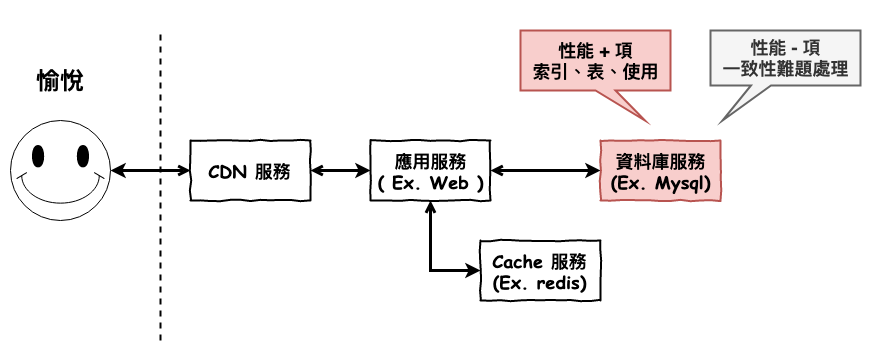
上一篇文章中,我們理解了 innoDB 索引的基本原理 b+ 樹的,也理解了為什麼 innoDB 要選擇 b+ 樹的原因後,那接下來,我們要來理解,在 innoDB 中『 實際上 』是如何使用 b+ 樹來建立索引機制 ?
本篇文章分為以下幾個章節 :
假設我們有以下的 table 表,然後咱們不要手動設什麼索引,那麼 innodb 會如何儲存它呢 ?
| Id ( PK ) | Name | age |
|---|---|---|
| 1 | Mark | 18 |
| 2 | Jack | 10 |
| 3 | Ian | 36 |
| 4 | Jiro | 30 |
| 5 | Fucc | 27 |
| ... | ... | ... |
| 10 | Fukk | 46 |
| 表 1 : 範例 |
首先 innodb 會自動幫你建立一個叫『 clustered Index 』的東東,在 innodb 中,它就是這份資料實際上儲存的結構,請別管它叫索引,它就是你的實際資料,只是它是有規則的儲存結構。
這個儲存結構就是使用我們上一篇所提的『 b+ 樹 』。
那 innodb 會選擇上面那一行的欄位,來當節點的 key 呢 ?
它的選擇如下 :
由於咱們有 pk,所以 innodb 會自動以它來幫我們產生出以下圖 1 所示的 clustered Index。
