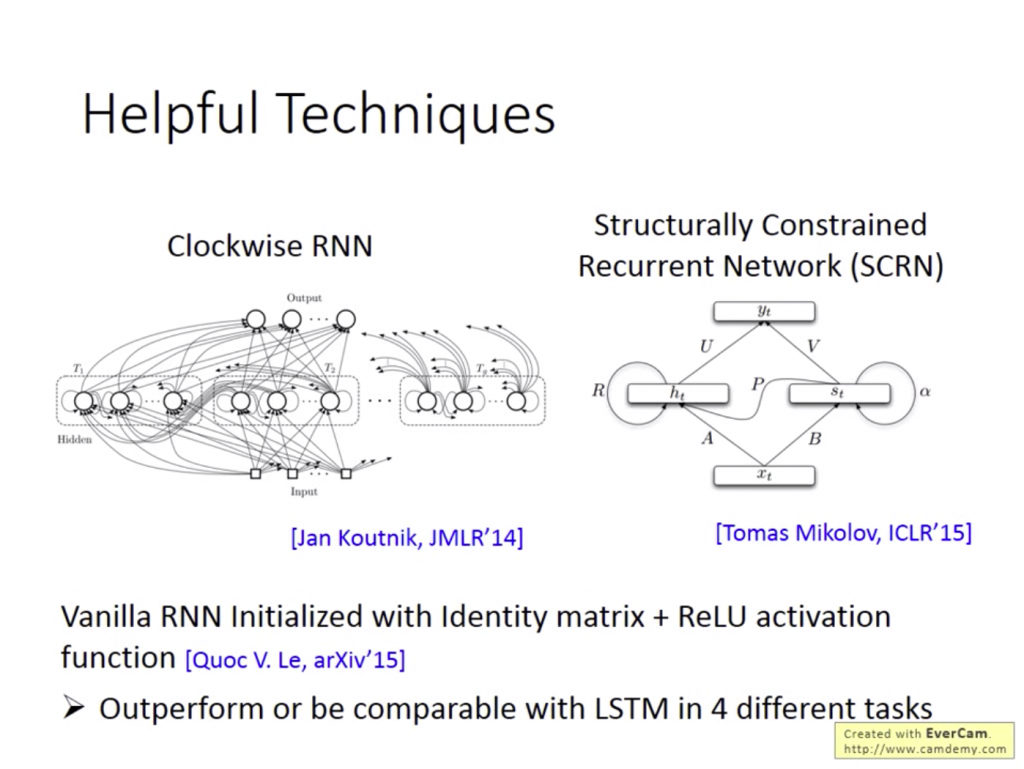
如果出現Gradient Vanishing的問題,就可以使用之前提到的LSTM來解決。
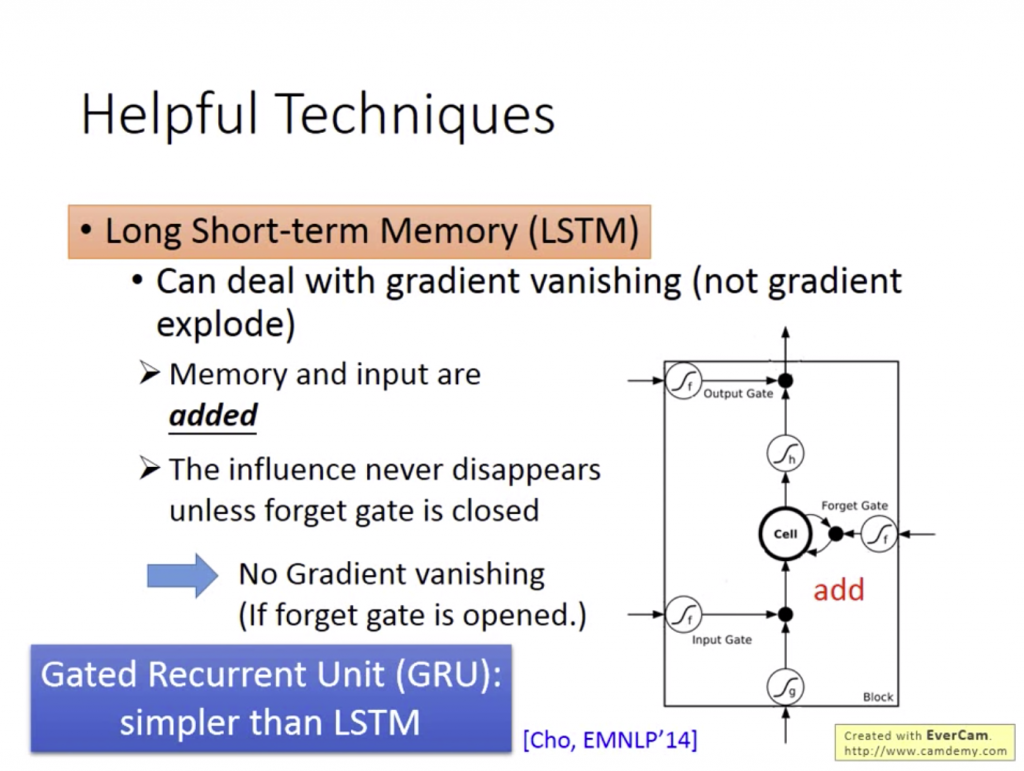
LSTM之所以可以解決Gradient Vanishing,是因為在處理memory時,除非因為forget gate關掉把memory的值洗掉(多數情況不會),否則都會將memory乘上forget gate的值加上input,不會像原本的RNN在每一個時間點將memory重新洗掉。
但即使如此,LSTM因為參數太多的關係還是太難訓練。當訓練結果不佳時,可以使用和LSTM相似但使用的gate參數可以少1/3的模型:
GRU是LSTM的改造版,當我們在存取memory時,還會和input加起來在傳遞到output gate中。GRU認為forget gate和input gate兩個東西的權重當一邊大時,另一邊就會相對小,反之亦然。所以將forget gate和input gate的參數合併成一個,會得到比較高的performance。