「Deep Learning模型最近若干年的重要进展」一文提到深度學習分四個脈絡:

在本次系列文 「英雄集結:深度學習的魔法使們」 中基本上每個脈絡皆有說明代表性的魔法陣。
傳送門在此:
- [魔法陣系列] Artificial Neural Network (ANN) 之術式解析
- [魔法陣系列] Convolutional Neural Network(CNN)之術式解析
- [魔法陣系列] Recurrent Neural Network(RNN)之術式解析
- [魔法陣系列] AutoEncoder 之術式解析
- [魔法陣系列] Generative Adversarial Network(GAN)之術式解析
先幫有看完這些系列文的你們大力鼓掌!在寫這篇的同時,iT邦幫忙鐵人賽輪播到的激勵語句是:
第一個青春,上帝給的:第二個青春,自己努力。寫鐵人文讓人好青春唷!
也幫自己鼓掌,每天擠時間寫鐵人文章,現在大概老了十歲...(說好的青春呢?)
隨著鐵人賽邁入尾聲,本篇將介紹最後一個魔法陣:Deep Q Network(DQN)。
2015 年 Deepmind 在 Nature 發表了「Human-level Control Through Deep Reinforcement learning」論⽂,內容使用強化學習(Reinforcement learning)和深度學習來教電腦玩 Atari 的遊戲。Deepmind 開啟了所謂的“深度強化學習”的時代,更多的應用大家想必都聽過,就是 AlphaGO,一樣是由 DeepMind 團隊所開發。
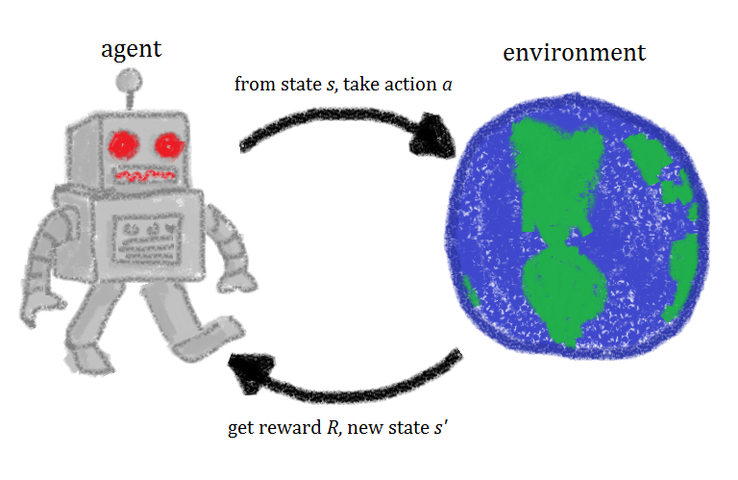
圖片來源:https://simple.wikipedia.org/wiki/Reinforcement_learning
強化學習是一種機器學習,允許創建一個 agent ,藉由與環境的互動來從中學習。就像我們學習如何騎自行車一樣,這種 AI 通過反複試驗來學習。 如圖所示,機器人代表 agent,它作用於環境environment。 每次操作後,代理都會收到反饋。 反饋包括獎勵reward和下一個環境狀態state。 獎勵通常由人來定義。 如果我們使用自行車的類比,我們可以將獎勵定義為距離原始起點的距離。
想知道更多 (又不想看英文的話) ,可以看莫煩大大的教學資源:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/
