
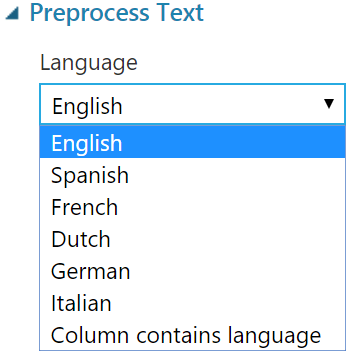
若資料集有包含大量文字,而且需要使用此資料來協助預測,在 Azure Machine Learning Studio 中,可以使用 Preprocess Text 來處理文字資料,目前支援 6 種語言:
Preprocess Text 文字分析可以執行以下處理,Ex:清除 the , a 等常見單字、數字、特殊字元、重複字元、電子郵件地址、URL...等文字,將單字轉為小寫,句子間用 ||| 隔開: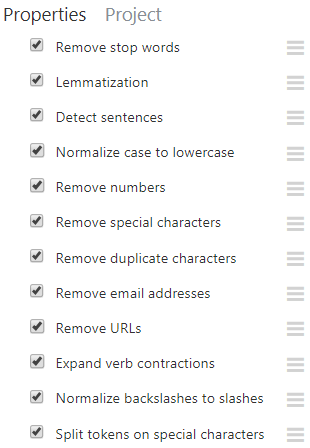
