
在說明Deep Neural Nework,我們簡單的討論一下DL介紹。從最早DL從Perceptron開始,Perceptron是只有一個neural,其實就像是一個Logestic regression那樣,但實驗結果認為複雜度不夠高。導致不能做更複雜的case。因此大家開始將Perceptron疊在一起,就有了Multi-layer perceptron,很接近現在的DNN。後來Backpropagation也發展出來,但起初大家在使用的時候,都認為1 hidden layer is engough,三層以上是完全沒有幫助。直到RBM(Restricted boltzman machine)針對DL initailize才有一些breakthrough。直到GPU以及新的activation function等等的發明,才讓Deep learning又回到大家的懷抱裡。口袋深度決定,DL train的長度
以一個NN來說,會有input layer,hidden layer以及output layer。而一般來說,hidden layer就看你要疊幾層。如果我們再細一點去看,就是以一個Neural為單位。其中,Neural會被前一層多個Neural所連接,而output前會先經過activation function,確認這個Neural 是否開啟或者有值等等。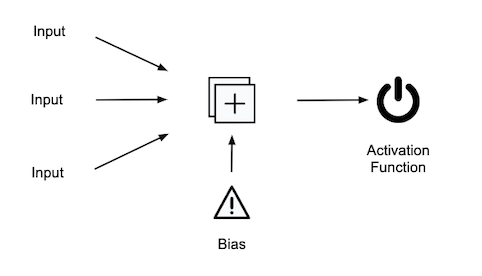
Neuron
Actvation function
過去不管在使用perceptron或NN主要都是以sigmoid function做為Activation function。而Sigmoid function有被發現當Model層數非常深的時候,會造成Gradient Vanishing。主要是跟他的function特性有關,當你的gradient不管多大,都會被壓縮在 0 ~ 1之前,因此當 0.8 * 0.8 * .... 一直乘下去就會導致數值非常小。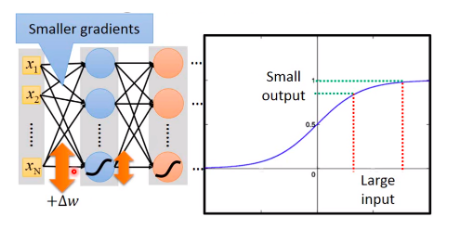
Gradient Vanishing (李教授課程)
因此,Relu孕育而生,而Relu運算很簡單,就是直接ouput本身gradient值,若小於0則output 0。Relu有被研究可降低Gradient Vanishing且運算又快。但缺點就是可能會造成網路稀疏,導致overfit (很有可能多個點Gradient為0)。因此也有一些研究改善Relu,並可被使用的activation function (Ex: Leaky Relu, PReLU ...等)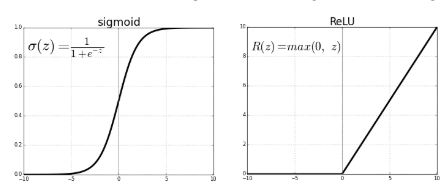
接下來我們來看整個網路流程。
首先會先Feed forward,將資料input,計算weight 跟 bias並經過activation function。以這樣的方式經過各層hidden layer。一般來說,會跑一個Fully Connected 的 Network,因此,各個Neural之間都會完全連結。而在計算過程,可以直接使用Matrix來做運算,Ex: activation_function(W@X+b)。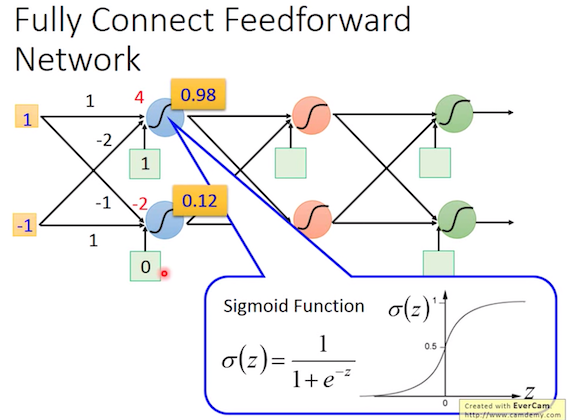
Neural運算 (李教授課程)
經過Hidden layer後,會到最後的Output階段,一般來說會通過一個Softmax fuction,output Multi-class的confidence值,最高值則為預測的class。預測完後,會需要一個loss function來決定預測的好壞。而loss function有非常多種可以嘗試,一般來說,Multi-class的會選擇cross-entropy,binary-class 就會選擇binary cross entropy。此外,您也可以找一些有特定任務的loss (Ex: 資料不平衡下的focal loss等)。透過Minimize loss,就會使用前面的Gradient Descent,做Backprogation,簡單來說就是透過,loss來更新整個neural的參數,完成整個learning process。
在想DNN的測試資料時,剛好在kaggle上發現一個有趣的data - airbnb的open data,因此,會使用Airbnb的data來應用於DNN預測房價。
首先是資料的話份,若大家有興趣可以參考這個連結,這個連結會教你如何直接透過Colab串到Kaggle下載資料集,若過程有疑問的話可以留言詢問。這個資料集的特徵包含像是:房型、reviews數、所在地、經緯度等等。
這個範例會簡單的利用TF.keras的api來實作DNN,被用來預測價格,可運用場景例如當有房型等等資料,我們可以推薦房子訂價或者當房子的review數或者可居住日期拉長等等的調整時,房價該如何調整,類似一個smart pricing的概念。