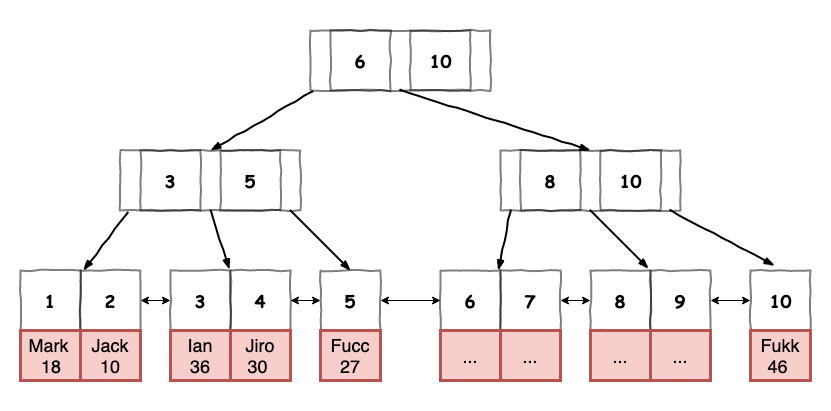
圖 1 : innodb 根據 表 1 所建立的 clustered Index 範例。
~ 注意事項 ~
下面的文章或圖片中,很多咱們會直接說使用 pk 去 clustered Index,但比較準備的說,應該是使用『 某個值 』而這個值,就是建立 clustered Index 的值,它不一定是用 pk,只是下面打 pk 比較方便。
接下來我們來看看,如果咱們在這個表實際上下 query 它會如何找。
基本上就如同下圖一樣綠色圖案的路徑來尋找。
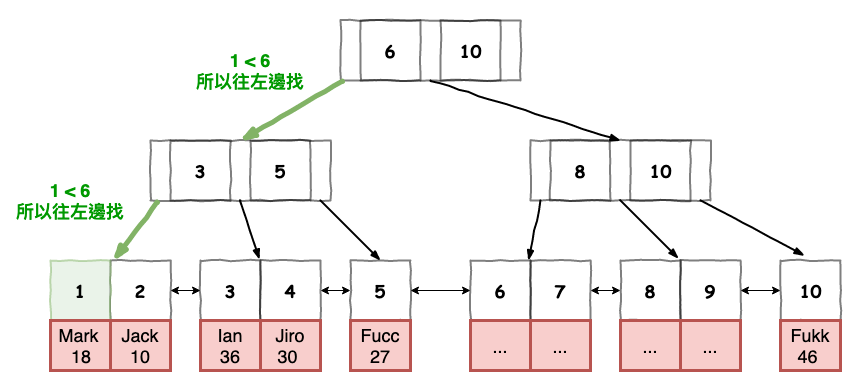
圖 2 : 範例 1 行走圖
由於基本上 query 的欄位不是使用索引欄位,因此這就代表他只能一個一個慢慢找。
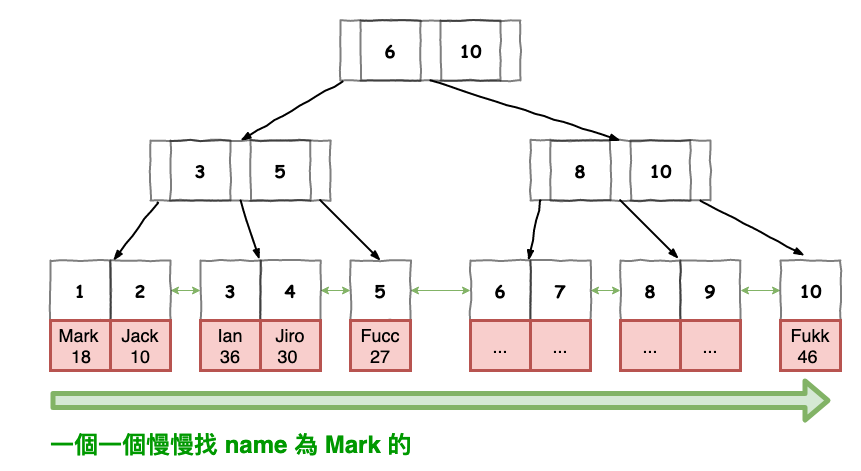
圖 3 : 範例 2 行走圖
上面的 clustered Index 是咱們啥都不做,它就會自然建立起來的東西,而接下來咱們要介紹的『 Secondary Index 』才是咱們實際上可以自行建立的索引。
ALTER TABLE table ADD INDEX age_index(age)
