使用 pip 安裝
# 繪製圖表
pip install plotly
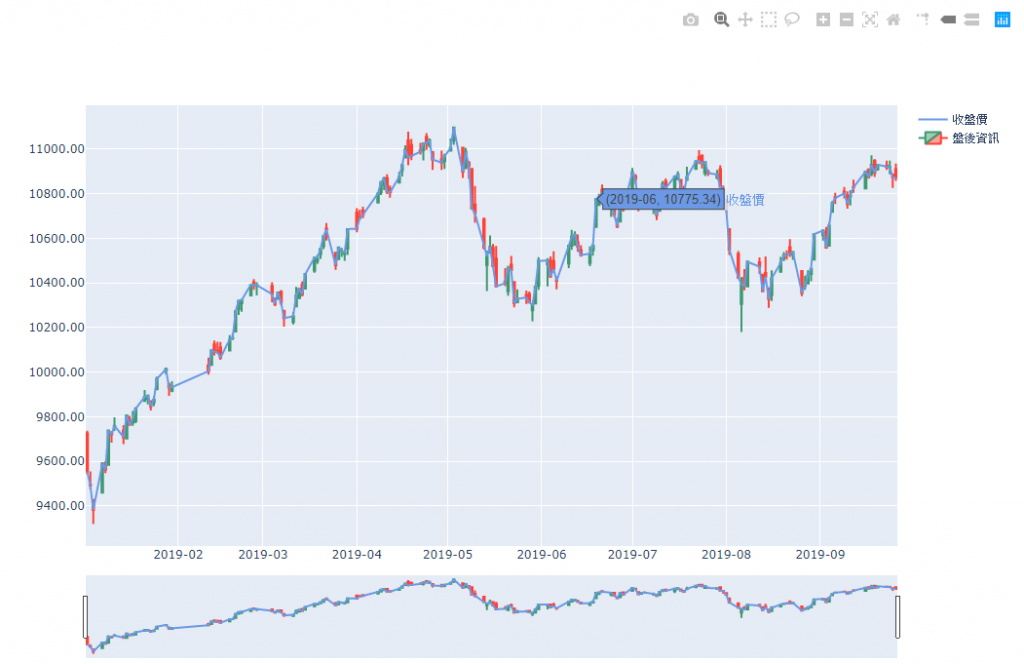
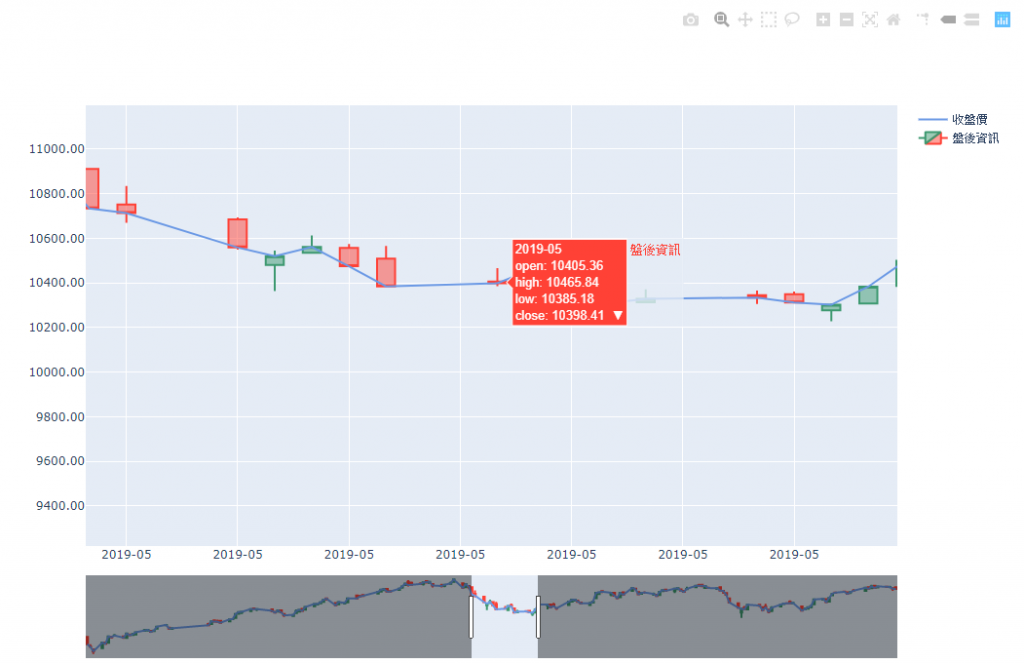
如果能抓取一整年每個交易日的盤後資訊,就能畫出日 K 和日均線作為長期趨勢判斷。
import csv
import datetime
import fractions
import json
import os
import random
import re
import time
import urllib.parse
import js2py
import loguru
import pandas
import plotly.graph_objects
import pyquery
import requests
import requests.exceptions
now = datetime.datetime.now()
proxies = []
proxy = None
class Taiex:
def __init__(self, date, openPrice, highestPrice, lowestPrice, closePrice):
# 日期
self.Date = date
# 開盤價
self.OpenPrice = openPrice
# 最高價
self.HighestPrice = highestPrice
# 最低價
self.LowestPrice = lowestPrice
# 收盤價
self.ClosePrice = closePrice
# 物件表達式
def __repr__(self):
return f'class Taiex {{ Date={self.Date}, OpenPrice={self.OpenPrice}, HighestPrice={self.HighestPrice}, LowestPrice={self.LowestPrice}, ClosePrice={self.ClosePrice} }}'
def getProxy():
global proxies
if len(proxies) == 0:
getProxies()
proxy = random.choice(proxies)
loguru.logger.debug(f'getProxy: {proxy}')
proxies.remove(proxy)
loguru.logger.debug(f'getProxy: {len(proxies)} proxies is unused.')
return proxy
def reqProxies(hour):
global proxies
proxies = proxies + getProxiesFromProxyNova()
proxies = proxies + getProxiesFromGatherProxy()
proxies = proxies + getProxiesFromFreeProxyList()
proxies = list(dict.fromkeys(proxies))
loguru.logger.debug(f'reqProxies: {len(proxies)} proxies is found.')
def getProxies():
global proxies
hour = f'{now:%Y%m%d%H}'
filename = f'proxies-{hour}.csv'
filepath = f'{filename}'
if os.path.isfile(filepath):
loguru.logger.info(f'getProxies: {filename} exists.')
