Stacknet 定義
- 瑪博(Marios Michailidis)大神級的參賽紀錄, 昨天查還是全世界排名第五名, 根據搜尋到的文章, 瑪博用Java開發了一款集成了各種機器學習演算法的工具包StackNet
- Stacknet 是 stacking 加上運用 meta-modeling 框架組成一個工具包的建模方式, 一般來說訓練是在訓練參數跟特徵(也就是學生), stacknet 的概念是訓練出好老師.
- Stacknet 可伸缩很靈活, 它可以將學習器一層一層地堆砌起來, 同一個 level 內可並行好幾種模型, 形成一個網狀的結構,
為什麼要用 Stacknet? 很複雜耶
面對一些批評, 瑪博舉了實際參賽得勝經驗的兩個例子來說明複雜卻必須使用的原因. 在例子之前, 瑪博有些語重心長.
- 今天被認為昂貴的東西 (ex:GPU )明天可能變得不會這麼貴, 或者在深度學習裡GPU的出現, 速度已提高100倍, 也是時下最流行的。
- 不一定非要建構很深的 ensemble, small ensembles would still really help
- Kaggle 的這些競賽就像是奧運比賽, 表現最好的先進的理論是驅動這個世界的創新
例一
請參考下圖是某次參賽的四層堆疊, 共用了兩種不同的數據來源, 生成了多個模型. 通常是 XGboost 和 logistic regression ,然後將它們饋入四層體系架構以獲得最高分, 儘管可不用到第四層, 但仍然需要有第三層才能獲勝. 因此可了解部署深度堆疊真的有用。
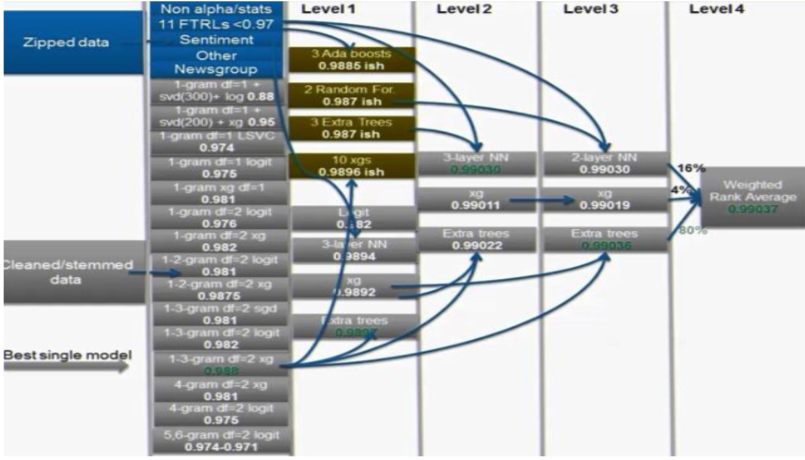
截圖自Coursera
例二
請參考下圖是 Homesite insurance 的競賽, 用了很多很多 model, 也試了 EDA 各種方法來觀察 data, 最後將這些 model 餵進三層體系架構的 stacknet, 跟前例一樣的, 或許不需要部署到三層, 但是深層的架構的確是這兩次競賽致勝關鍵.
