本篇文章說明TensorFlow-最大池化器( MaxPooling)之原理
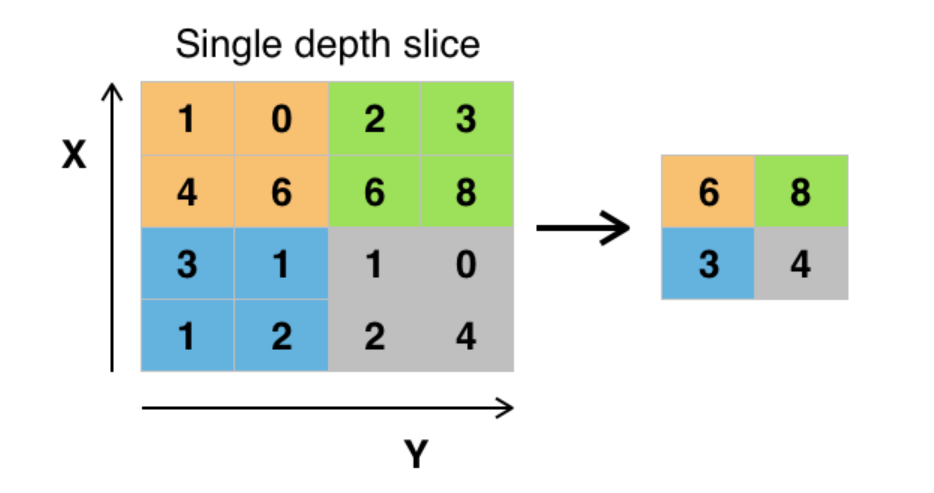
如下圖,用一個 2x2 的矩陣來掃過輸入 (stride = 2),然後在每個紅色區域裡都找那個區域裡最大值當作輸出,就這樣就完成了 down sampling
如下圖是使用2x2濾鏡和步幅為2的最大合併示例。四次2x2顏色表示每次應用濾鏡以找到最大值。
例如,[[1,0],[4,6]]變為6,因為6是該集合中的最大值。 同樣,[[2,3],[6,8]]變為8。
從概念上講,最大池操作的好處是減小輸入的大小,並允許神經網絡只關注最重要的元素。
最大池化通過僅保留每個過濾區域的最大值並刪除其餘值來實現此目的。
TensorFlow提供tf.nn.max_pool()函數以將最大池應用於卷積層。
...
conv_layer = tf.nn.conv2d(input, weight, strides=[1, 2, 2, 1], padding='SAME')
conv_layer = tf.nn.bias_add(conv_layer, bias)
conv_layer = tf.nn.relu(conv_layer)
# Apply Max Pooling
conv_layer = tf.nn.max_pool(
conv_layer,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
tf.nn.max_pool()函數執行最大池化,使用ksize參數作為過濾器的大小,將strides參數作為步幅的長度。
ksize和strides參數組成4元素列表,每個元素對應於輸入張量的維度([批量,高度,寬度,通道])[batch, height, width, channels]。 對於ksize和strides,批次和通道尺寸通常設置為1。

