在做完資料處理及特徵篩選後,接下來就是選擇演算法來訓練我們的模型,這階段算是機器學習流程中最關鍵的部分了,通常我們會依據想預測的問題以及現有的數據資料,來決定要使用什麼樣的演算法,例如一個二元分類的問題,我們可以選擇用邏輯回歸、決策樹、神經網路等適合的演算法建立我們的模型。
在 Azure Machine Learning Studio 中,可以看到以下幾種演算法:
- Anomaly Detection 異常檢測
- Classification 分類
- Clustering 分群
- Regression 迴歸

Anomaly Detection 異常檢測
用來檢測出異常現象,或是超出合理範圍的情形。
例如:詐騙交易偵測、異常帳號偵測、機械故障偵測、信用卡盜刷偵測等等,但也因為異常情形不常見,所以樣本資料的收集會比較困難,像是詐騙偵測可能就需要收集黑名單資料等。
Azure Machine Learning Studio 提供以下兩種異常檢測演算法:
- One-Class Support Vector Machine 一類支持向量機
- PCA-Based Anomaly Detection 主成分分析(Principal Component Analysis)異常偵測

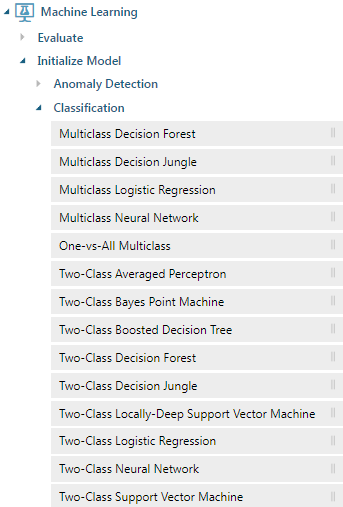
Classification 分類
分類演算法用來將某個人事物歸類在多個類別中的某一類別裡,很常用來做預測。例如:
- 詐騙預測會將類別分為詐騙及非詐騙,就屬於二元分類問題。
- 潛在VIP客戶預測,會將現有的一般客戶及VIP客戶資料去做分類模型,一樣是分成兩個類別,一般客戶及VIP客戶,可以知道在甚麼條件下很有可能會成為VIP客戶,當所有條件都符合了,銷售人員就可以推銷此客戶,被打槍率也會降低。
在 Azure Machine Learning Studio 中,可以看到以下幾種分類演算法:
- Multiclass Decision Forest
- Multiclass Decision Jungle
- Multiclass Logistic Regression
- Multiclass Neural Network
- One-vs-All Multiclass
- Two-Class Averaged Perceptron
- Two-Class Bayes Point Machine
- Two-Class Boosted Decision Tree
- Two-Class Decision Forest
- Two-Class Decision Jungle
- Two-Class Locally-Deep Support Vector Machine
- Two-Class Neural Network
- Two-Class Support Vector Machine
Clustering 分群
分群演算法是使用非監督式學習(Unsupervised Learning)把資料分到不同的類別中,跟分類(Classification)不同的地方在於,輸出的結果在分類演篹法中是已經定義好的,但分群沒有預先定義其結果,所以在執行分群之前,無法知道每個資料屬於哪一種類別。
例如:遊戲公司做問卷調查,取得了年齡及遊戲時間等資料,發現結果分為3群,第1群是重度玩家,每天都會花很多時間在遊戲上;第2群是業餘玩家,偶爾會玩一下;第3群則非玩家,幾乎不玩遊戲,可以藉由結果了解公司的目標客群。其中最常使用的分群法為 K-mean 演算法,它使用點與點的距離將相似的資料聚集在一起,我們只需要決定 K 值即可,也就是要將結果分成幾群,若設定 K=4,就代表結果會分成 4 組。
在 Azure Machine Learning Studio 中,可以看到以下分群演算法:

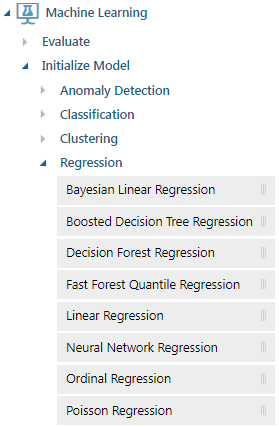
Regression 迴歸
迴歸可以用在當輸出結果為數值資料時。
例如:客服中心的來電數量,就可以用迴歸來預測。
在 Azure Machine Learning Studio 中,可以看到以下幾種迴歸演算法:
- Bayesian Linear Regression
- Boosted Decision Tree Regression
- Decision Forest Regression
- Fast Forest Quantile Regression
- Linear Regression
- Neural Network Regression
- Ordinal Regression
- Poisson Regression
對於選擇演算法,也可以參考官方提供的適用於 Azure Machine Learning Studio 的機器學習演算法小祕技

