簡單回顧
在ML_Day10(Gradient Descent)有介紹什麼是SGD,就是只對一個example的loss做計算,求梯度最小值。也介紹什麼是Adagrad,就是每次更新的?就是等於前一次的η再除以σ^t,而 σ^t則代表的是第 t 次以前的所有梯度更新值之平方和開根號(root mean square)。
RMSProp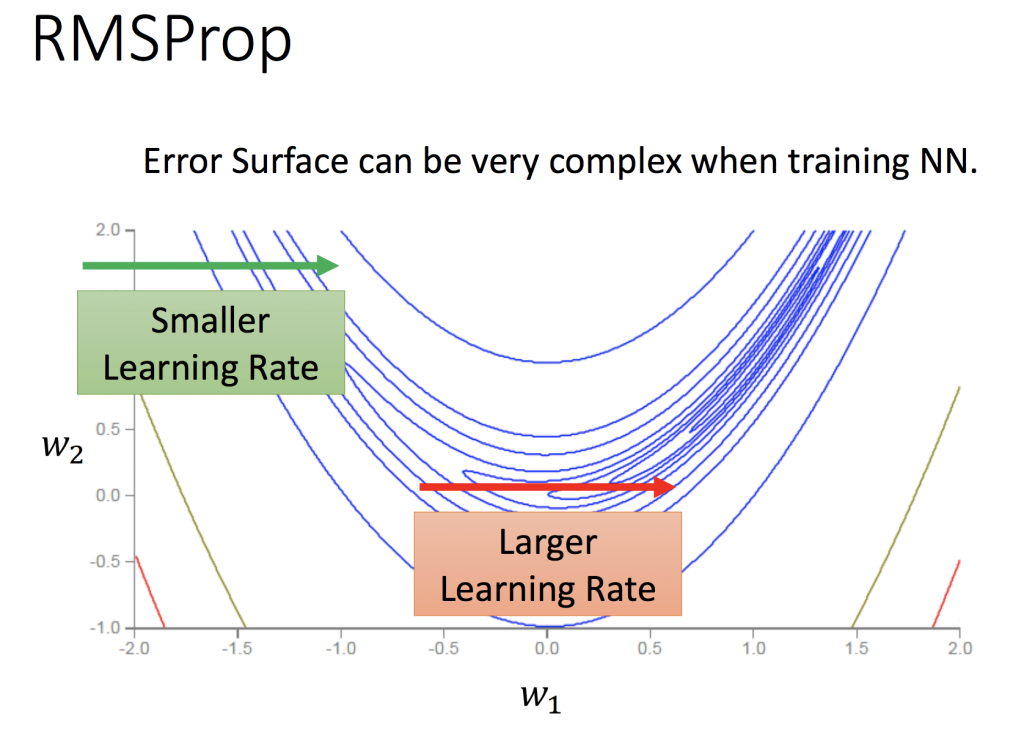

Momentum
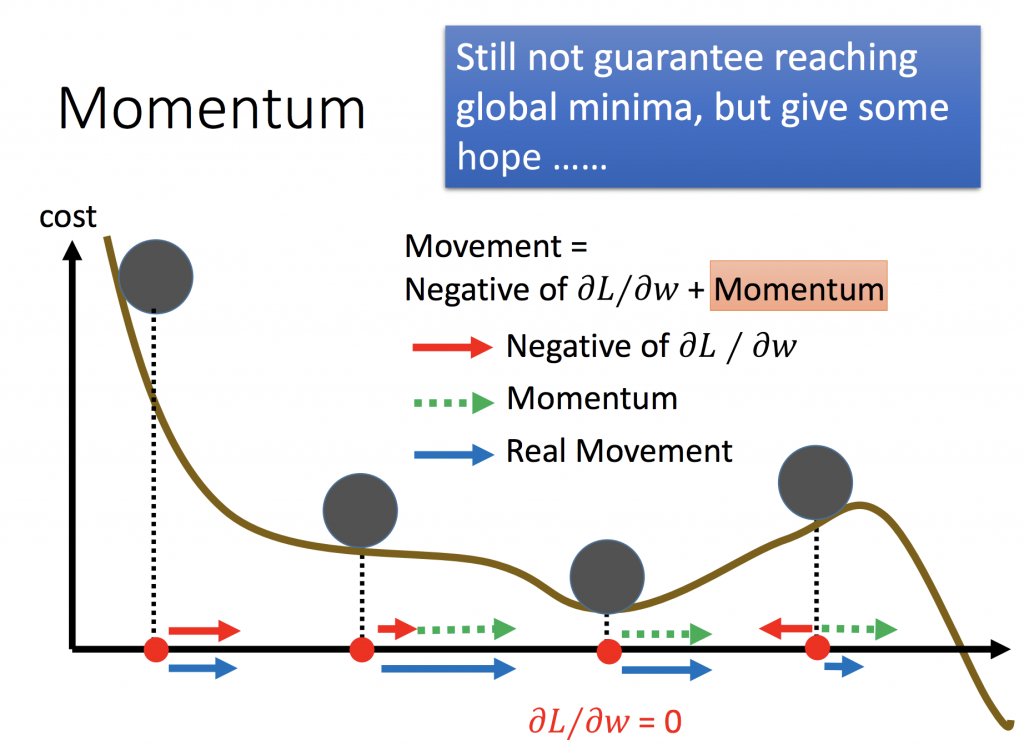
momentum就是慣性或動量的意思,利用物理的概念做更新。如下圖所示,藍色線是位移,而綠色線代表就是momentum,它可以解決停在local minimum的問題。如第二張圖所示,當球滾到最右邊的時候,gradient告訴我們的方向是往左,可能會卡在local minmum的地方,但是如果加上momemtum是有可能可以往右前進,突破local minmum。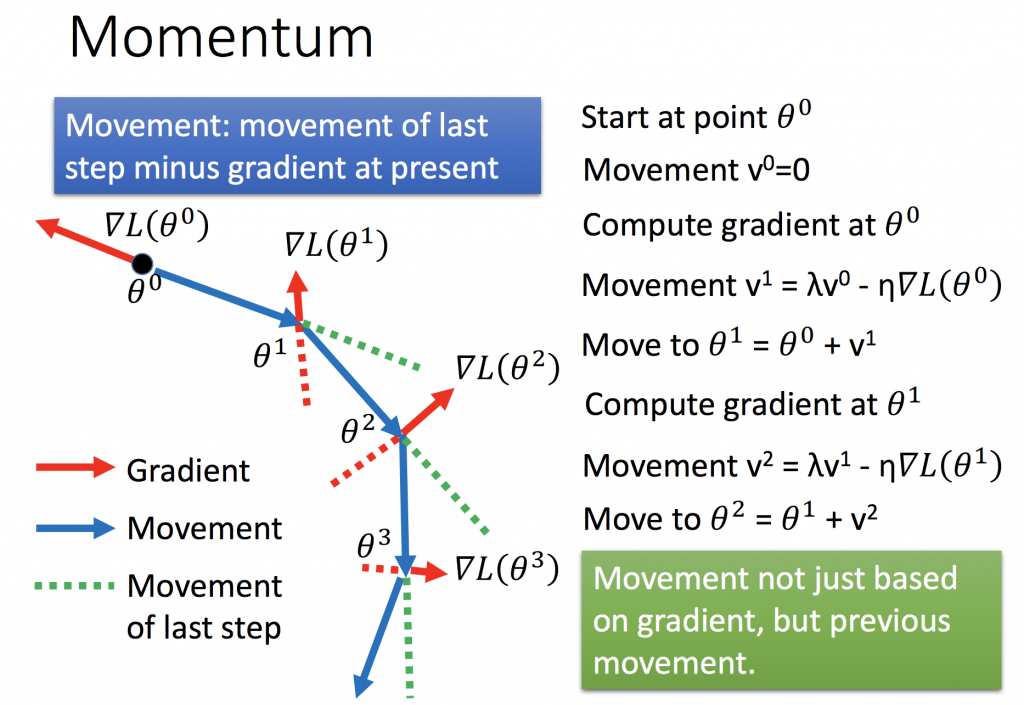
Adam
