
收集資料也是生物資訊領域也很重要的一環,而且不是每個資料庫網站都很貼心地提供API讓我們很同意地取得資料,故這最後一天姑且讓我們來看看怎麼使用Julia進行爬蟲好了。
今天我們想要爬一下StackOverflow上面關於julia-lang這個關鍵字的所有問題及連結,另外我想看一下這些問題是否有被回答或討論,以及我還想知道這個問題得到多少票,我們可以這樣做
using HTTP
using Gumbo
using Cascadia
keyword = "julia"
url = "https://stackoverflow.com/questions/tagged/$keyword"
response = HTTP.get(url)
html = parsehtml(String(response.body))
questionsummary = eachmatch(Selector(".question-summary"),html.root)
for qs in questionsummary
votes = nodeText(eachmatch(Selector(".votes .vote-count-post "), qs)[1])
answered = length(eachmatch(Selector(".status.answered"), qs)) > 0
href = eachmatch(Selector(".question-hyperlink"), qs)[1].attributes["href"]
title = nodeText(eachmatch(Selector(".question-hyperlink"),qs)[1])
println("$votes $answered [$title](http://stackoverflow.com$href)")
end
執行之後,就可以看到結果了:
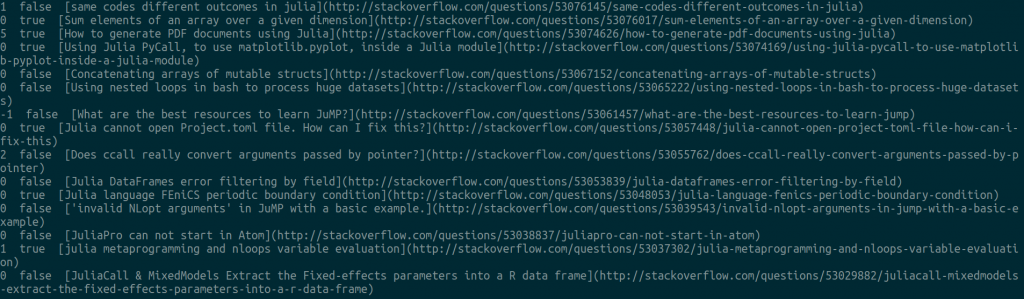
是不是還算挺方便的呢?
喔天阿!我還沒有用過 Julia 爬過網站,可是看起來超級流暢的啊!
也是剛好看到有人在講怎麼用Julia寫RESTful API才想到同樣可以用HTTP.jl的方式,拿來爬蟲。
