昨天介紹完超參數模型(Hyperparameters and Model Validation),今天要來介紹如何利用SKlearn實作特徵工程(Feature Engineering),並介紹一些常見的特徵工程範例,像是分類數據、文本、圖像。
一種常見類型的非數字數據是分類數據。例如,假設您正在探索一些有關房價的數據,以及“價格”和“房間數量”等數字特徵,甚至還可以獲得“鄰居”資料。下面一一介紹如何將數據依照類型分類:
data = [
{'price': 850000, 'rooms': 4, 'neighborhood': 'Queen Anne'},
{'price': 700000, 'rooms': 3, 'neighborhood': 'Fremont'},
{'price': 650000, 'rooms': 3, 'neighborhood': 'Wallingford'},
{'price': 600000, 'rooms': 2, 'neighborhood': 'Fremont'}
]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False, dtype=int)
vec.fit_transform(data)

vec.get_feature_names()

但這種方法有一個明顯的缺點:如果您的類別有許多可能的值,這可能會大大增加數據集的大小。
vec = DictVectorizer(sparse=True, dtype=int)
vec.fit_transform(data)

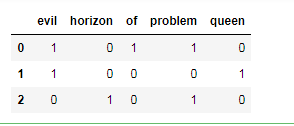
將一份具有代表性的文本,轉換為一組有代表性的數值。例如,挖掘社交軟體的數據,將挖掘到的資料透過單詞計數轉換為數值,計算其中每個單詞的出現次數,並將結果放在表格中。
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X = vec.fit_transform(sample)
X

import pandas as pd
pd.DataFrame(X.toarray(), columns=vec.get_feature_names())
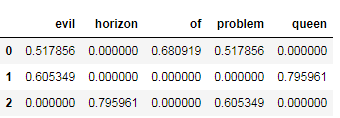
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
X = vec.fit_transform(sample)
pd.DataFrame(X.toarray(), columns=vec.get_feature_names())
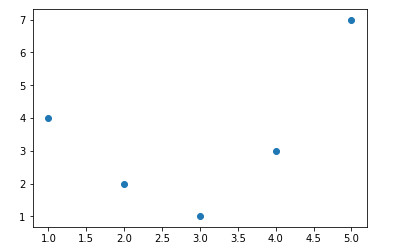
當我們從輸入數據構造多項式特徵時,我們在超參數和模型驗證中看到了,線性回歸直接轉換為多項式回歸,而不是通過分類來改變模型,而是通過轉換輸入,稱為「基函數回歸(basis function regression)」。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1, 2, 3, 4, 5])
y = np.array([4, 2, 1, 3, 7])
plt.scatter(x, y);
from sklearn.linear_model import LinearRegression
X = x[:, np.newaxis]
model = LinearRegression().fit(X, y)
yfit = model.predict(X)
plt.scatter(x, y)
plt.plot(x, yfit);
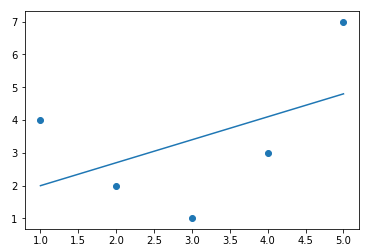
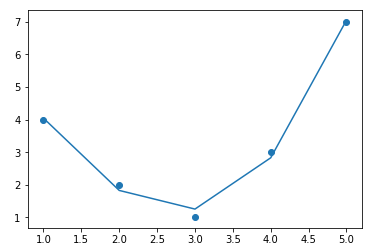
從上方的輸出結果中,可以看到我們需要更有效的方式來運算x和y的關係。
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=3, include_bias=False)
X2 = poly.fit_transform(X)
print(X2)

model = LinearRegression().fit(X2, y)
yfit = model.predict(X2)
plt.scatter(x, y)
plt.plot(x, yfit);