一早 Gavin 開車往公司路上,思索著 Molly 昨天刻意談到的常有成員晚上自動做功課的『非加班』,除了感慨自己運氣一直不錯,有好夥伴協助一路成長。同時也再一次深思這個專案當時訂 兩週一個Sprint是否合宜?也許這類的專案應該要更長的週期才能有足夠的『完成待辦事項』來舉辦 Sprint Review 會議。Gavin想清楚了,就決定就在下個 Sprint Planning 會議前,跟大家商量變成延長為以四週一個Sprint決議案。
關於敏捷開發的迭代週期要定多長,無論是 UP 的 Iteration 還是 Scrum 的 Sprint,Gavin 在軟體開發專案上早已有結論:在現有的軟體或是框架上做加值的,或是客製化的專案,因為需求已經被限制在原框架或功能上,工作量一般比較小,會傾向較短的週期,兩週會比較適宜,也很難再短了,因為要Plan, Review 等等的專案管理所需的時間成本,過短不太合算;如果是全新的專案四週會是較佳的選擇,如果需要創新技術含量高的,他會設置六週為一個迭代,再長一點,經驗來看也不好,很容易頭幾週因為較無時程壓力,人性自動會把工作遞延,結果到了最後兩三週又在加班趕工了,這對長期工作的效率來看,反而是損失。
思考到這裡,他自己苦笑心中有個灰暗心聲:
極端的論調:要榨取知識工作者最後的生產力,可考慮採用敏捷方式
今天是 Moore 要跟大家講 Tensorflow 開發 MLP,不談數學了,Moore 負責『了解(AI視覺)知識或技術』應該可以輕鬆一點吧?
Moore 先跟大家分享自己看一篇文章談到為何參數初始化很重要,他先把印出來的圖片秀給大家看

我們的模型假設是只有兩個特徵值的輸入,以線性迴歸問題來講,對應只有兩個參數,以上圖來說,我們可以假設 x, y 軸代表w1, w2 兩個參數,而z軸就是損失函數了。那可以很清楚了解為何參數初始值設的不好,例如圖裡的最左下方,很可能就永遠不會更新到最佳值,在右下方附近。這當然是虛構的圖示,真實的模型參數很容易是百萬個以上,我們無法畫出來,甚至也無法幻想出它的樣子。
如同昨天 Pete 分析有三個層次,第一個層次數學演算法,有了 Fields 跟大家講解基礎理論就夠了,再深入 Moore 不感興趣,他認為花在更大的力氣在讓訓練所需超參數設定調整上,可能更發揮績效。不打算從無到有寫出模型,所以他選擇 Tensorflow 因為相比 Mxnet 有更多的資源可以用。
有太多論述說明為何選擇 Tensoflow, 這張圖頗有代表性: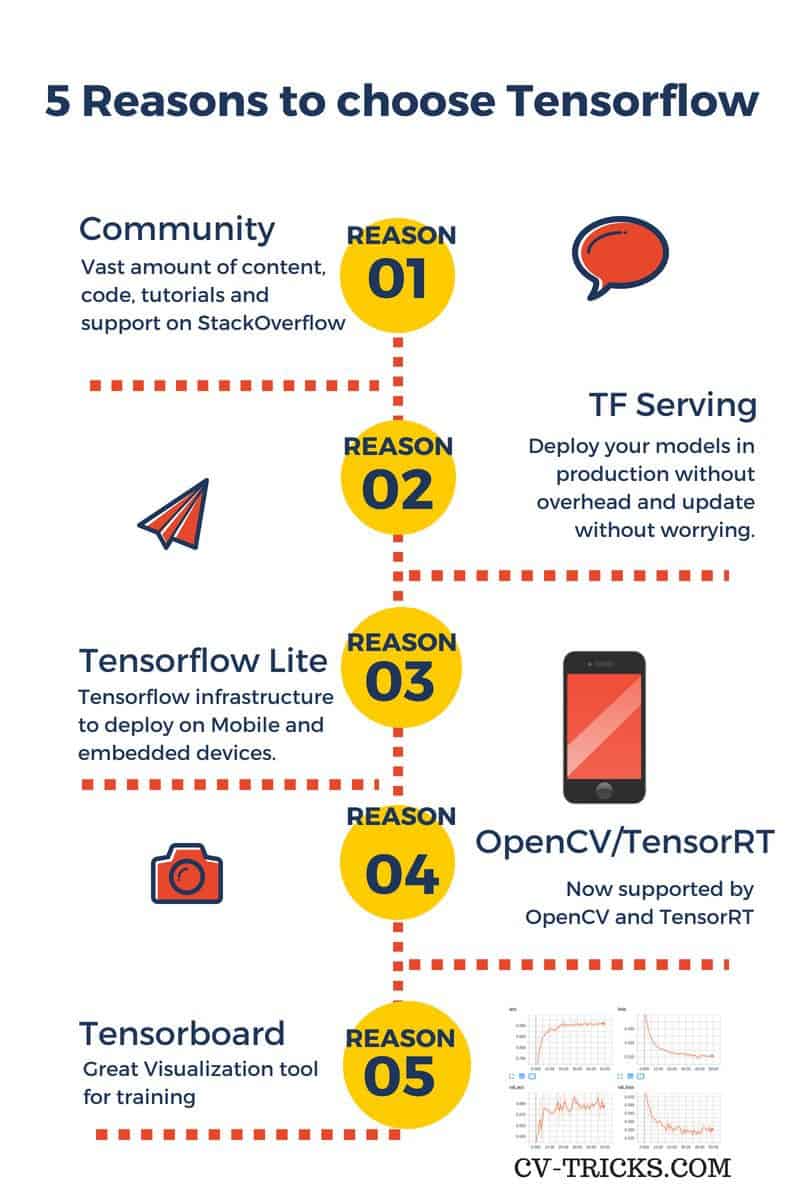
取自 https://cv-tricks.com/deep-learning-2/tensorflow-or-pytorch/
他請大家用Chrome/Firefox 連結到 Google Developer Codelab 關於TensorFlow and deep learning, without a PhD
很生動的圖文講解,前半部多少講解了 Fields 在之前講述了 七篇的數學方程式與演算法,請大家快速瀏覽過,順便複習一下 Fields 的教學。看到圖示這樣風格的教學實在很受 Cash 與 Fields 欣賞。
重點在於中間提到訓練時一些實務上的技巧,關於 overfitting, dropout, learning rate decay 的一些無法用數學證明,但是又有效的加速或提高訓練效率,最後提到 CNN (Convolutional Neural Network) 這個從 MLP 衍化,加上影像的一些特有處理方式(Convolution)作為 Filter 來提取特徵(參數)。這個太多教材,不特別講了。
Moore 請大家用 colab 的資源來做 Tensorflow 的練習,以下需要 Google 帳號來取得計算資源。
import tensorflow as tf
