XGBoost, LightGBM 是當今最當紅, RandomForest, ExtraTrees 也是執行 gradient boosting 很強的工具. 還有一種叫 regularized Greedy Forest, 跑得慢但適合小型資料集分析,
| Model | Library |
|---|---|
| GBDT | XGBoost (dmlc/xgboost), LightGBM (Microsoft/LightGBM), CatBoost (catboost/catboost) |
| RandomForest, ExtraTrees | scikit-learn |
| Others | RGF(baidu/fast_rgf) |
max_depth : 指的是控制樹的深度, 最佳化有可能是 2 或 27, 建議作法是隨著 validation 而加深深度, 過程也要注意新的特徵可被擷取. max_depth 可以從 7 開始, 深度跟學習時間成正比.
max_depth/num_leaves : LightGBM 則是控制葉子數量
subsample、bagging_fraction : 值在 0 與 1 之間, 逐次匯入小部分數據以控制 overfitting 狀況, 這項目比較像正規化的做法
colsample_bytree、colsample_bylevel : 一旦遇到 overfitting 就降低這些參數
min_child_weight,lambda,alpha : 也都是正規化的做法
min_child_weight : 此項是最重要的參數, 增減此項會讓 model 趨近更無拘束/彈性(減)或更沈穩(增), 最佳化的數值在 0, 5, 15, 300.
eta、num_round : 這兩個是配對使用, eta 是學習權重(weight), 就像梯度下降(gradient decent), num_round 則是學習的步驟數量, 隨著迭代建樹, eta 權重會加入 model. 也可以將 eta 固定在極小值 0.1 或 0.01, 然後訓練到 over fits, 藉此知道學習要多少回合. <小秘訣> 將 num_round 乘以 α, eta 則是除以 α, 通常 model 的分數因此迅速上升.
seed : random seed 一般來說對 model 影響不大, 若影響很大, 就試著調整 validation 架構為隨機.
| XGBoost | LightGBM |
|---|---|
| max_depth | max_depth/num_leaves |
| subsample | bagging_fraction |
| colsample_bytree, colsample_bylevel | feature_fraction |
| min_child_weight, lambda, alpha | min_data_in_leaf, lambda_l1, lambda_l2 |
| eta num_round | learning_rate numiterations |
| Others : seed | Others : *_seed |
Others
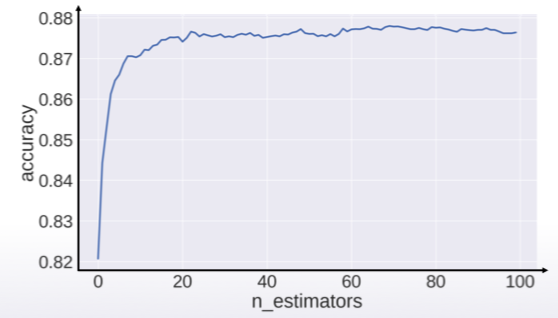
截圖自 Coursera

