在上篇 [魔法小報] 深度學習 vs. 傳統機器學習的文末稍微提到可以用 AutoEncoder 做降維(Dimension Reduction),於是乎,本篇就要來介紹什麼是 AutoEncoder 啦。
AutoEncoder 與它的變形夥伴們: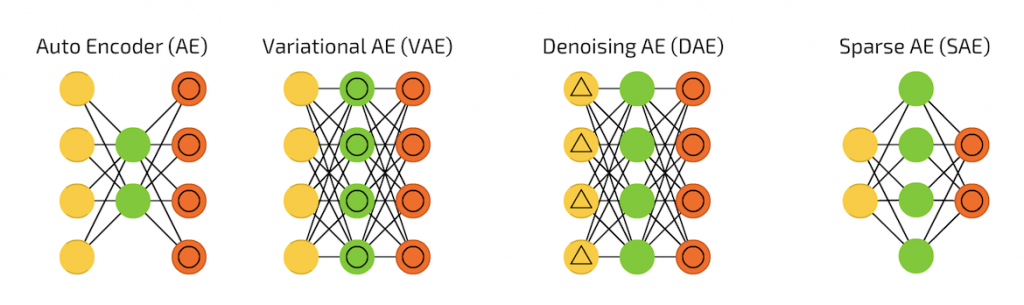
截圖自 [地圖] 深度學習世界的魔法陣們
謎之雷姆:符號的意義可以回去地圖那邊觀看,整篇閱讀完再回去對照此圖的符號意義也是一種複習唷。
AutoEncoder(AE)
AutoEncoder 是多層神經網絡的一種非監督式學習算法,其架構中可細分為 Encoder(編碼器)和 Decoder(解碼器)兩部分,它們分別做壓縮與解壓縮的動作,讓輸出值和輸入值表示相同意義,而這些功能都是用神經網絡來實現,具有相同的 node 數: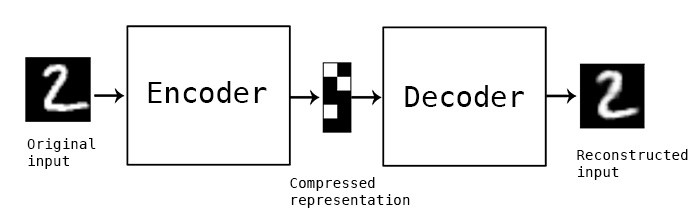
圖片來源:https://blog.keras.io/building-autoencoders-in-keras.html
Variational Autoencoder(VAE)
VAE 是 AutoEncoder 的進階版,結構上也是由 Encoder 和 Decoder 所構成: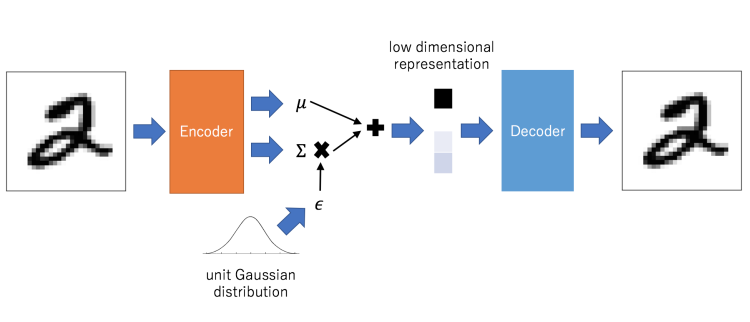
圖片來源:http://mlexplained.com/2017/12/28/an-intuitive-explanation-of-variational-autoencoders-vaes-part-1/
可以看出與 AutoEncoder 不同之處在於 VAE 在編碼過程增加了一些限制,迫使生成的向量遵從高斯分佈。由於高斯分佈可以通過其mean 和 standard deviation 進行參數化,因此 VAE 理論上是可以讓你控制要生成的圖片。
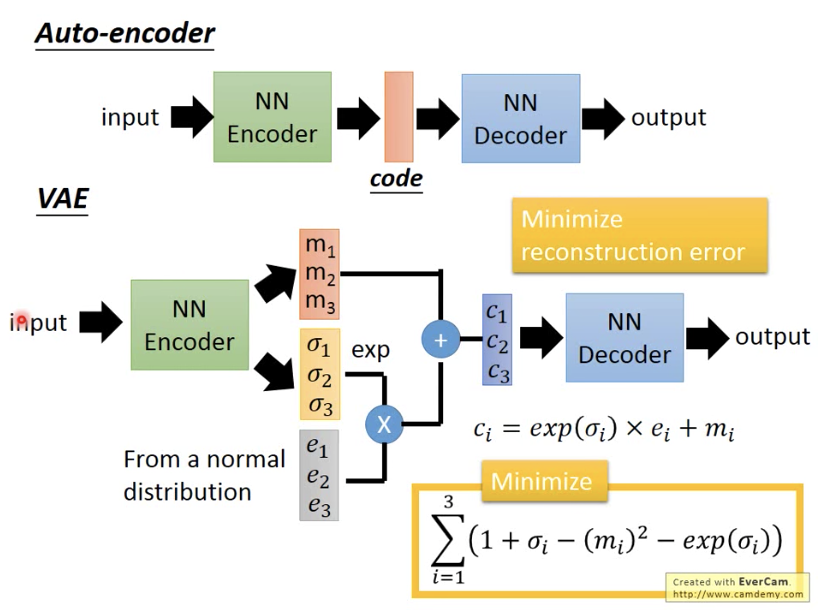
圖片來源:李宏毅老師的 Machine Learning 課程投影片
VAE 的內部做法:
1. 先輸出兩個向量:mean 和 standard deviation
2. 用normal distribution產生第三個向量
