| 面向 | 注意事項說明 |
|---|---|
| time seris | 意思是說當我們分成 training 跟 validation 時, training set 是歷史數據, 但 validation 的是未發生的未來數據, 所以 test 也應是未來數據. |
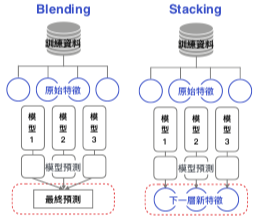
| diversity | 單模很重要, 同時要看考慮 model 多元性, 瑪博強調 you don't need to worry too much to make all the models really strong, stacking can actually extract the juice from each prediction. 弱沒關係, 總之是三個臭皮匠勝過一個諸葛亮. |
| diversity may come from | different algorithm 跟 different input feature |
| performance | 要預期會發生跑到一個點, 再增加堆疊也沒有什麼效果, 雖然沒有限制可以堆疊多少個模型, 而是要回頭看數據內容, feature 跟 fit 的 algorithm |
| meta model | focus 在找到一種將 meta model 組合在一起的方法而不是再去做很深的仔細檢查數據的工作。 |
Created on Mon Sep 23 23:16:44 2017
@author: Marios Michailidis / 作者是瑪博
This is an example that performs stacking to improve mean squared error
This examples uses 2 bases learners (a linear regression and a random forest) and linear regression (again) as a meta learner to achieve the best score.
The initial train data are split in 2 halves to commence the stacking.
# train is the training data
train=[
[0.624,0.583],[0.321,0.016],[0.095,0.285],[0.235,0.573],[0.027,0.146],[0.514,0.06],[0.612,0.083],[0.054,0.597],
[0.344,0.108],[0.671,0.089],[0.486,0.583],[0.829,0.929],[0.451,0.018],[0.448,0.286],[0.26,0.914],[0.893,0.706],
[0.951,0.487],[0.811,0.075],[0.65,0.505],[0.902,0.24],[0.312,0.617],[0.907,0.844],[0.629,0.194],[0.333,0.559],
[0.98,0.983],[0.87,0.706],[0.611,0.623],[0.463,0.097],[0.957,0.507],[0.341,0.792],[0.384,0.482],[0.584,0.655],
[0.446,0.454],[0.314,0.396],[0.061,0.712],[0.951,0.691],[0.71,0.444],[0.238,0.809],[0.943,0.874],[0.325,0.619],
[0.438,0.146],[0.131,0.055],[0.884,0.083],[0.306,0.641],[0.071,0.32],[0.765,0.402],[0.321,0.584],[0.714,0.444],
[0.533,0.811],[0.644,0.293],[0.403,0.579],[0.278,0.577],[0.888,0.902],[0.99,0.182],[0.212,0.072],[0.692,0.386],
[0.919,0.318],[0.082,0.234],[0.99,0.597],[0.867,0.371],[0.158,0.154],[0.304,0.826],[0.088,0.638],[0.382,0.87],
[0.491,0.75],[0.155,0.731],[0.291,0.494],[0.76,0.304],[0.602,0.904],[0.512,0.713],[0.28,0.626],[0.99,0.566],
[0.26,0.613],[0.312,0.561],[0.84,0.695],[0.112,0.245],[0.701,0.479],[0.974,0.103],[0.507,0.188],[0.583,0.586],
[0.965,0.96],[0.112,0.007],[0.018,0.752],[0.063,0.967],[0.456,0.024],[0.214,0.107],[0.086,0.352],[0.892,0.356],
[0.533,0.533],[0.276,0.241],[0.514,0.363],[0.241,0.765],[0.829,0.821],[0.73,0.54],[0.136,0.635],[0.431,0.248],
[0.288,0.259],[0.008,0.663],[0.856,0.954],[0.579,0.972]
]
# y is the target variable for the train data
y=[19.444,4.992,2.11,13.708,0.805,8.619,10.21,11.443,5.624,11.092,17.783,19.544,7.135,7.411,10.633,19.133,23.157,
12.794,18.729,14.939,9.564,19.852,10.028,14.571,22.387,18.742,14.089,8.017,23.241,11.613,14.473,13.893,15.127,
12.062,5.968,19.842,18.636,9.556,21.748,9.319,7.09,2.423,14.594,9.14,6.539,18.883,15.257,18.729,14.114,10.36,
16.359,14.56,19.991,15.411,3.763,17.696,19.243,1.937,26.017,19.858,2.971,10.657,5.808,11.943,13.442,7.663,
13.304,17.375,15.677,13.589,8.728,25.399,8.824,14.796,18.179,2.405,19.424,15.835,8.254,19.661,21.516,1.764,
5.845,8.68,7.262,3.478,7.544,19.942,17.491,4.847,14.444,9.097,18.873,20.894,7.049,7.103,5.038,5.026,20.896,16.037]
# test is the test data
test=[
[0.463,0.496],[0.45,0.365],[0.131,0.283],[0.015,0.827],[0.076,0.302],[0.092,0.356],[0.765,0.039],[0.94,0.767],[0.413,0.343],
[0.484,0.155],[0.464,0.695],[0.574,0.767],[0.81,0.848],[0.888,0.317],[0.802,0.776],[0.197,0.417],[0.076,0.9],[0.071,0.248],
[0.377,0.356],[0.523,0.538],[0.282,0.151],[0.299,0.342],[0.171,0.879],[0.125,0.123],[0.38,0.554],[0.138,0.919],[0.984,0.361],