Adam其實就是加了momentum的RMSProp,下圖的公式mt代表的是momentum,就是前一個時間點的movement(可以參考上面momentum的介紹),vt就是RMSProp裡的σ,式子雖然看起來很複雜,但其實跟RMSProp很類似,每次更新都會調整新舊gradient的比重。所以Adam繼承兩者的優點,適合大部分的狀況,為目前最常使用的優化方法。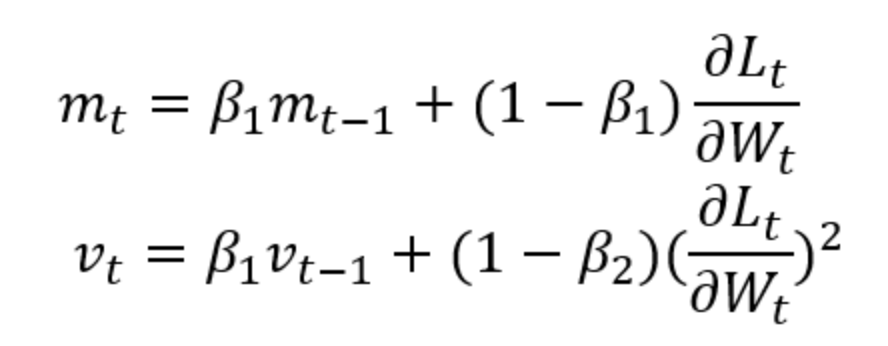
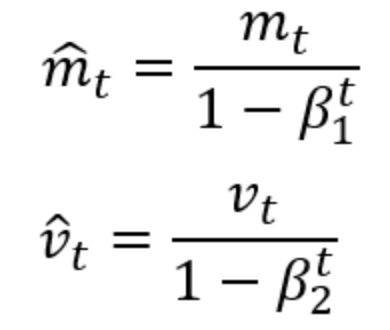
tensorflow簡單實作
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def _height(x, y):
# z = np.sqrt(x**2 + y**2)
z = 0.5 * (x**2) + 0.8 * (y**2)
return z
def main():
x = tf.Variable(-8.00000)
y = tf.Variable(4.00000)
a = tf.constant(0.1000)
b = tf.constant(1.0000)
mul1 = tf.multiply(a, tf.square(x))
mul2 = tf.multiply(b, tf.square(y))