loguru.logger.warning(f'getProxies: {filename} is loading...')
with open(filepath, 'r', newline='', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
for row in reader:
proxy = row['Proxy']
proxies.append(proxy)
loguru.logger.success(f'getProxies: {filename} is loaded.')
else:
loguru.logger.info(f'getProxies: {filename} does not exist.')
reqProxies(hour)
loguru.logger.warning(f'getProxies: {filename} is saving...')
with open(filepath, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow([
'Proxy'
])
for proxy in proxies:
writer.writerow([
proxy
])
loguru.logger.success(f'getProxies: {filename} is saved.')
def getProxiesFromProxyNova():
proxies = []
countries = [
'tw',
'jp',
'kr',
'id',
'my',
'th',
'vn',
'ph',
'hk',
'uk',
'us'
]
for country in countries:
url = f'https://www.proxynova.com/proxy-server-list/country-{country}/'
loguru.logger.debug(f'getProxiesFromProxyNova: {url}')
loguru.logger.warning(f'getProxiesFromProxyNova: downloading...')
response = requests.get(url)
if response.status_code != 200:
loguru.logger.debug(f'getProxiesFromProxyNova: status code is not 200')
continue
loguru.logger.success(f'getProxiesFromProxyNova: downloaded.')
d = pyquery.PyQuery(response.text)
table = d('table#tbl_proxy_list')
rows = list(table('tbody:first > tr').items())
loguru.logger.warning(f'getProxiesFromProxyNova: scanning...')
for row in rows:
tds = list(row('td').items())
if len(tds) == 1:
continue
js = row('td:nth-child(1) > abbr').text()
js = 'let x = %s; x' % (js[15:-2])
ip = js2py.eval_js(js).strip()
port = row('td:nth-child(2)').text().strip()
proxy = f'{ip}:{port}'
proxies.append(proxy)
loguru.logger.success(f'getProxiesFromProxyNova: scanned.')