DeepMind 推出了一種名為 Deep Q Network(DQN)的新算法。它演示了AI代理如何通過觀察屏幕來學習遊戲 有關這些遊戲的先前信息,結果令人印象深刻,影片傳送門:
以下介紹 Deep Q-Networks 魔法陣: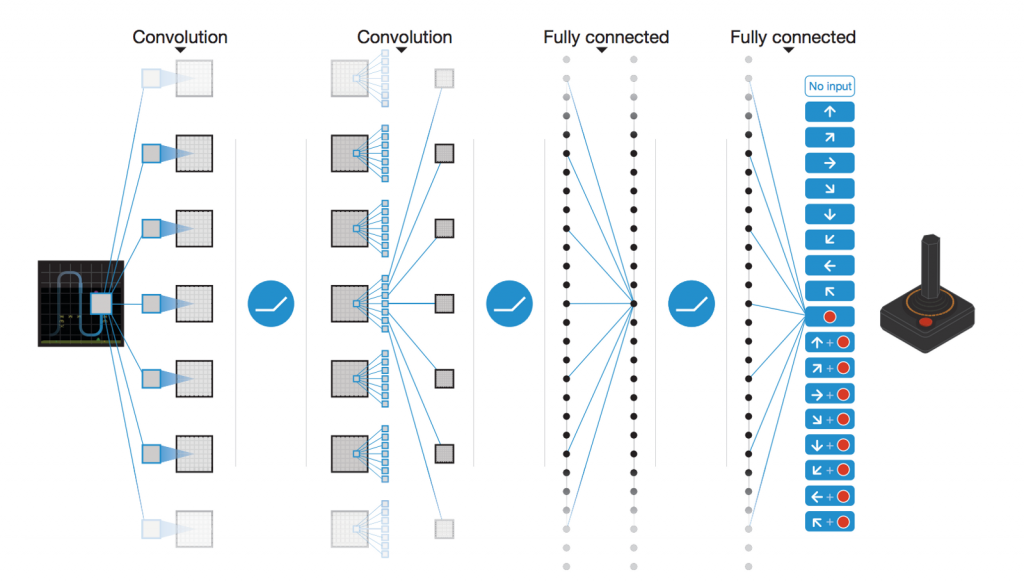
圖片來源:https://medium.com/@awjuliani/simple-reinforcement-learning-with-tensorflow-part-4-deep-q-networks-and-beyond-8438a3e2b8df
DQN 在 Atari 遊戲中,輸入是 Atari 的遊戲畫面,使用 卷積神經網絡(CNN) 來處理 pixel 的資訊。
這邊先說明一下 Q-Learning :是傳統 RL 演算法,在算法中,有一個稱為 Q Function 的函數,用於根據狀態估計獎勵。稱之為 Q(s,a),其中 Q 是一個函數,它從狀態 s 和動作 a 計算預期的未來值。
而在 DQN 中,使用神經網絡代替原本的 Q 值表。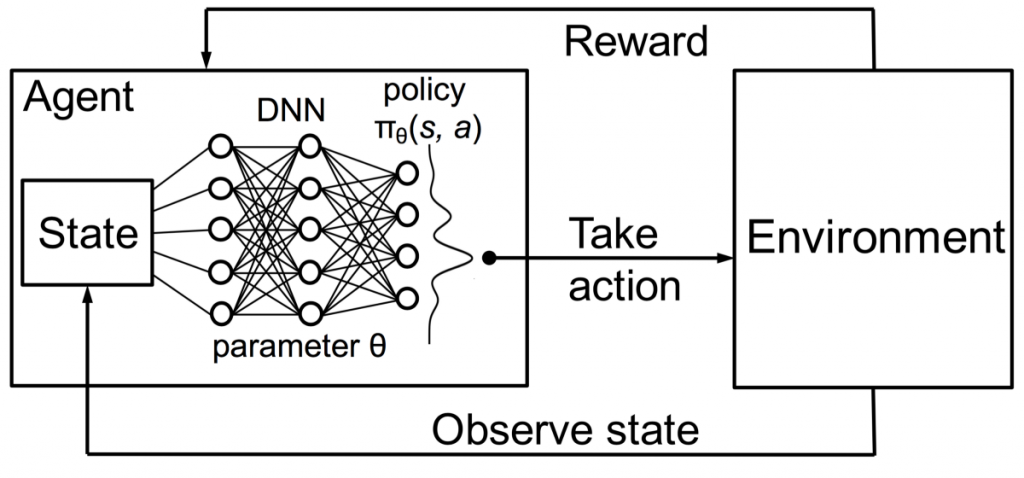
圖片來源:https://towardsdatascience.com/using-deep-q-learning-in-fifa-18-to-perfect-the-art-of-free-kicks-f2e4e979ee66
鑑於環境的狀態state是該網絡的圖像輸入,它會嘗試預測所有可能的操作(如 regression 問題)的預期最終報酬reward,選擇具有最大預測 Q 值的動作作為我們在環境中採取的動作action。
DeepMind 證明,基於深度學習的強化學習系統能夠學習玩 Atari 視頻遊戲,在許多任務中達到人類水平的表現。深度學習也顯著提高了機器人強化學習的性能,帶來許多應用如自動駕駛、減少資料中心能源使用,又或者下面有趣的例子:在 FIFA 18 中使用 DQN 來訓練踢自由球。
本篇就先講到這邊啦~強化學習的內容很龐大,有興趣的同學請再自行深入研究。
突然想玩 FIFA 了。

圖片來源:https://towardsdatascience.com/using-deep-q-learning-in-fifa-18-to-perfect-the-art-of-free-kicks-f2e4e979ee66


 iThome鐵人賽
iThome鐵人賽