output = tf.add(mul1, mul2)
gradient_op = tf.train.GradientDescentOptimizer(
learning_rate=0.4).minimize(output)
momentum_op = tf.train.MomentumOptimizer(
learning_rate=0.035, momentum=0.9).minimize(output)
adagrad_op = tf.train.AdagradOptimizer(learning_rate=2).minimize(output)
rms_op = tf.train.RMSPropOptimizer(learning_rate=0.5).minimize(output)
adam_op = tf.train.AdamOptimizer(learning_rate=0.35).minimize(output)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
epochs = 30
start_x = [-8.0]
start_y = [4.0]
for epoch in range(epochs):
print("epoch of triaining", epoch)
sess.run(rms_op)
array_x = sess.run(x)
array_y = sess.run(y)
start_x.append(array_x)
start_y.append(array_y)
print(epoch)
print(start_x)
print(start_y)
x = np.arange(-10.0, 10.0, 2)
y = np.arange(-10.0, 10.0, 2)
X, Y = np.meshgrid(x, y)
Z = _height(X, Y)
plt.figure(figsize=(8, 4))
cs = plt.contourf(X, Y, Z, 15, alpha=0.75, cmap='rainbow')
# cs = plt.contour(X, Y, Z, 15, cmap='rainbow')
plt.plot(start_x, start_y, c='b')
plt.title('rms')
for xt, yt in zip(start_x, start_y):
plt.scatter(xt, yt, c='b')
plt.show()
if __name__ == '__main__':