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
init = tf.initialize_all_variables()
對於 Tensorflow 因為採所謂的靜態圖,必須先定義計算圖。
其中有兩種節點類型與 Mxnet 不同的:
placeholder : 置放資料集,不會去更新其值
Variable:參數放於此類型,持續更新用
Y = tf.nn.softmax(tf.matmul(tf.reshape(X, [-1, 784]), W) + b)
Y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(Y_ * tf.log(Y))
is_correct = tf.equal(tf.argmax(Y,1), tf.argmax(Y_,1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
optimizer = tf.train.GradientDescentOptimizer(0.003)
train_step = optimizer.minimize(cross_entropy)
sess = tf.Session()
sess.run(init)
for i in range(1000):
# load batch of images and correct answers
batch_X, batch_Y = mnist.train.next_batch(100)
train_data={X: batch_X, Y_: batch_Y}
# train
sess.run(train_step, feed_dict=train_data)
除了變量還有靜態圖觀念,由於Tensorflow 採所謂的 "deferred execution" 模型,他必須知道你的模型定義,了解執行的資源組態,最後決定如何有效率的執行,最後利用 Session 取得資源後,由 session.run()來投入資料計算。
Fields 嘗試在 colab 的『代碼執行程序』選單選擇了 『更改運行類型』為 GPU,發現執行時間居然比 CPU 費時:再改為傳奇的Machine Learning 計算加速神器 TPU,時間還是更長。與一般刻板印象這些GPU, TPU加速器會讓計算速度加快,他們兩個花費時間更長。
Pete 幫大家查了一下,可以用這樣的程式碼取得哪些計算資源可利用
from tensorflow.python.client import device_lib
local_device_protos = device_lib.list_local_devices()
local_device_protos
下列結果,顯示是 GPU 設備,不過是Nvidia K80 已經是三代前的產品(先在是V,前一代P,前二代M,再來才是 K),速度應該很普通,但是速度比起 CPU 約落後10-20%,實在令人不敢相信,也許是要更大規模的網路才會彰顯它的平行計算優勢。
incarnation: 15244691534819004833
physical_device_desc: "device: XLA_GPU device", name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 11281553818
locality {
bus_id: 1
links {
}
}
incarnation: 15257351585813503532
physical_device_desc: "device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7"]
另外也觀察到了,就算選了 TPU,也只用到 CPU 的設備。原因不明。
專案緣起記錄在 【UP, Scrum 與 AI專案】