[0.07,0.95],[0.674,0.511],[0.514,0.808],[0.808,0.83],[0.573,0.622],[0.719,0.961],[0.479,0.144],[0.158,0.708],[0.365,0.306],
[0.704,0.963],[0.959,0.614],[0.36,0.8],[0.937,0.178],[0.412,0.69],[0.145,0.122],[0.386,0.832],[0.419,0.622],[0.908,0.44],
[0.139,0.227],[0.57,0.852],[0.322,0.763],[0.407,0.94],[0.972,0.735],[0.027,0.671],[0.875,0.533],[0.117,0.829],[0.837,0.725],
[0.963,0.674],[0.065,0.641],[0.271,0.693],[0.845,0.423],[0.332,0.341],[0.548,0.883],[0.979,0.094],[0.806,0.249],[0.924,0.513],
[0.564,0.971],[0.768,0.098],[0.258,0.096],[0.365,0.811],[0.241,0.83],[0.636,0.481],[0.583,0.037],[0.408,0.535],[0.147,0.737],
[0.027,0.452],[0.871,0.599],[0.774,0.614],[0.563,0.268],[0.573,0.424],[0.902,0.863],[0.274,0.253],[0.312,0.135],[0.435,0.416],
[0.973,0.094],[0.541,0.022],[0.501,0.773],[0.18,0.936],[0.253,0.042],[0.354,0.242],[0.268,0.671],[0.253,0.382],[0.488,0.956],
[0.081,0.715],[0.786,0.647],[0.813,0.999],[0.967,0.846],[0.3,0.26],[0.06,0.658],[0.366,0.988],[0.397,0.978],[0.535,0.935]
]
# ytest is the target variable for the test data
ytest=[15.828,13.165,2.805,6.464,6.338,7.868,11.866,19.99,12.631,7.707,12.534,14.495,19.236,19.504,17.825,10.311,7.744,1.643,12.255,
17.601,4.874,10.789,9.428,2.327,15.502,8.762,21.087,8.585,19.251,13.568,19.096,13.478,18.991,7.625,7.578,10.835,18.129,19.543,
11.518,15.077,11.418,2.585,12.003,11.192,22.111,2.727,15.859,10.681,13.344,20.361,5.576,23.465,8.48,18.288,20.473,5.871,9.61,
19.963,10.884,15.108,15.787,13.071,23.744,16.452,12.334,4.794,11.67,9.674,18.095,9.58,15.796,7.597,8.211,24.461,16.518,9.306,
16.248,20.532,4.874,5.217,14.104,15.786,8.479,13.659,9.66,4.149,6.156,9.4,10.784,14.966,6.84,16.894,19.311,21.661,5.455,
6.063,13.329,13.911,15.998]
from sklearn.metrics import mean_squared_error # the metric to test
from sklearn.ensemble import RandomForestRegressor #import model
from sklearn.linear_model import LinearRegression #import model
import numpy as np #import numpy for stats
from sklearn.model_selection import train_test_split # split the training data
# train is the training data
# y is the target variable for the train data
# test is the test data
# ytest is the target variable for the test data
#split train data in 2 parts, training and valdiation.
training,valid,ytraining,yvalid = train_test_split(
train,y,test_size=0.5,random_state=2)
#specify models
model1=RandomForestRegressor(random_state=2)
model2=LinearRegression()
#fit models
model1.fit(training,ytraining)
model2.fit(training,ytraining)
#make predictions for validation
preds1=model1.predict(valid)
preds2=model2.predict(valid)
#make predictions for test data
test_preds1=model1.predict(test)
test_preds2=model2.predict(test)
#Form a new dataset for valid and test via stacking the predictions
stacked_predictions=np.column_stack((preds1,preds2))
stacked_test_predictions=np.column_stack((test_preds1,test_preds2))
#specify meta model
meta_model=LinearRegression()
#fit meta model on stacked predictions
meta_model.fit(stacked_predictions,yvalid)
#make predictions on the stacked predictions of the test data
final_predictions=meta_model.predict(stacked_test_predictions)
print ("mean squared error of model 1 ", mean_squared_error(ytest,test_preds1))
print ("mean squared error of model 2 ", mean_squared_error(ytest,test_preds2))
print ("mean squared error of meta model ", mean_squared_error(ytest,final_predictions))
"""
Prints
('mean squared error of model 1 ', 3.2368156824242451)
('mean squared error of model 2 ', 4.5111357598518351)
('mean squared error of meta model ', 2.6495691512424853)
"""
截圖自 AI 100 陳明佑簡報

