昨天介紹完Matplotlib相關應用,Matplotlib強大的地方就是可以方便、快速地視覺化出資料的樣貌,如我們後來會要畫損失函數的下樣貌或者準確度的爬升,利用Matplotlib會非常快速。
雖然今天Pandas有些區塊與Matplotlib重覆到(圓柱、折線圖等等),但再繪圖上面還是Matplotlib較為方便,所以我們今天介紹的Pandas會著重在偏向資料方面的處理,這對於我們後來的實作案例相當重要,有些資料對於結果必不是那面重要,所以我們會需要整理、處理資料。
圖片出處
(補充:如果介面是黑色的表示我是用個人筆電,如果是白色的就是實驗室電腦 )
)
上面有提及pandas在資料處理上的非常強大,且Pandas也和Matplotlib是一個基於Numpy的函式庫,而Padas也有另一種說法是,Pandas就是把excell的功能搬過來pyhton,許多在excell可以做到的事情,利用Pandas在python也可以辦到,如csv檔的讀取、刪減、增加、欄位的替換等等,這些功能在我們往後的案例都會常常使用到!
我們一樣要先導入函式庫:
import pandas as pd
import numpy as np
這邊要先介紹pandas裡面的兩種常用的資料格式,分別是DataFrame與Series。
Series是一種類似序列的指令,當在使用Series儲存資料的時候,會自動幫儲存的資料標上索引值(index),所以可以利索引值去提取裡面的資料(儲存的資料類型不限)。
1.建立Series:
S = pd.Series([1,2,3,'John',4,5])
S
輸出:
0 1
1 2
2 3
3 John
4 4
5 5
dtype: object
2.提取裡面的資料和索引值:
values = S.values #提取資料
index = S.index #提取index
print(values)
print(index)
輸出:
[1 2 3 'John' 4 5]
RangeIndex(start=0, stop=6, step=1)
3.自己定義喜歡的index並取出其中的index資料:
S2 = pd.Series([1,2,3,4,'John'], index=['Q','W','E','R','T'])#1.資料2.索引值
print(S2)
S2['T']
輸出:
Q 1
W 2
E 3
R 4
T John
dtype: object
'John'
DataFrame是一種二維空間上的指令,就像是excel的表格一樣,有行和有列,DataFrame有索引值(index)和行數(column),可以利用索引值和行數去抓到裡面的資料(儲存的資料類型不限)。
1.建立DataFrame:
D = pd.DataFrame(np.arange(20).reshape((5,4)))
#np.arange從0列到19;reshape是把它變成5*4的型狀
print(D)
輸出:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
2.從diction轉換成dataframe:
data = {'區域': ['北區', '中區','南區','東區'],
'人口': [300000, 500000, 412000, 240000],
'地價(每坪)': [300000, 250000, 400000, 230000],
'福利指數(滿分10)':[7,6,8,7]} #字典
D2 = pd.DataFrame(data) #轉換成dataframe格式
print(D2)
輸出:
區域 人口 地價(每坪) 福利指數(滿分10)
0 北區 300000 300000 7
1 中區 500000 250000 6
