線上計算模型與先前介紹的幾種計算模型(隨機存取模型、外部存取模型、平行計算模型)不太一樣。線上計算模型主要聚焦在資料的變化,而非計算工具的改變。
對於一個問題,如果我們想要改一點點資料,再回答相同的問題。由於資料改變量不大,因此我們可以試圖對之前計算過的部份內容加以利用。而此時考慮把演算法改成線上計算的版本就會是一個明確的選擇。
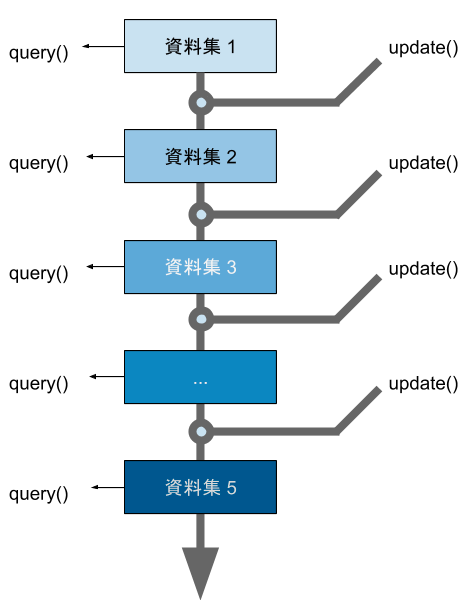
一般來說,我們在設計線上演算法的時候,為了取得更好的效率(儲存部份計算結果),我們會一併設計適當地資料結構。而對於該資料結構而言,所有支援的操作就會被分類成兩種:更新操作 update() 與詢問操作 query()。通常更新操作是指對資料集的改動,而詢問操作則是要求演算法(或資料結構)回答出針對當下資料集作為輸入時,問題的答案為何。
在這樣的模型下,我們可以把執行時間分成以下三種時間:預處理時間(preprocessing)、更新時間(update time)、與詢問時間(query time)。各種不同的演算法,會依據實際的需求而在這三種時間之間會有消長的現象。換句話說,不見得每次 update 完就會跟著 query,很可能會累積許多 update 以後才久久一次 query。這個我們之後可以看到例子~
我們在分析一般演算法的時間複雜度的時候,通常會希望取得 worst-case analysis:也就是說,在假設最糟糕的輸入情形下,該演算法仍在指定時間內完成計算並正確輸出答案。但是,當我們考慮線上計算模型的時候,可能有些 query 很好回答、某些要跑很久才能回答。大家可以把這個程式想像成一個 HTTP server,如果我們關心的是任一個 request/query 的最糟可能回應時間(latency),在演算法的世界裡面我們會把它稱為 worst-case analysis。如果我們允許某些 request/query 可以跑久一點,但只要平均起來能夠送出的回應夠多(throughput),那在演算法的世界裡面我們就會把它稱為 amortized analysis。
但是,為了能夠理解什麼樣子的輸入叫做「最糟糕輸入」,我們引入「假想敵」的概念,描述什麼樣子的輸入是被允許的。
所謂的「最糟糕輸入」的概念就會變成:有個假想敵,會試圖根據你現在計算的過程,給予你更糟糕的 update,使得 update / query time 變得更糟。
於是我們可以根據假想敵的能力,把線上輸入模型再大致分成三類:
從上面可以推得,Oblivious Adversary 其實是對我們(演算法設計者)最好的,最有可能達到好的時間複雜度。而 Full Adaptive Adversary 對我們來說最為嚴苛,因為資料結構都被看光光了,很容易被找出花時間的地方,或是剛才沒算到的地方加以攻擊。
明天來與大家分享一些例子~


 iThome鐵人賽
iThome鐵人賽