main()
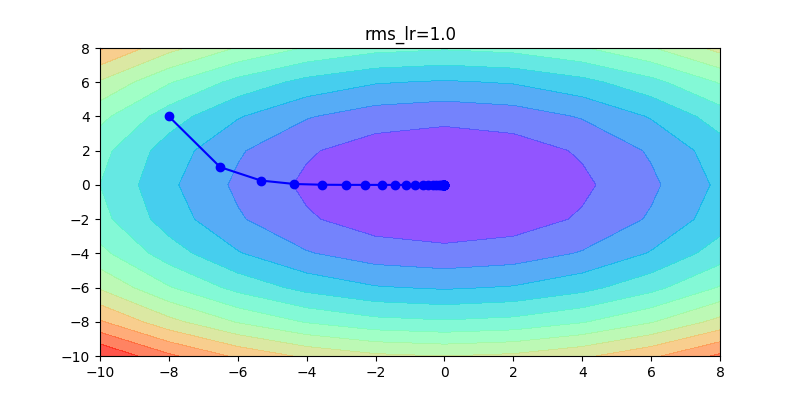
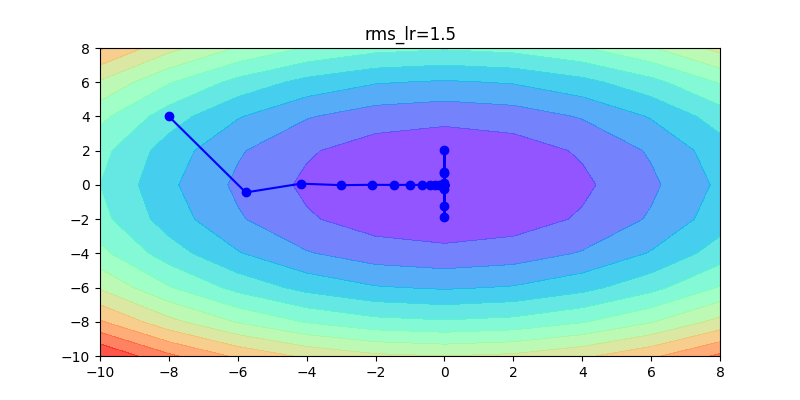
下面這幾張圖片,是這幾種方法的比較,可以清楚看到各種方法的差異,如何調整learning rate讓其收斂是非常重要的。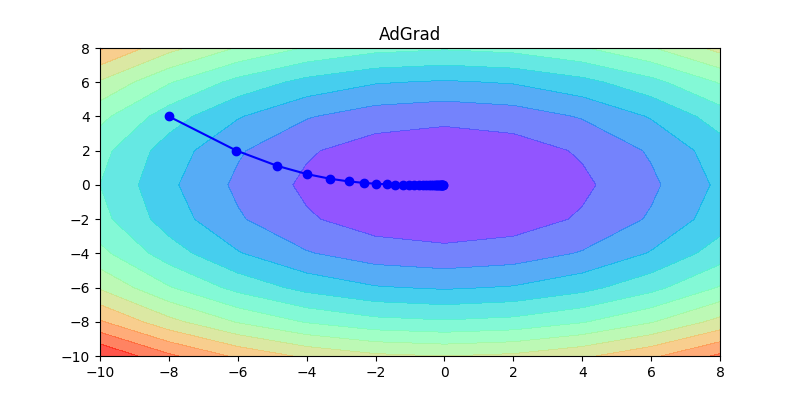
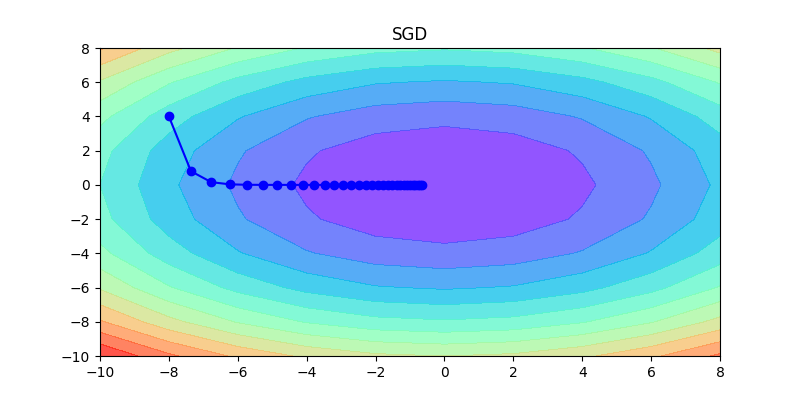
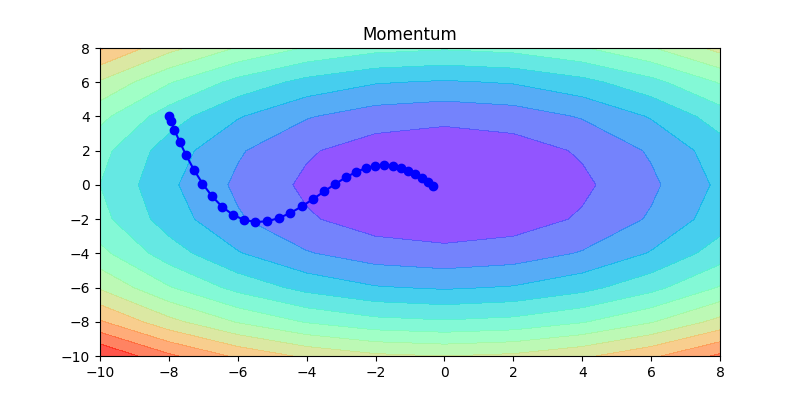
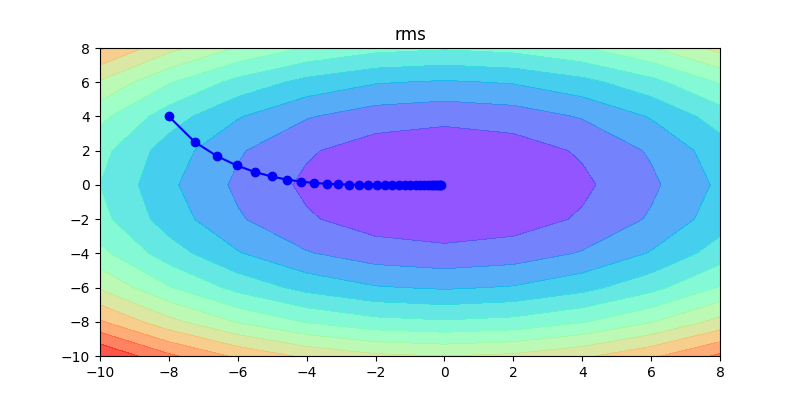
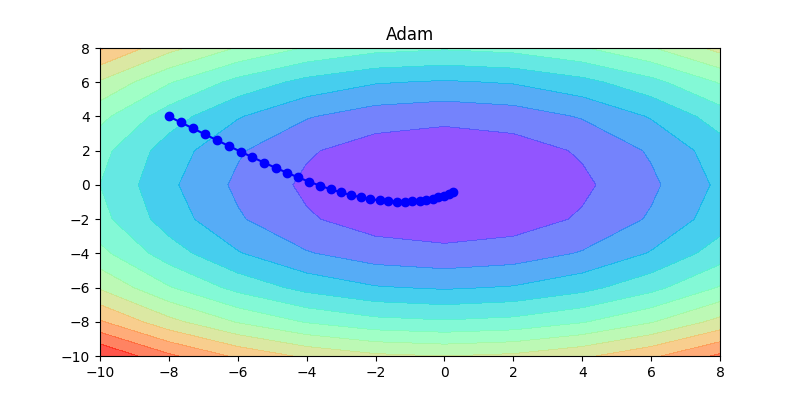
以下這是固定同一種方式,不同learning rate的比較:如果learning rate太大會造成波動非常大;反之,如果learning rate非常小,收斂得很慢。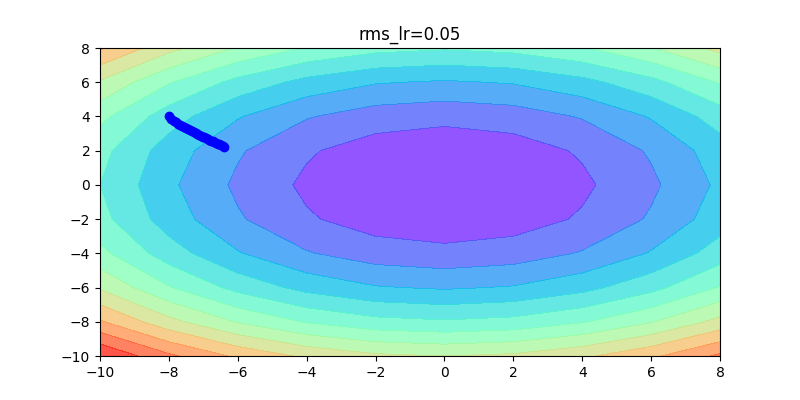
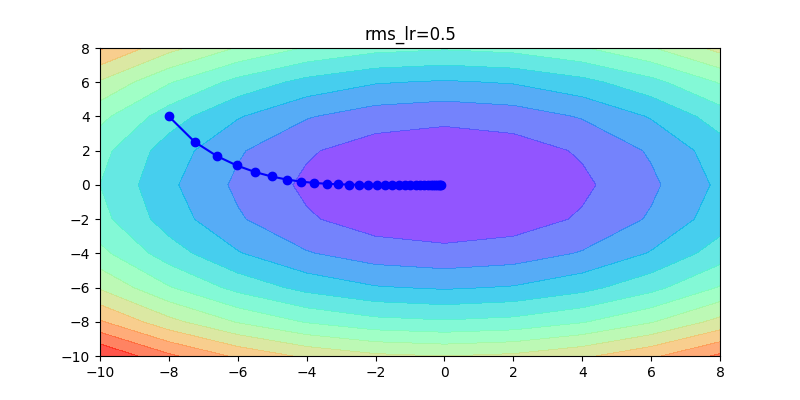
參考資料


 iThome鐵人賽
iThome鐵人賽