【Dataset】新增資料集:Book Reviews from Amazon 書籍評價資料集,包含兩個欄位,一個是評分,一個是文字評論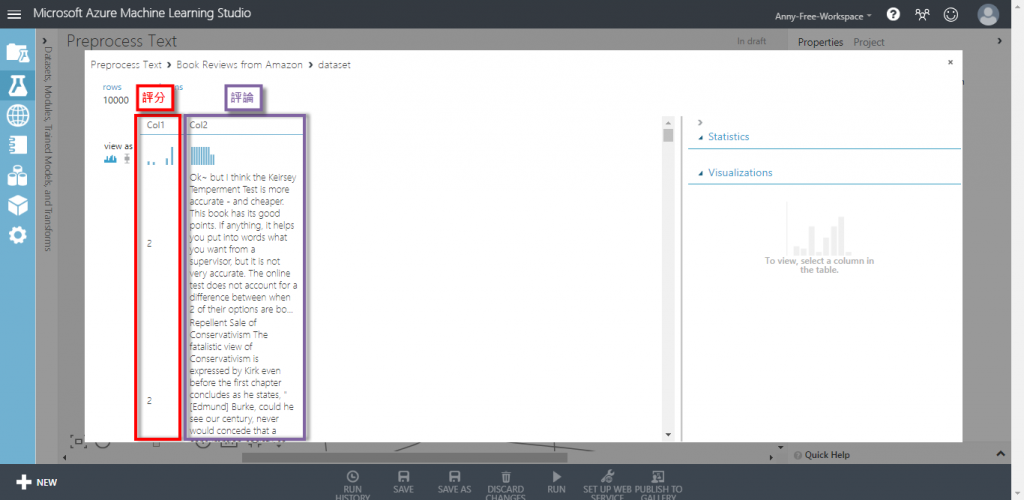
【Edit Metadata】將評分欄位 Col 1 設為 Make categorical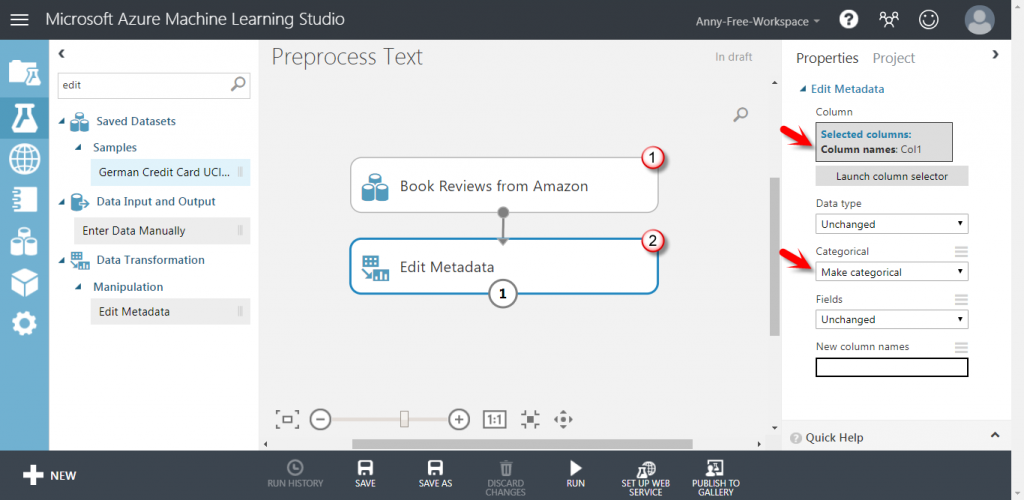
【Group Categorical Values】新增 Group Categorical Values ,將評分欄位 Col1 的值分為低分、高分兩種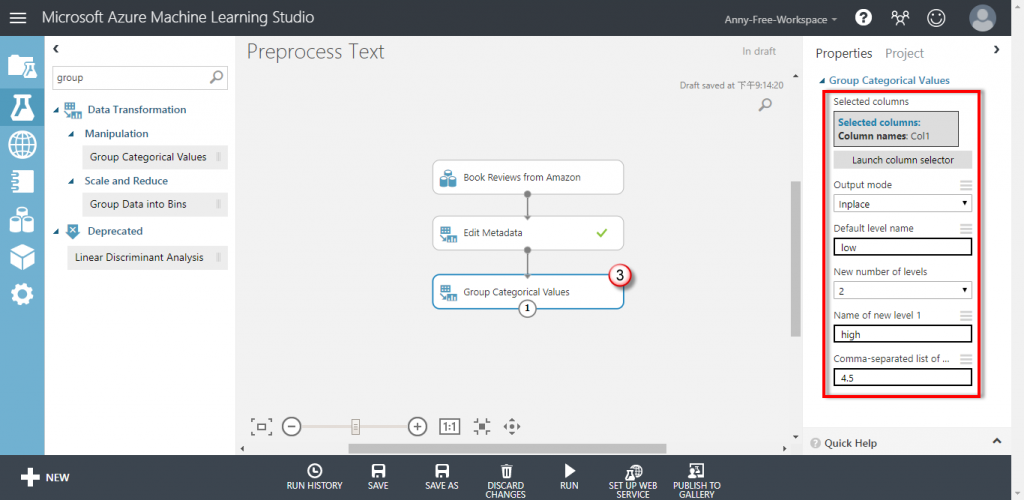