loguru.logger.debug(f'getProxiesFromProxyNova: {len(proxies)} proxies is found.')
time.sleep(1)
return proxies
def getProxiesFromGatherProxy():
proxies = []
countries = [
'Taiwan',
'Japan',
'United States',
'Thailand',
'Vietnam',
'Indonesia',
'Singapore',
'Philippines',
'Malaysia',
'Hong Kong'
]
for country in countries:
url = f'http://www.gatherproxy.com/proxylist/country/?c={urllib.parse.quote(country)}'
loguru.logger.debug(f'getProxiesFromGatherProxy: {url}')
loguru.logger.warning(f'getProxiesFromGatherProxy: downloading...')
response = requests.get(url)
if response.status_code != 200:
loguru.logger.debug(f'getProxiesFromGatherProxy: status code is not 200')
continue
loguru.logger.success(f'getProxiesFromGatherProxy: downloaded.')
d = pyquery.PyQuery(response.text)
scripts = list(d('table#tblproxy > script').items())
loguru.logger.warning(f'getProxiesFromGatherProxy: scanning...')
for script in scripts:
script = script.text().strip()
script = re.sub(r'^gp\.insertPrx\(', '', script)
script = re.sub(r'\);$', '', script)
script = json.loads(script)
ip = script['PROXY_IP'].strip()
port = int(script['PROXY_PORT'].strip(), 16)
proxy = f'{ip}:{port}'
proxies.append(proxy)
loguru.logger.success(f'getProxiesFromGatherProxy: scanned.')
loguru.logger.debug(f'getProxiesFromGatherProxy: {len(proxies)} proxies is found.')
time.sleep(1)
return proxies
def getProxiesFromFreeProxyList():
proxies = []
url = 'https://free-proxy-list.net/'
loguru.logger.debug(f'getProxiesFromFreeProxyList: {url}')
loguru.logger.warning(f'getProxiesFromFreeProxyList: downloading...')
response = requests.get(url)
if response.status_code != 200:
loguru.logger.debug(f'getProxiesFromFreeProxyList: status code is not 200')
return
loguru.logger.success(f'getProxiesFromFreeProxyList: downloaded.')
d = pyquery.PyQuery(response.text)
trs = list(d('table#proxylisttable > tbody > tr').items())
loguru.logger.warning(f'getProxiesFromFreeProxyList: scanning...')
for tr in trs:
tds = list(tr('td').items())
ip = tds[0].text().strip()
port = tds[1].text().strip()
proxy = f'{ip}:{port}'
proxies.append(proxy)
loguru.logger.success(f'getProxiesFromFreeProxyList: scanned.')
loguru.logger.debug(f'getProxiesFromFreeProxyList: {len(proxies)} proxies is found.')
return proxies
# 取得指定年月內每交易日的盤後資訊
def getTaiexs(year, month):
global proxy
taiexs = []
while True:
if proxy is None:
proxy = getProxy()
url = f'https://www.twse.com.tw/indicesReport/MI_5MINS_HIST?response=json&date={year}{month:02}01'
loguru.logger.info(f'getTaiexs: month {month} url is {url}')
loguru.logger.warning(f'getTaiexs: month {month} is downloading...')
try:
response = requests.get(
url,
proxies={
'https': f'https://{proxy}'
},
timeout=3
)
if response.status_code != 200:
loguru.logger.success(f'getTaiexs: month {month} status code is not 200.')
proxy = None
break
loguru.logger.success(f'getTaiexs: month {month} is downloaded.')
body = response.json()
stat = body['stat']
if stat != 'OK':
loguru.logger.error(f'getTaiexs: month {month} responses with error({stat}).')
break
records = body['data']
if len(records) == 0:
loguru.logger.success(f'getTaiexs: month {month} has no data.')