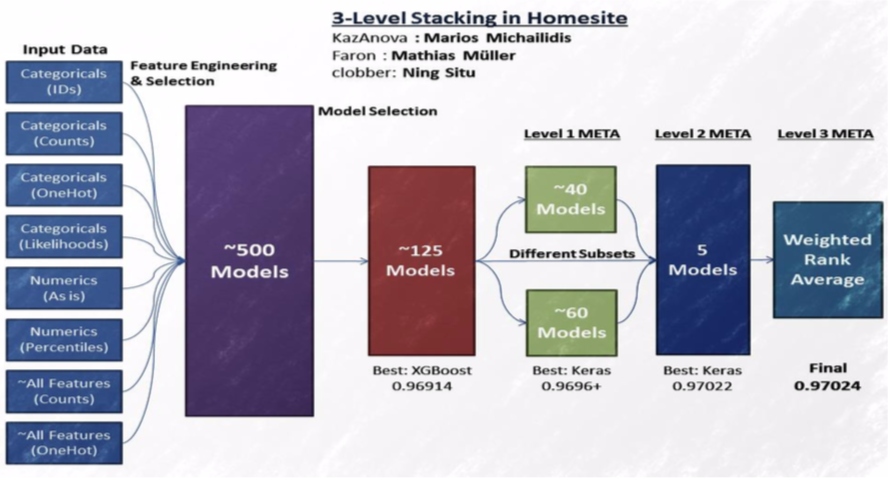
截圖自Coursera
如何進行 Stacknet, how to train
concept
- we can not use BP (bi-propagation / 雙向傳播), BP 是典型 NN 使用的.
- we use stacking, 輸出的節點與目標值鏈結
- to extend many levels, we can use a k=fold paradign
- no epochs - different connections instead.
步驟說明
圖1. 數據分成 training data 跟 valid data

截圖自Coursera
圖2. valid data 再分成 minin train 跟 mini volid

截圖自Coursera
圖3. 進行 K-fold (可參考 day13), 這邊折 4 折, 所以 K=4, 第一折的圖示
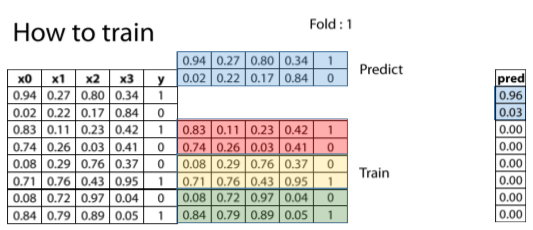
截圖自Coursera
圖4. 第二折的圖示
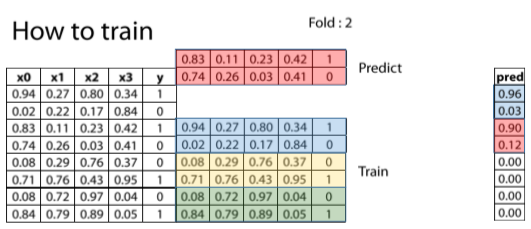
截圖自Coursera
圖5. 第三折的圖示
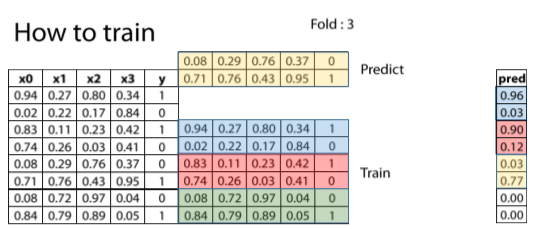
截圖自Coursera
圖6. 第四折的圖示
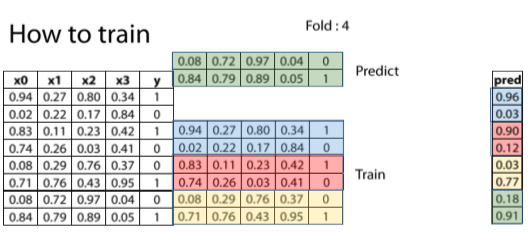
截圖自Coursera
圖7. 最後將所有 data (反灰) 一次餵進 model 跑 test data. 所以有 5 個預測 model, 這時可以用本次結果堆疊, 再來一次 K-fold.