【Preprocess Text】新增 Preprocess Text,選擇 Col2 文字評論欄位,使用預設勾選的文字處理,可以清除雜訊資料,找出重要的特徵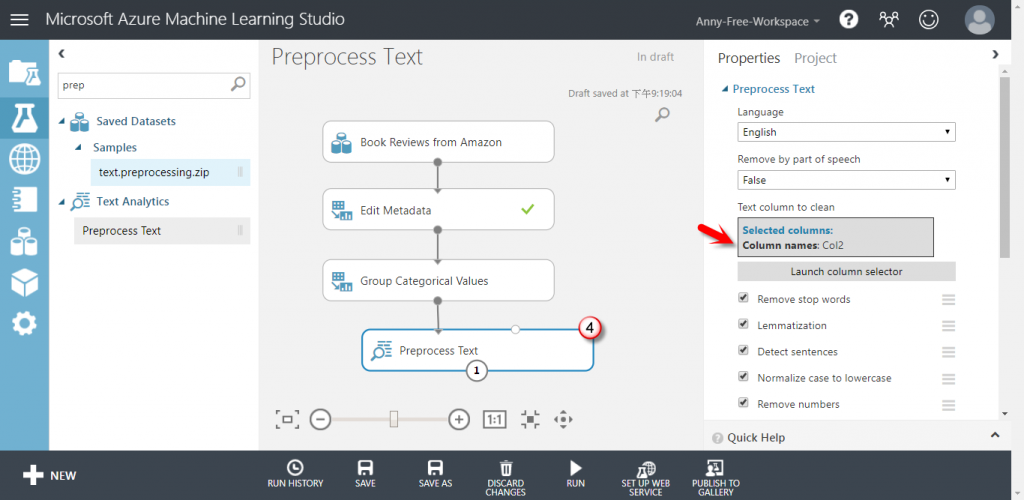
可以看到新的欄位 Preprocessed Col2 為 Col 2 的文字處理後的結果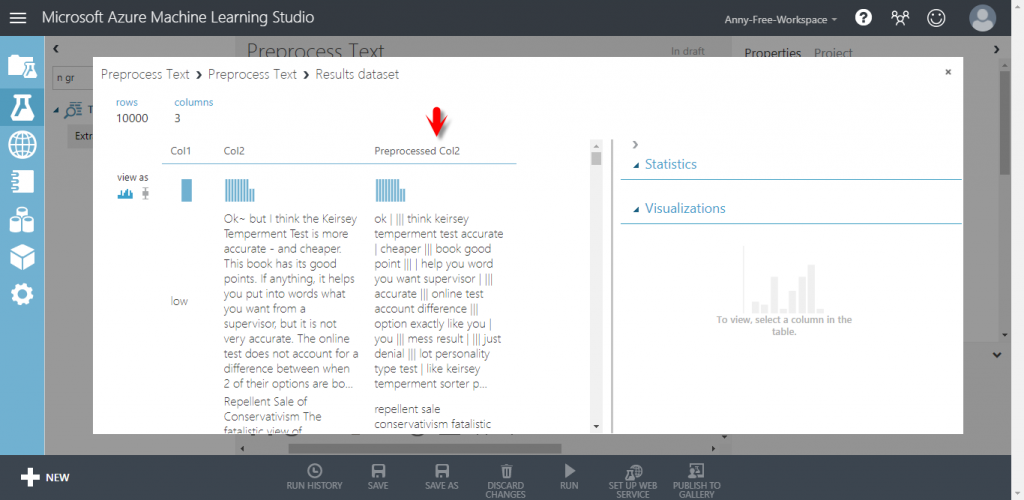
【Split Data】將資料切分為訓練集、測試集資料
【Extract N-Gram Features from Text】新增 Extract N-Gram Features from