由各個課程講師提供參賽各階段的心法
1. 選擇比賽, 瞭解 Kaggle 的類別 --- 作者自己整理
2. Before you enter a competition --- Alexander Guschin
3. Data loading --- Dmitry Altukhov
4. Performance evaluation --- Dmitry Altukhov
5. Initial pipeline --- Mikhail Trofimov
6. Best Practices from Software Development --- Mikhail Trofimov
7. Code organization --- Dmitry Ulyanov
1. 選擇想要參加的比賽, 先瞭解 Kaggle 的類別
Kaggle Blog 會有得勝者及一些大神的專訪, 可以參考有興趣類別的成功經驗.
| 類別 |
說明 |
| Featured |
來自企業界的題目, 像目前有 Lyft |
| Research |
來自學術機構或者是較為學術面研究的問題 |
| Recruitment |
reward 是面試機會, 或就業博覽會與合作企業的直達應徵機會 |
| Getting started |
提供給剛起步的, 像 titanic 資料集 |
| Masters |
顧名思義, 大師級競賽, 採邀請制, 沒開放報名 |
| Playground |
公開資料集或生活相關有趣的 |
| Analytics |
深入分析的較高層次題目, 例如洛杉磯就業, NFL球員安全 |
2. Before you enter a competition
- Importance. 整理並排序參數, 從最重要到最無用的, 會跟 data structure, target, metric 有關.
- Feasibility. 評估最容易調的參數到那種要調到天荒地老的
- Understanding. 評估從自己最了解到完全不瞭解的參數, 因為不管接下來要增加特徵或改變占比比率, 或 CNN 的階層數量, 理解並掌握參數的狀況是很有用的 (changing one parameter can affect the whole pipeline)
3. Data loading
- 基本格式處理, labeling, coding, category recovery, 然後將 csv/txt files 轉成 hdf5/npy 以加速上傳/下載時間 (hdf5 for pandas, npy for non-bit arrays).
- 因為 Pandas 預設 64-bit 陣列儲存, 其實不必要, 可以轉成 32 位元以節省記憶體資源
- Large datasets can be processed in chunks - 數據集大的可以切塊, Pandas 可以支援將資料即時連接起來, 不然跑一次大筆完整資料就又要等到天荒地老.
4. Performance evaluation
- 不一定每次都要用到 cross validation, 有時基本作法切成 train/test 就足夠
- Start with fastest models - 這邊是推薦用 LightGBM 去找到好特徵跟快速評估特徵的表現, early stoping 是在這時 (初期)可以採用的, 只有在特徵工程後才會調整模, 用 stacking, NN..等
截圖自 Coursera
- Fast and dirty always better - 意思是專注在最重要的, 就是探索資料本身, 用 EDA 去挖掘不同的特徵, 找出產業或該項專業的 domain-specific knowledge, 語法在此刻是次重要事項. EDA 很重要 !!! 如果一直處於很擔心電腦資源跑不動, 就去租伺服器吧
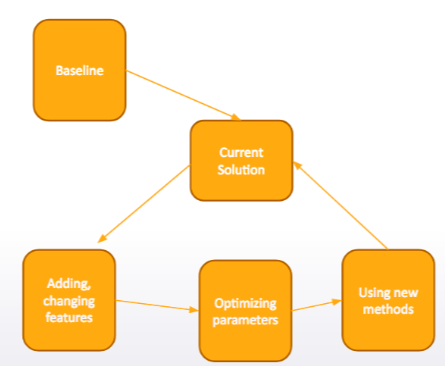
5. Initial pipeline
- 從簡單甚至原始的解決方案開始
- 建構自己的 pipeline, 重點不是建模而是解決方案的整體架構設計, 包括初期資料處理, 預測結果的檔案格式寄送, 在競賽資料的 kernel 或 organizer 提供的, 都可以找到 baseline 解決方案
- “From simple to complex” : 從簡單到複雜, 寧願從 Random Forest 開始, 而不是 Gradient Boosted Decision Trees, 再一步步到比較複雜的方法.
6. Best Practices from Software Development
- Use good variable names : 使用好的變數名字, 不然到最後自己也搞混
- Keep your research reproducible / 保持所有東西都可重製. 包括 : Fix random seed ; 寫下所有特徵生成的過程 ; 使用版控 (VCS, for example, git)
- Reuse code / 使用同樣的程式碼, 特別在 train/test 要使用相同程式碼, 前後才能一致, 因此建議另外存起來.
- Read papers : (1) 可以技術方面的專業知識, 例如 how to optimize AUC; (2) 可以了解問題本質, 尤其在幫助找到特徵, 例如微軟的手機競賽, 就是讀了手機相關 papaer 才可以增加跟找到好特徵.
7. Code organization:
- keeping it clean
- test/val
- macros
- custom library
keeping it clean
- 結果要能複製, 程式碼就要整齊收好, 才不會辛苦半天居然複製不出已經完成的, 重新來很磨人. 盡量不要覆蓋, 而是當要修改時複製到新的筆記本再改
- 不要把新, 舊所有的 code 擠在同一個 notebook, 參數不變的情況下容易有 bug
- 每個新的 submission 就開新的 notebook (use git)
test/val
- 競賽提供的 training 跟 test 的 dataset, 存在本機檔案與當初競賽下載來的格式保持一致
train = pd.read_csv('data/train.csv')
test = pd.read_csv(/data/test.csv)
from sklearn.model_selection import train_test_split
# train set into new train and validation
train_train, train_val = train_test_split(train, random_state=660)
# save to disk
train_train.to_csv('data/val/train.csv')
train_val.to_csv('data/val/val.csv')
- 在 notebook 最上面, 置頂放的是 train/test 的路徑, 方便在轉換成原競賽檔案train/test 後 submission 隨時取用
train_path = 'data/val/train.csv'
test_path = 'data/val/val.csv'
- To retrain models on the whole dataset and get predictions for test set just change. 改個路徑就可用了
train_path = 'data/train.csv'
test_path = 'data/test.csv'
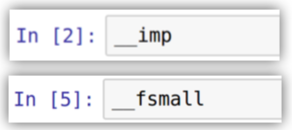
use macros for a frequent code : 狄哥覺得每次 import numpy..蠻麻煩的, 只要幾個簡單的符號敲打出 macro 名, 就可以使用 macro, 很便利
use a library with frequent operations implemented – Out-of-fold predictions : 自建常用的函式庫, 建模的 training code, 可以節省找尋跟呼叫的時間, 請參考下列例子.
– Averaging
– I can specify a classifier by it’s name
param = {
'C' : 1.2,
}
res = trylib(train_2lv, y_train,
'lsvc', param,
one = False, skf_seed = 660, skf = 4,
test_mode='whole', x_test=test_2lv.res
狄哥 (Dmitry Ulyanov) 的 pipeline 分享 (一字不漏)
| 步驟 |
說明 |
| Read forums and examine kernels first |
There are always discussions happening! |
| Start with EDA and a baseline |
(1) To make sure the data is loaded correctly; (2) To check if validation is stable |
| I add features in bulks |
(1) At start I create all the features I can make up; (2) I evaluate many features at once (not “add one and evaluate”) |
| Hyperparameters optimization |
(1) First find the parameters to overfit train dataset; (2) And then try to trim model |
補充資料及連結
Far0n's framework for Kaggle competitions "kaggletils"
https://github.com/Far0n/kaggletils
28 Jupyter Notebook tips, tricks and shortcuts
https://www.dataquest.io/blog/jupyter-notebook-tips-tricks-shortcuts/

