昨天我們介紹到,機器學習就是要從Data中找一個最好的模型(函式)來判斷、預測新的資料。
首先我們會創造一個函式池子,裡面有好多好多、成千上萬的函式,然後,我們會有一堆訓練資料,這些訓練資料會告訴機器說,一個好的函式它的輸出會長怎麼樣,利用這些訓練資料,機器就可以判斷出這個函式是好還是壞的,但是,只知道函式的好壞還是不夠的,我們要有一個好的演算法去從這個池子裡逼近、撈出最好的函式。(這就是傳說中的訓練拉)
然後然後,我們會丟入一些「新的」資料給最好的函式吃吃看,看看機器有沒有舉一反三的能力,如果有,就成功拉!(這裡就是傳說中的測試)
左邊是訓練(train),在訂定好函式形狀後,投入一大堆的訓練資料,讓機器知道怎麼挑選函式(調整參數),然後再用好的演算法有效率的找出最好的函式。
右邊是測試(test),把車牌john6666丟進最好的函式,來測試是否能夠舉一反三,告訴我們車牌的英文及數字。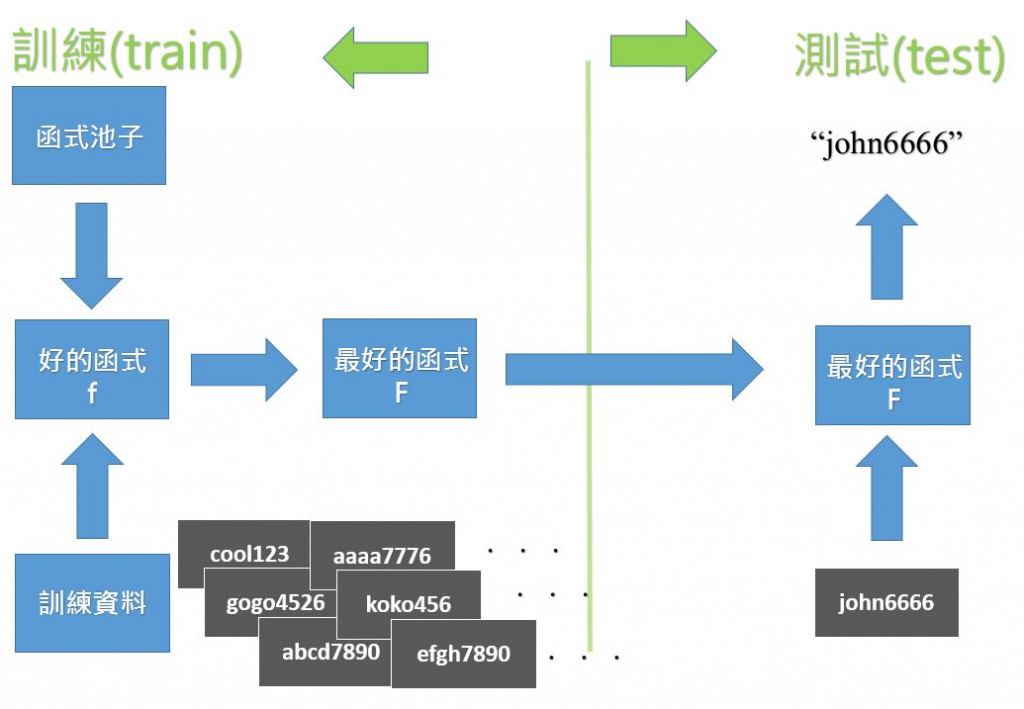
超級簡化的說法就是...
1.監督學習(Supervised learning):由給定的資料中去學習出一個函式,當丟入新的資料時,可以根據模型預測出你要的結果。而這種學習方法最大的特點就是訓練集有標籤還有一開始就訂定好的目標。
啥是標籤啊?標籤其實就是答案,就像上面提到的車牌,一開始在訓練資料理面都會先把每一張車牌照片的檔名打上他的車牌英文,這樣就是標籤!
2.無監督學習(Unsupervised learning):這跟監督學習最大的不同就是訓練資料並沒有人為標註。
3.半監督學習(Semi-supervised learning):介於監督學習和無監督學習。因為人為標註資料很貴又耗時,如果標籤有限,我們可以用沒有標籤的資料增強監督學習。
4.增強學習(Reinforcement learning):機器為了達成目標,會根據環境的改變而調整行為,評估每一個動作後所得到的反饋是正還是負進行改變。
哇!總算壓線闖過第三天了,希望今天的內容大家還喜歡,明天將會開始提到一些相關的數學理論,敬請期待囉~


 iThome鐵人賽
iThome鐵人賽