3. 把第二個向量做 exponential,之後跟第三個向量做相乘後,把它跟第一個向量相加,即成為中間層的隱含向量
總之,VAE 可以解讀隱含向量中的每一個維度(dimension)分別代表什麼意思,也因此理想上可以調整想要生成的圖片。
Denoising AE(DAE)
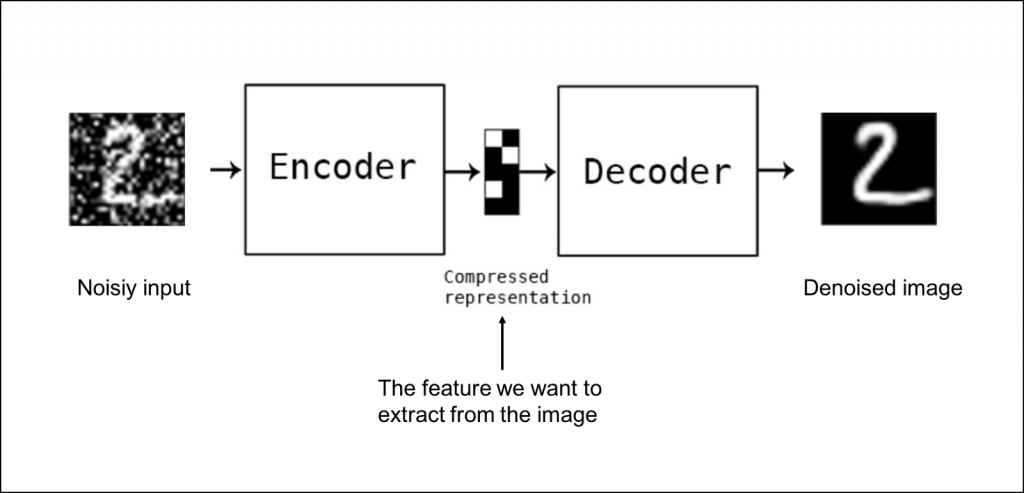
圖片來源:https://blog.sicara.com/keras-tutorial-content-based-image-retrieval-convolutional-denoising-autoencoder-dc91450cc511
Denoising AE 是一種學習對圖片去噪(denoise)的神經網絡,它可用於從類似圖像中提取特徵到訓練集。實際做法是在 input 加入隨機 noise,然後使它回復到原始無噪聲的資料,使模型學會去噪的能力,這就是Denoising AE。
Sparse AE(SAE)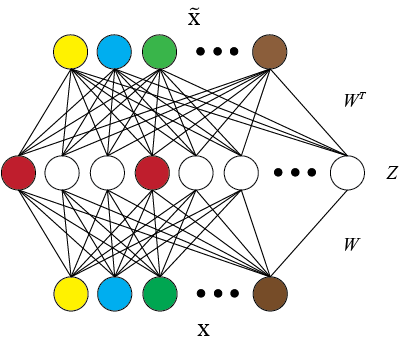
圖片來源:http://www.ericlwilkinson.com/blog/2014/11/19/deep-learning-sparse-autoencoders
Sparse AE 的作法是在 AutoEncoder 基礎上加上 L1 正則化,限制每次得到的 representation 盡量稀疏,迫使自動編碼器將每個輸入表示為少量節點的組合,只有一小部分節點具有非零值,稱為活動節點。
為什麼要盡量稀疏呢?事實上在特徵稀疏的過程裡可以過濾掉無用的訊息,每個神經元都會訓練成辨識某些特定輸入的專家,因此 Sparse AE 可以給出比原始資料更好的特徵描述。
簡言之,Auto-encoder 是欲學習輸入數據的相關性表示的一種方法,可應用在特徵擷取(Feature extraction)、降維(Dimensionality reduction)、生成模型 (Generative models)或非監督式預先訓練。
下一篇將會挑一個 Auto-encoder 或它的變形夥伴們來實作,會很好玩的喔!(應該吧)

雷姆關心您
《Re:從零開始的異世界生活》的雷姆
圖片來源:https://solomo.xinmedia.com/acg/136986


 iThome鐵人賽
iThome鐵人賽