這邊會直接使用分析師最常使用的pandas來讀取資料
ny_ab = pd.read_csv('AB_NYC_2019.csv')
ny_ab.head()
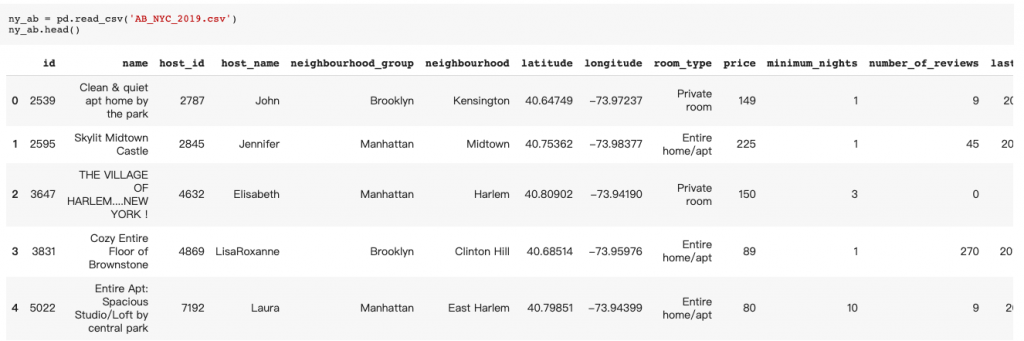
接著可以做一些資料前處理,Ex:濾除不要的column或者補遺漏值
ny_ab.drop(['host_name','name','latitude','longitude','last_review','id','host_id'], axis=1, inplace=True)
ny_ab['reviews_per_month'] = ny_ab['reviews_per_month'].fillna(0)
針對類別型資料(Categorical data),要轉乘one-hot encode才能被使用於模型。
categorical_features = ny_ab.select_dtypes(include=['object'])
categorical_features_one_hot = pd.get_dummies(categorical_features)
categorical_features_one_hot.head()

而像是數值型的資料,就要標準化。而為甚麼要標準化,除了train比較快,就是因為當你的feature在不同的scale上,gradient descent會較難收斂。標準化的方法有很多,常用的像是Max-Min或者Normalize(Z transform)等。
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(ny_ab[ny_ab.columns[ny_ab.columns.str.contains('price')==False]])
ny_ab[ny_ab.columns[ny_ab.columns.str.contains('price')==False]] = x_scaled
這邊的話,我們先用最簡單的train-test split,之後有機會會提到Cross-validation方法。CV是較為嚴謹的模型測試方法(Ex: 10-Fold, 5-Fold)。
X_train, X_test, y_train, y_test = train_test_split(ny_ab[ny_ab.columns[ny_ab.columns.str.contains('price')==False]] , ny_ab['price'] , test_size=0.1, random_state=66)
Model的部分,我們可以直接定義成如下,而因為我們預測的是價格,因此,跟常看到的cross_entropy不太一樣,會使用MSE、MAE等方法:
model = tf.keras.Sequential([
tf.keras.layers.Dense(256,activation=tf.nn.relu),
tf.keras.layers.Dense(128,activation=tf.nn.relu),
tf.keras.layers.Dense(64,activation=tf.nn.relu),
tf.keras.layers.Dense(32,activation=tf.nn.relu),
tf.keras.layers.Dense(16,activation=tf.nn.relu),
tf.keras.layers.Dense(1,activation=tf.nn.relu)
])
model.compile(optimizer='adam',
loss='mean_squared_error',
metrics=['mean_squared_error'])
history = model.fit(X_train.values ,y_train.values, epochs=100, validation_split = 0.1)
因此,可以把train跟val的圖畫成坡降圖觀察train的效果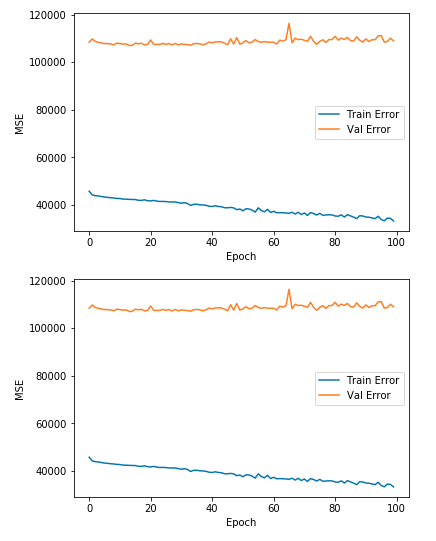
今天把DNN簡單地跑過一遍,明天會說明更進階的用法或者說更貼近TF的用法,也會使用不同的data,讓大家可以在較熟的應用下交流。今天用一個貼近一般Python使用者從Pandas到TF。大家看完程式應該會覺得TF真的很簡單易用。不用像以前還要寫sess.run,且跟python其它套件也整得越來越好。這次範例,仍可多找一些有效的feature或者tune model,在kaggle也有許多kernel在分析這個data,若大家有興趣也可以參考那個data下的kernel。
一天一梗圖:
source
按照上面的程式碼卻出現
could not convert string to float: 'Brooklyn'
請問是為什麼呢
