在昨天的文章中,簡單介紹SKlearn內有的資料集合,並且有簡單做一個線性回歸範例,今天要來一步一步講解,如何利用SKlearn中的模組來實做。
1.選擇一類模型
在Scikit-Learn中,包含許多類型,像是線性回歸、決策數、PCA...等,今天以計算簡單的線性回歸模型為例,可以在 sklearn.linear_mode 導入線性回歸的類別
from sklearn.linear_model import LinearRegression
2.選擇超參數模型
選擇完模型後,還是可以針對自己本身的資料做一些參數設定,像是在做資料模型時,需要用到多少的元件?是否要設定適宜的偏移量(Y的截距)?如何讓資料達到正規化?...等問題來設定參數。對於線性回歸的範例,我們可以實例化LinearRegression類並指定我們想要使用fit_intercept超參數來擬合截距:
model = LinearRegression(fit_intercept=True)
model
out:LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
3.把資料規劃到特徵矩陣和目標向量中
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
out:LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
4.預測未知數據的標籤
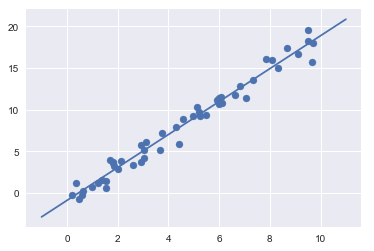
一旦訓練了模型,監督機器學習的主要任務就是根據它所說的關於不屬於訓練集的新數據的內容來評估它。在Scikit-Learn中,可以使用predict()方法來實做此操作。
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);