新聞分類到85%精確度就上不去了,再繼續探索nltk
>>> locs = [( 'Omnicom' , 'IN' , 'New York' ),
... ( 'DDB Needham' , 'IN' , 'New York' ),
... ( 'Kaplan Thaler Group' , 'IN' , 'New York' ),
... ( 'BBDO South' , 'IN' , 'Atlanta' ),
... ( 'Georgia-Pacific' , 'IN' , 'Atlanta' )]
>>> query = [e1 for (e1, rel, e2)in locs if e2== 'Atlanta' ]
>>> print (query)
['BBDO South', 'Georgia-Pacific']
每個這種較大的框叫做一個詞塊。就像分詞忽略空白符,詞塊劃分通常選擇詞符的一個子集。同樣像分詞一樣,詞塊劃分器生成的片段在源文本中不能重疊。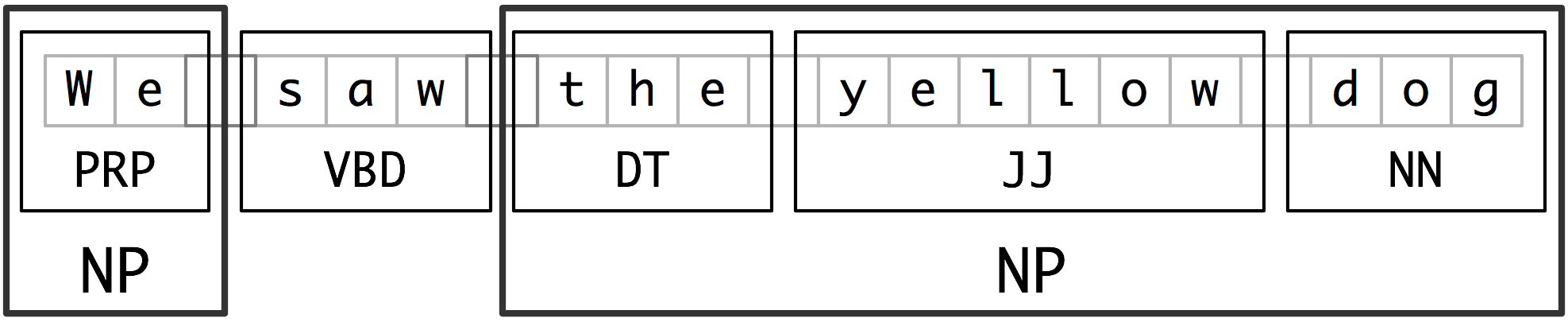
<DT>?<JJ>*<NN>
grammar = r """
NP: {<DT|PP\$>?<JJ>*<NN>} # chunk determiner/possessive, adjectives and noun
{<NNP>+} # chunk sequences of proper nouns
"""
cp = nltk.RegexpParser(grammar)
sentence = [( "Rapunzel" , "NNP" ), ( "let" , "VBD" ), ( "down" , "RP" ), [1]
( "her" , "PP$" ), ( "long" , " JJ" ), ( "golden" , "JJ" ), ( "hair" , "NN" )]
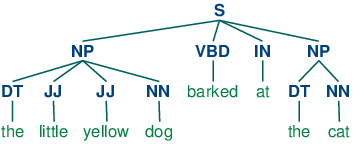
>>> cp = nltk.RegexpParser( 'CHUNK: {<V.*> <TO> <V.*>}' )
>>> brown = nltk.corpus.brown
>>> for sent in brown.tagged_sents() :
... tree = cp.parse(sent)
... for subtree in tree.subtrees():
... if subtree.label() == 'CHUNK' : print (subtree)
[ the/DT little/JJ yellow/JJ dog/NN ] barked/VBD at/IN [ the/DT cat/NN ]
在這個方案中,每個詞符被三個特殊的詞塊標記之一標註,I(內部),O(外部)或B(開始)。
使用corpus模塊,我們可以加載已經標註並使用IOB符號劃分詞塊的《華爾街日報》文本。這個語料庫提供的詞塊類型有NP,VP和PP。
from nltk.corpus import conll2000
>>> from nltk.corpus import conll2000
>>> cp = nltk.RegexpParser( "" )
>>> test_sents = conll2000.chunked_sents( 'test.txt' , chunk_types=[ 'NP' ])
>>> print (cp .evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 43.4%
Precision: 0.0%
Recall: 0.0%
F-Measure: 0.0%
IOB標記準確性表明超過三分之一的詞被標註為O,即沒有在NP詞塊中。然而,由於我們的標註器沒有找到任何詞塊,其精度、召回率和F-度量均為零。
參考資料:
Python 自然语言处理 第二版https://usyiyi.github.io/nlp-py-2e-zh/