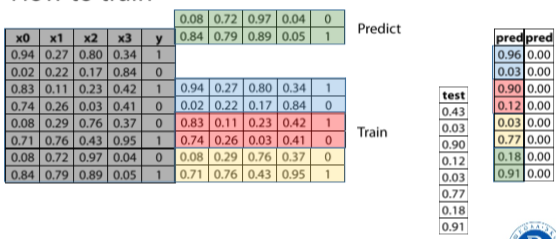
截圖自Coursera
另用 NN 說明
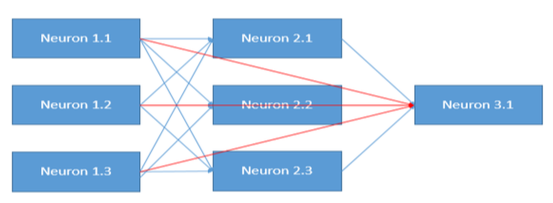
截圖自Coursera
非 coursera 課堂的其他補充注意的事項
- 「分類問題」的 Stacking 要注意兩兩件事:記得加上 use_probas=True(輸出特徵才會是機率值), 輸出的總特徵數會是:模型數量量 * 分類數量量(回歸問題特徵數=模型數量量).
摘自 AI 100 陳明佑簡報
瑪博(Marios Michailidis)大神級秘訣分享 / Ensembling Tips and Tricks
https://www.coursera.org/learn/competitive-data-science/lecture/XqLc1/ensembling-tips-and-tricks
1st level tips
Diversity based on algorithms:
- 2-3 gradient boosted trees (lightgbm, xgboost, H2O, catboost)
- 2-3 Neural nets (keras, pytorch)
- 1-2 ExtraTrees/RandomForest (sklearn)
- 1-2 linear models as in logistic/ridge regression, linear svm (sklearn)
- 1-2 knn models (sklearn)
- 1 Factorization machine (libfm)
- 1 svm with nonlinear kernel(like RBF) if size/memory allows (sklearn)
Diversity based on input data:
- Categorical features: One hot, label encoding, target encoding, likelihood encoding, frequency or counts
- Numerical features: outliers, binning, derivatives, percentiles, scaling
- Interactions: col1 * / + - col2, groupby, unsupervised
Subsequent level tips
Simpler (or shallower) Algorithms:
- gradient boosted trees with small depth(like 2 or 3)
- Linear models with high regularization
- Extra Trees
- Shallow networks (as in 1 hidden layer)
- knn with BrayCurtis Distance
- Brute forcing a search for best linear weights based on cv
Feature engineering:
- pairwise differences between meta features
- row-wise statistics like averages or stds
- Standard feature selection techniques
For every 7.5 models in previous level we add 1 in meta
Be mindful to target leakage
瑪博語重心長的最後 5 個叮嚀
- Go out there, apply what you've learned. Choose a competition. 快去參加個競賽
- Don't be demoralized if you see there's still a gap with the top people, because it does take some time to adjust. You need to learn the dynamics. 別因為跟高手差很多就洩氣, 有時就需要多點時間
- Something that has always helped me is to save my code, and try and improve it. 把寫過的 code 存起來, 想辦法改善, 然後下次競賽就會讓自己表現更好, 更強
- seek collaborations. 參與協作, 每個人觀點不同, 可以彼此補強
- need to be connected with forums, and codes, and kernels.. 不能不閱讀就進步, 要持續學習, 閱讀
補充資料及連結
Kaggle ensembling guide at MLWave.com (overview of approaches)
https://mlwave.com/kaggle-ensembling-guide/
StackNet — a computational, scalable and analytical meta modelling framework (by KazAnova)
https://github.com/kaz-Anova/StackNet
Heamy — a set of useful tools for competitive data science (including ensembling)
https://github.com/rushter/heamy
Stacked ensembles from H2O
Xcessiv
https://github.com/reiinakano/xcessiv
[後記]
平均每天 3 小時備文發文, 總共 90 小時. 挑戰是在於每天持續這件事, 因為生活中太多不可控, 公司臨時趕報告加班, 故意不繳第四台免分心, 卻錯過 GOT 在艾美獎得獎搶盡風頭(對不起龍后, 對不起 Jon Snow), 還有生統作業要改用 R 跑資料(被催繳中), 綠超夢也沒能去追..
明天就是 day 30, 實現對自己的連續 30天發文, 跟隨世界級高手們學習, 雖然也要克服各式腔調英文, 謝謝 ithome ! Awsome !!

