程式碼寫好,程序開始運行…
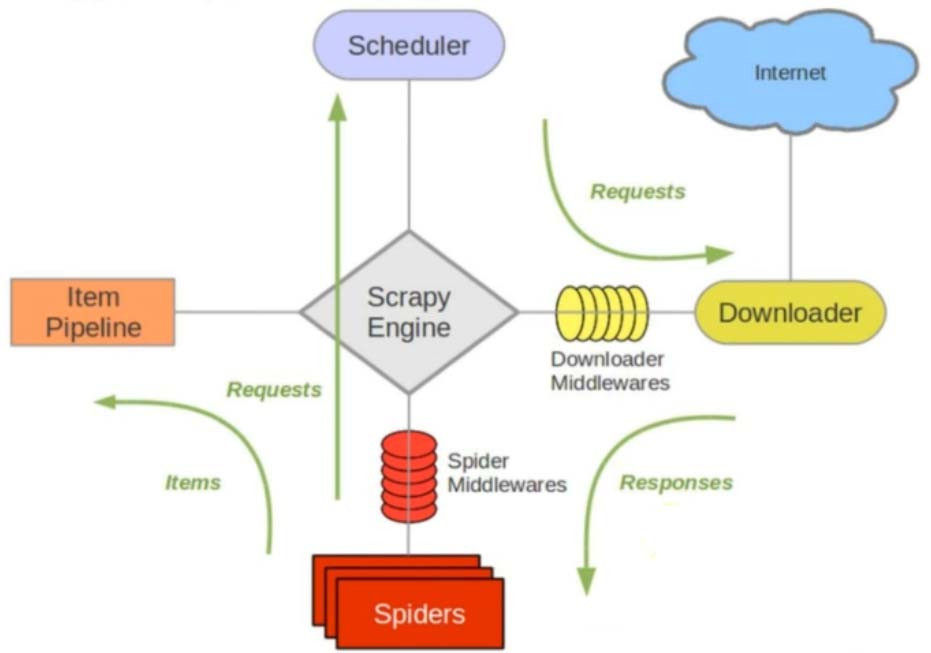
1.引擎:Hi ! Spider,你要處理哪一個網站?
2.Spider:老大要我處理xxx.com。
3.引擎:你把第一個需要處理的URL給我吧。
4.Spider:給你,第一個URL是xxxxxxxx.com。
5.引擎:Hi ! 調度器,我這有Request請求你幫我排序入隊一下。
6.調度器: 好的,正在處理你等一下。
7.引擎:Hi ! 調度器,把你處理好的Request請求給我。
8.調度器:給你,這是我處理好的Request
9.引擎:Hi!下載器,你按照老大的下載中間件的設置幫我下載一下這個Request請求
10.下載器:好的!給你,這是下載好的東西。(如果失敗:sorry,這個Request下載失敗了。然後引擎告訴調度器,這個Request下載失敗了,你紀錄一下,我們待會兒再下載)
11.引擎:Hi!Spider,這是下載好的東西,並且已經按照老大的下載中間件處理過了,你自己處理一下(注意!這裡Responses默認是交給def parse()這個函數處理的)
12.Spider: (處理完畢數據之後對於需要跟進的URL),Hi ! 引擎,我這裡有兩個結果,這個是我需要跟進的URL,還有這個是我獲取到的Item數據。
13.引擎:Hi ! 管道 我這兒有個Item你幫我處理一下 ! 調度器 ! 這是需要跟進URL你幫我處理一下。然後從第四步開始循環,直到獲取完老大需要全部信息。
14.管道調度器:好的,現在就做!
注意! 只有當調度器中不存在任何Request了,整個程序才會停止,(也就是說,對於下載失敗的URL,Scrapy也會重新下載。)

