似梯度,但可能因計算不精確而影響到優化表現。實際上各種神經網絡的優化演算法設計都考慮到梯度估計的缺陷,可以選擇比真正的 loss function 更容易估計的 surrogate loss function 來避免這個問題。

《為美好的世界獻上祝福》魔王軍幹部-維茲 圖片來源

