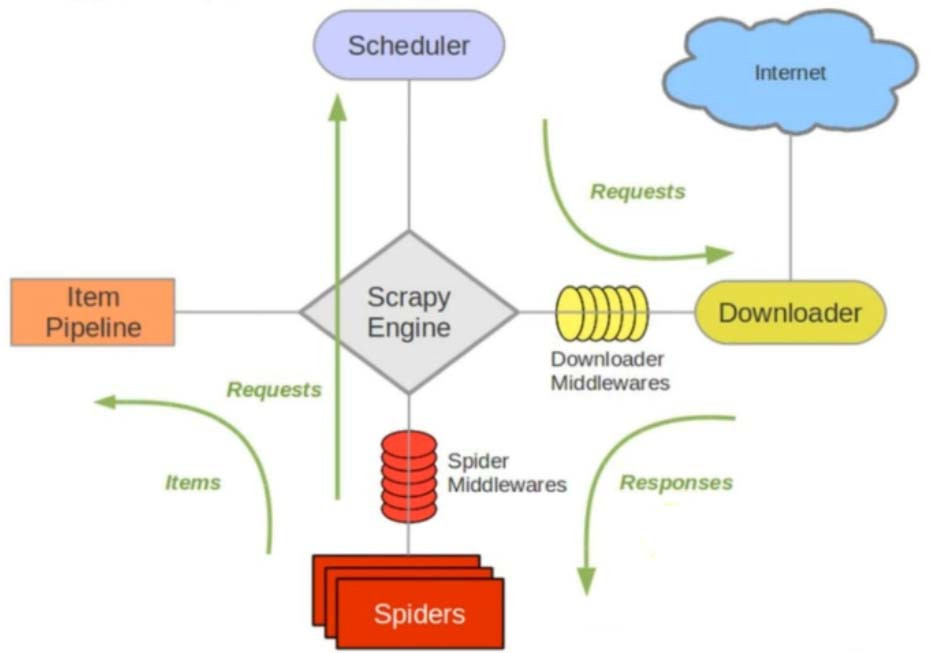
Scrapy框架架構圖
綠色線主要是資料傳遞的方向
Scrapy Engine(引擎):負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊、信號、數據傳遞等
Scheduler(調度器):它負責接受引擎發送過來的Request請求,併案照一定的方式進行整理排列、入隊,當引擎需要時,交還給引擎。
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Request請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理
Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item字段需要的數據,並將需要跟進的URL提交給引擎,再次進入Scheduler(調度器)
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行後期處理(詳細分析、過濾、存儲等)的地方。
Downloader Middlewares(下載中間件):可以當作是一個可以自定義擴展下載功能的組件。
Spider Middlewares(Spider中間件):可以理解為是一個自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses 和從Spider出去的Requests)


 iThome鐵人賽
iThome鐵人賽