2 南區 412000 400000 8
3 東區 240000 230000 7
直接在最後行打上D的輸出會比較像表格: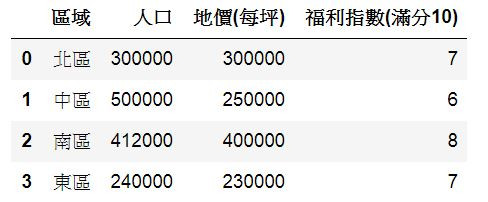
3.特定行查看:
print(D2['區域']) #中括號和行名稱
輸出:
0 北區
1 中區
2 南區
3 東區
Name: 區域, dtype: object
4.特定列查看:
print(D2.loc[[0, 1]]) #查看0和1兩列
輸出:
區域 人口 地價(每坪) 福利指數(滿分10)
0 北區 300000 300000 7
1 中區 500000 250000 6
5.找特定位置:
print(D2.iloc[3,2])#用iloc函式指定第三列、第二行資料(是從0開始數唷)
輸出:
230000
6.新增行數(column)
data = {'區域': ['北區', '中區','南區','東區'],
'人口': [300000, 500000, 412000, 240000],
'地價(每坪)': [300000, 250000, 400000, 230000],
'福利指數(滿分10)':[7,6,8,7]} #字典
D3 = pd.DataFrame(data,columns=['區域','人口', '地價(每坪)', '福利指數(滿分10)','就業機會'])
D3
輸出: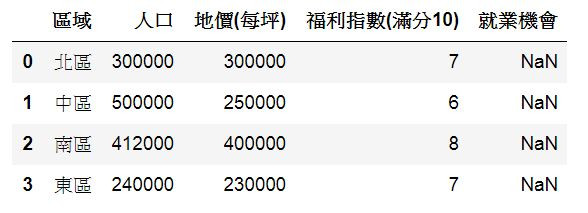
會發現就業機會出現NaN,是因為我們並沒有給這欄有任何資料,所以才會無資料顯示。
7.新增行資料:
D3['就業機會']=['高','中','高','中']
D3
輸出: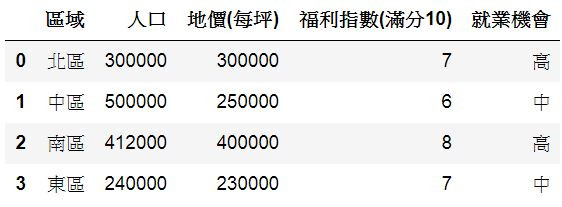
8.刪除某欄:
D3.drop(columns=['就業機會', '地價(每坪)']) #刪除欄
D3.drop(index=[0, 1]) #刪除列
輸出: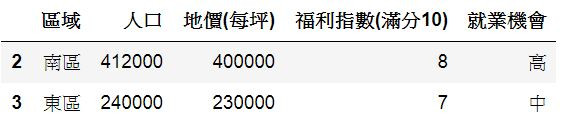
9.新增列及前面部分綜合(以防數據錯亂搞混):
data = {'區域': ['北區', '中區','南區','東區'],
'人口': [300000, 500000, 412000, 240000],
'地價(每坪)': [300000, 250000, 400000, 230000],
'福利指數(滿分10)':[7,6,8,7]} #字典
D3 = pd.DataFrame(data,columns=['區域','人口', '地價(每坪)', '福利指數(滿分10)','就業機會']) #新增"就業機會"這欄
D3['就業機會']=['高','中','高','中'] #填入就業機會資料
D3 = D3.append({"區域":'西區', "人口":350000,"地價(每坪)": 280000 ,"福利指數(滿分10)":7 ,"就業機會":'低'},ignore_index=True)
#1.要新增的字典2.預設是False,意思是一定要填入資料,所以要改成True
D3
輸出: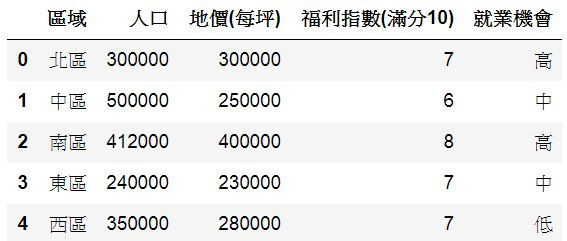
今天已經第12天了,真是辛苦啊,還是要提醒讀者,本系列文章基礎指令會著重在常使用的、基礎的函式庫及指令,讀者若是新手可以知道哪些是比較常用、基礎的,但對於有一定程度、想要真正完整了解特定函式庫的人,可能要直接搜尋有關此函式庫的專門教學文章會比較適合,因為我想要讓大家在30天能夠走向kaggle的經典案例實際操作,所以只會提到基礎的以及相關的指令!
今天Pandas部分先介紹到這裡拉,明天會再補充有關CVS檔的處理,要繼續跟上唷!GOGO!


 iThome鐵人賽
iThome鐵人賽