Moore 原預期要講解關於訓練時一些實務上的技巧,諸如 overfitting, dropout, learning rate decay 的一些無法用數學證明,但是又有效的加速或提高訓練效率的超參數設定。另外CNN也是最基本的網路類型,因為大家努力的玩 colab,沒有進展;而原先以為不用花太多時間準備素材的 Sprint Review會議居然讓大家額外花了一天多的時間 …最後只剩兩日排自然語言處理,這些工作只能等待下一個 Sprint 來執行了。
往後一連兩天由 Molly 談自然語言處理的基本概念,這是考量到他們T軟主要客戶群,對這領域已經有個需求,所以基本上把這個當作高優先的技術引入重點。
Molly 先跟大家用幾個問題來解釋自然語言處理 NLP 做什麼,以技術觀點分類:
針對『薑母鴨』這個大家感興趣的話題,Molly 先問大家:
“如果是西藏人要請他分詞,你猜會是『薑母-鴨』還是『薑-母鴨』?”
Pete 趕緊回答:”這當然要先問他們語彙裡有無『薑母』這樣的用語!我猜是沒有,所以他會分成『薑-母鴨』”
Molly 點頭,繼續:
”我們做自然語言,第一件事情是建立語言模型:假設一個句子 ,其中
代表第 i 個單詞或標點符號。我們要表示的語言模型就是建立

這個條件機率就可以藉由單詞發生頻率的計算:
我們常看到文獻 bigram 是指 n = 2;trigram 是指 n = 3。但是這樣做有很多問題,先不談。我們主要是要說明『薑-母鴨』可能對西藏人比較有意義,因為對他們來講可能『薑』接著『母』連在一起的機會是0。
”
除了語言模型是基礎,另外還有一個最基本的問題,如果沒有 word2vec 這類似的『詞嵌入』表示法,在一個語言如果有 30,000 個單詞,我們就得製作一個詞典,對每個詞從0編號到29,999。要表達一個詞就會變成需要用一個30,000個維度的vector,裡面除了第j 個是1,其他是0,j代表該詞在字典從0開始數的位置。以上面的 句子,就必須用 [m x 30,000] 維度的Tensor 來表達。
這個除了會造成計算的困擾,最重要的是每個詞都沒任何關聯, word2vec 可以作到讓用向量表達單詞是可以被計算的。我們藉由一些『非監督學習』輸入幾億句子後訓練,最終的輸出,我們可以用一個實數的向量,長度可以壓縮到300維,甚或更短,就能進行下列的運算:
又例如如果我們要大家猜下面的XY 『日本:東京 = 中國 : XY』,我們幾乎都會猜北京。這個word2vec 也是常被舉的例子。
佳麗馬上想到一個最基本的問題:"每個詞只能有一個向量代表吧?如果一個詞有兩個意義呢?"
Molly:"
佳麗姐每次都問到重點。有這個工具後,對後面的自然語言處理的效率會有很大的提昇。不過,word2vec 這樣的靜態的詞嵌入表達,也有很大的缺陷,就是佳麗談的問題衍生的,例如:

bank 既可以是『河岸』也可以是『銀行』,這種多語意的詞,必須由上下文來定義的word2vec就沒轍。所以又有人發展所謂的 ELMo Deep Contextualized Word Representations。然後又有 OpenAI GPT《Improving Language Understanding by Generative PreTraining》。與GPT 同樣藉由 Google 的 Transformer 技術,最近幾天,Google 又公開了 BERT source code,突然間 BERT 火到不行,因為可以讓多數NLP任務提升到可以與人類競爭。相形之下我幾年前唸書時NLP 應該還是統計模型,準確度基本上還無法商用。
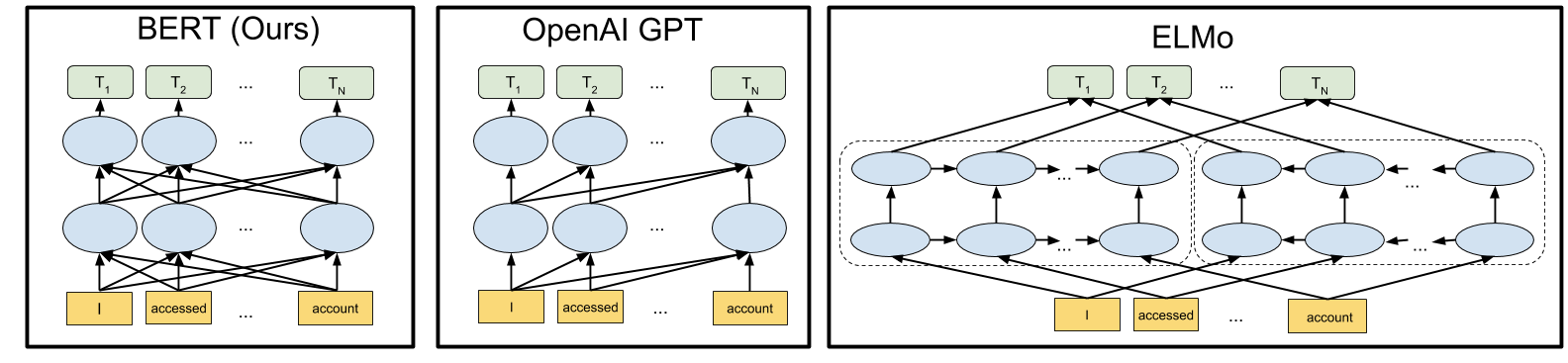
取材自 https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
在今年突然竄起的 BERT與GPT都可以提供預訓練的模型,我們在進行NLP任務,可以引入這些已經完成預訓練的模型,就可以加速訓練,提高準確度,尤其也可以局部解決訓練數據不足的問題。
"
專案緣起記錄在 【UP, Scrum 與 AI專案】