Text,從剛剛處理過的文字中,選取與預測目標最相關的特徵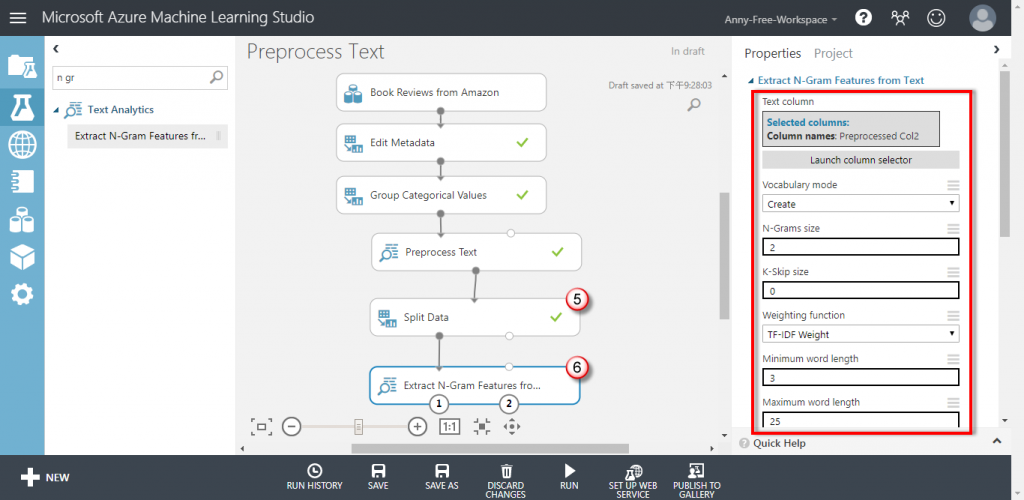
設定以下屬性: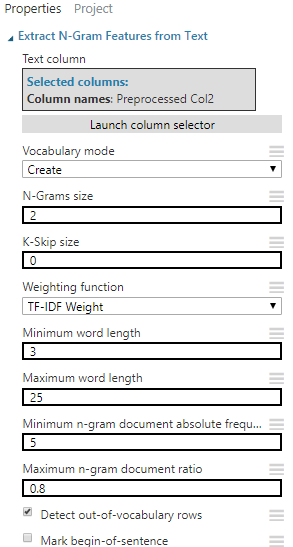
【Train Model】訓練模型
【Two-Class Logistic Regression】二元分類邏輯迴歸分析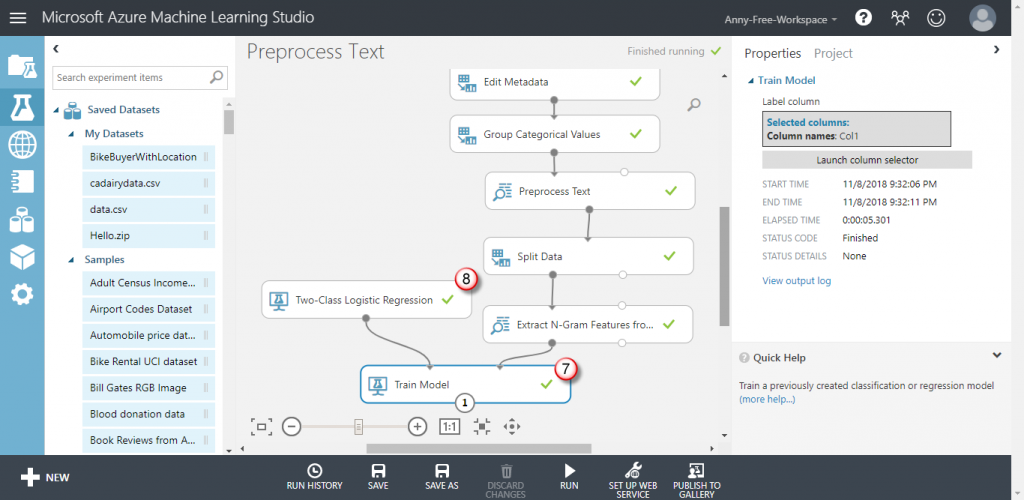
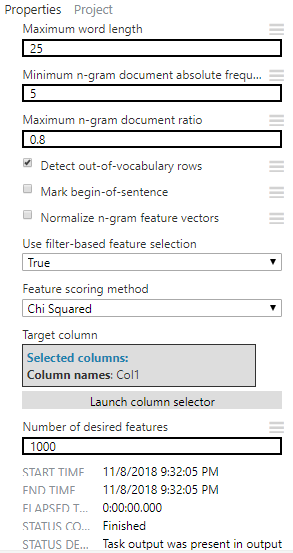
【Extract N-Gram Features from Text】再新增一個 Extract N-Gram Features from Text,來處理測試資料集
