接下來幾天要來介紹Scikit-learn(SKlearn),SKlearn在python中提供大量常見的機器學習演算法和許多實用的資料集合,像是Iris以及手寫辨識數字的資料(之後的程式舉例會用到)。而演算法的部分,可以在SKlearn官網中看到,他將功能分為6個部分:Classification、Regression、Clustering、Model selection、Preprocessing、Dimensionality reduction,各個適合的演算法,在SKlearn中也有做相當清楚的圖表,呈現該演算法資料輸出的型態,相當方便,之後也會在舉例中也會一一介紹。

圖片引用於SKlearn官方網站:http://scikit-learn.org/stable/index.html
就像前一篇Day8-什麼是機器學習中提到,在機器做學習之前,要先有正確讓機器了解的數據,因此,接下來幾天要先來討論如何在Scikit-Learn中產生最佳的數據資料表。
import sklearn
上方提到的Iris資料集合,在python中可以用seaborn來下載iris數據集合,這個數據集合主要紀錄三種鳶尾的型態。
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
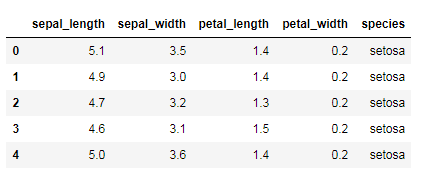
由上方output資料表來看,可以知道iris這個資料集合主要是紀錄花的種類、花萼及花瓣的長寬。
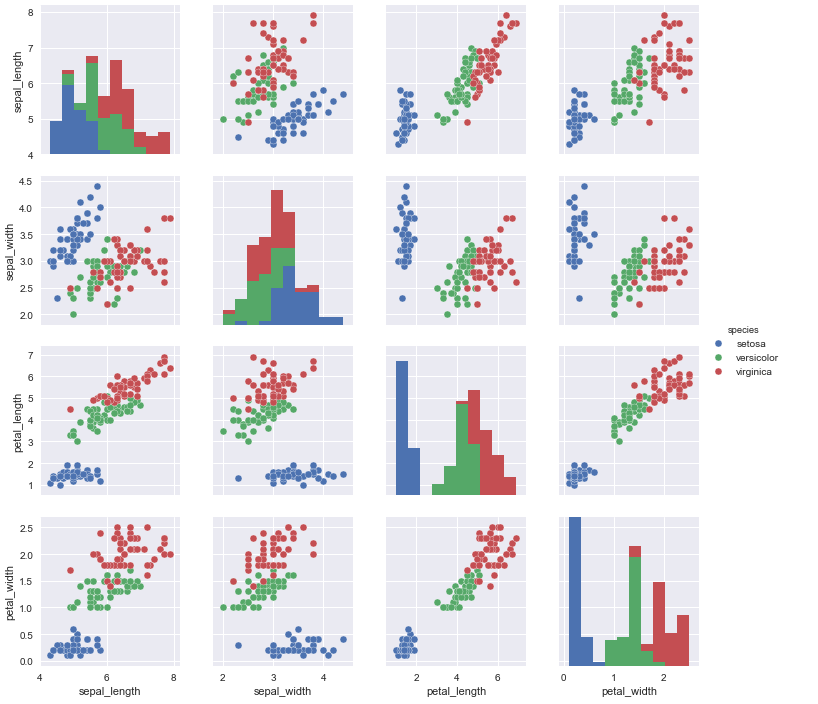
sns.set()
sns.pairplot(iris, hue='species', size=3);
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(42)
x = 50 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50)
plt.scatter(x, y)