break
for record in records:
date = record[0].strip()
parts = date.split('/')
y = int(parts[0]) + 1911
m = int(parts[1])
d = int(parts[2])
date = f'{y}{m:02d}{d:02d}'
openPrice = record[1].replace(',', '').strip()
highestPrice = record[2].replace(',', '').strip()
lowestPrice = record[3].replace(',', '').strip()
closePrice = record[4].replace(',', '').strip()
taiex = Taiex(
date=date,
openPrice=openPrice,
highestPrice=highestPrice,
lowestPrice=lowestPrice,
closePrice=closePrice
)
taiexs.append(taiex)
except requests.exceptions.ConnectionError:
loguru.logger.error(f'getTaiexs: proxy({proxy}) is not working (connection error).')
proxy = None
continue
except requests.exceptions.ConnectTimeout:
loguru.logger.error(f'getTaiexs: proxy({proxy}) is not working (connect timeout).')
proxy = None
continue
except requests.exceptions.ProxyError:
loguru.logger.error(f'getTaiexs: proxy({proxy}) is not working (proxy error).')
proxy = None
continue
except requests.exceptions.SSLError:
loguru.logger.error(f'getTaiexs: proxy({proxy}) is not working (ssl error).')
proxy = None
continue
except Exception as e:
loguru.logger.error(f'getTaiexs: proxy({proxy}) is not working.')
loguru.logger.error(e)
proxy = None
continue
break
return taiexs
# 儲存傳入的盤後資訊
def saveTaiexs(filepath, taiexs):
loguru.logger.info(f'saveTaiexs: {len(taiexs)} taiexs.')
loguru.logger.warning(f'saveTaiexs: {filepath} is saving...')
with open(filepath, mode='w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow([
'Date',
'OpenPrice',
'HighestPrice',
'LowestPrice',
'ClosePrice'
])
for taiex in taiexs:
writer.writerow([
taiex.Date,
taiex.OpenPrice,
taiex.HighestPrice,
taiex.LowestPrice,
taiex.ClosePrice
])
loguru.logger.success(f'main: {filepath} is saved.')
def main():
taiexs = []
# 取得從 2019.01 至 2019.12 的盤後資訊
for month in range(1, 13):
taiexs = taiexs + getTaiexs(2019, month)
filepath = f'taiexs-2019.csv'
saveTaiexs(filepath, taiexs)
# 使用 Pandas 讀取下載回來的紀錄檔
df = pandas.read_csv(filepath)
# 將 Date 欄位按照格式轉換為 datetime 資料
df['Date'] = pandas.to_datetime(df['Date'], format='%Y%m%d')
# 建立圖表
figure = plotly.graph_objects.Figure(
data=[
# Line Chart
# 收盤價
plotly.graph_objects.Scatter(
x=df['Date'],
y=df['ClosePrice'],
name='收盤價',
mode='lines',
line=plotly.graph_objects.scatter.Line(
color='#6B99E5'
)
),
# Candlestick Chart
# K 棒
plotly.graph_objects.Candlestick(
x=df['Date'],
open=df['OpenPrice'],
high=df['HighestPrice'],
low=df['LowestPrice'],
close=df['ClosePrice'],
name='盤後資訊',
)
],
# 設定 XY 顯示格式
layout=plotly.graph_objects.Layout(
xaxis=plotly.graph_objects.layout.XAxis(
tickformat='%Y-%m'
),
yaxis=plotly.graph_objects.layout.YAxis(
tickformat='.2f'
)
)
)
figure.show()
if __name__ == '__main__':
loguru.logger.add(
f'{datetime.date.today():%Y%m%d}.log',
rotation='1 day',
retention='7 days',
level='DEBUG'
)
main()
團隊系列文:
CSScoke - 金魚都能懂的這個網頁畫面怎麼切 - 金魚都能懂了你還怕學不會嗎
Clarence - LINE bot 好好玩 30 天玩轉 LINE API
Hina Hina - 陣列大亂鬥
King Tzeng - IoT沒那麼難!新手用JavaScript入門做自己的玩具
Vita Ora - 好 Js 不學嗎 !? JavaScript 入門中的入門。
TaTaMo - 用Python開發的網頁不能放到Github上?Lektor說可以!!