【Score Model】計分模型:執行預測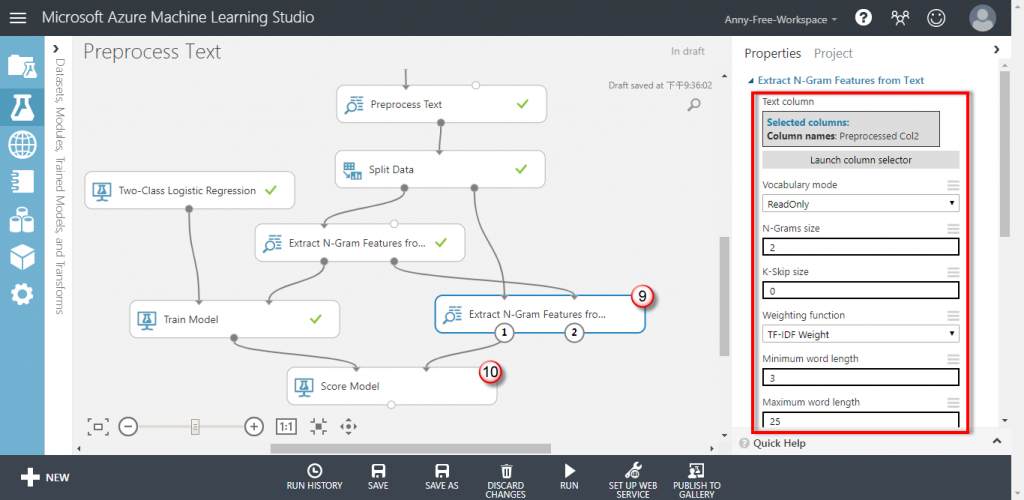
設定以下屬性: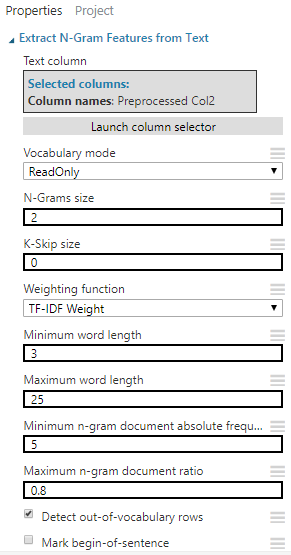
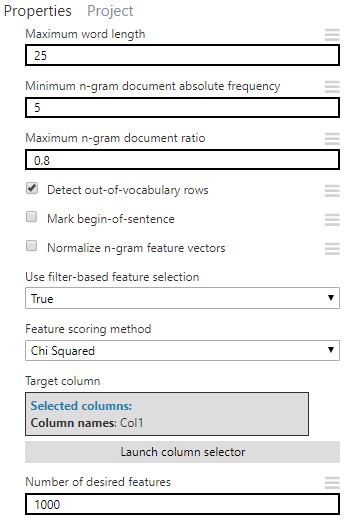
【Evalute Model】評分模型:查看預測結果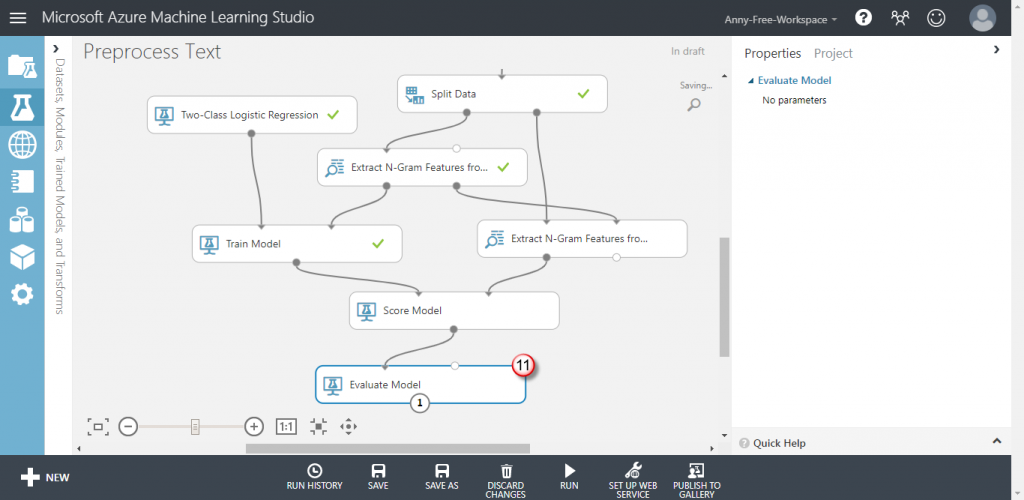
參考文章:在 Azure Machine Learning Studio 中建立文字分析模型