所以當咱們執行以上 sql 指令後,會使用 age 欄位,來建立出來的索引 b+ 樹如下圖,其中要注意一下,自已建的 secondary index 本身沒有資料,所以通常情況還要在去 clustered Index 抓資料。
| Id (PK) | Name | age |
|---|---|---|
| 1 | Mark | 18 |
| 2 | Jack | 10 |
| 3 | Ian | 36 |
| 4 | Jiro | 30 |
| 5 | Fucc | 27 |
| ... | ... | ... |
| 10 | Fukk | 46 |
| 表 2 |
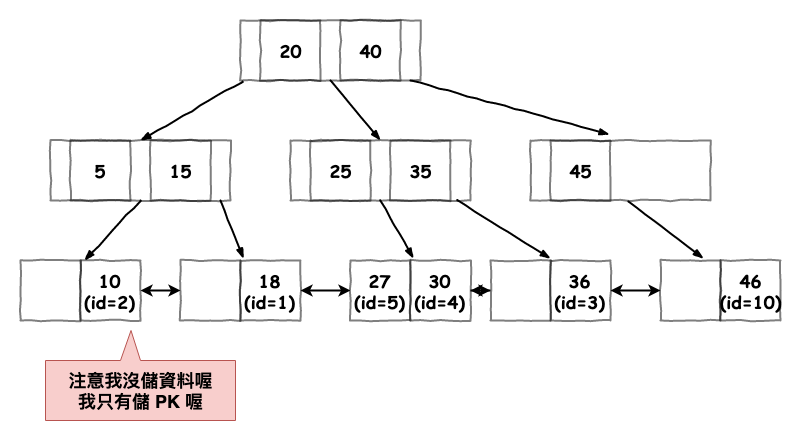
圖 4 : innodb 根據表 2 所建立的 secondary index
首先第一步,它會去 age 的 b+ 索引樹尋找,如下圖 5 所示,然後它會尋找到 pk 為 1 的資料。
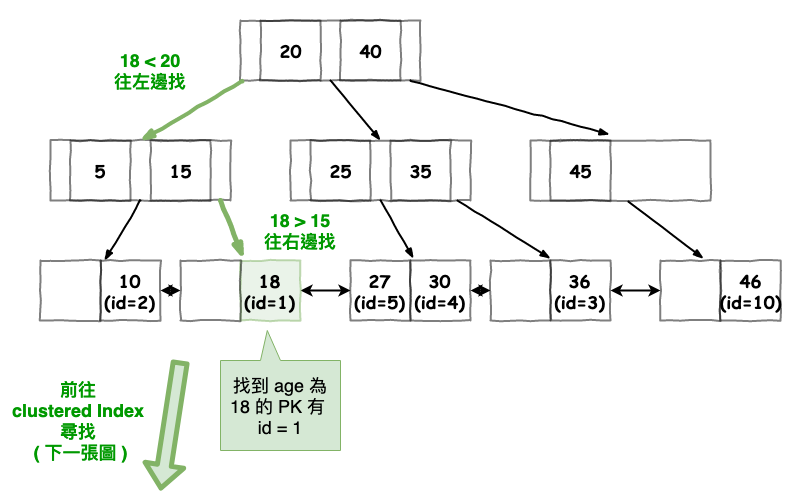
圖 5 : 範例 1 至 secondary index 尋找圖。
接下來第二步,會去使用 pk 為 1 資料去 clustered Index 取得完整資料。
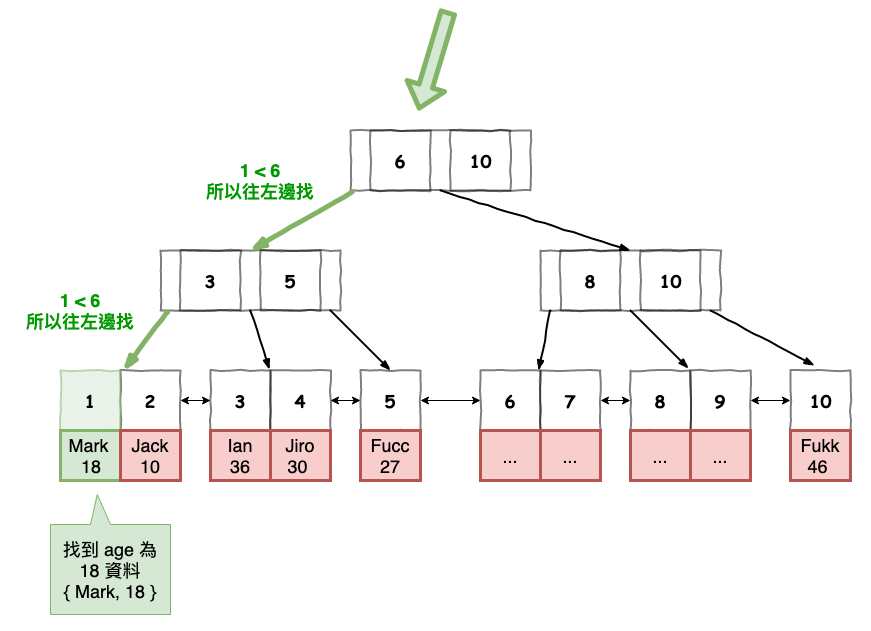
圖 6 : 範例 1 之後去 clustered Index 尋找圖
而這就是最基本使用 secondary Index 的步驟。
接下來這個範例咱們來看一下範例搜尋。
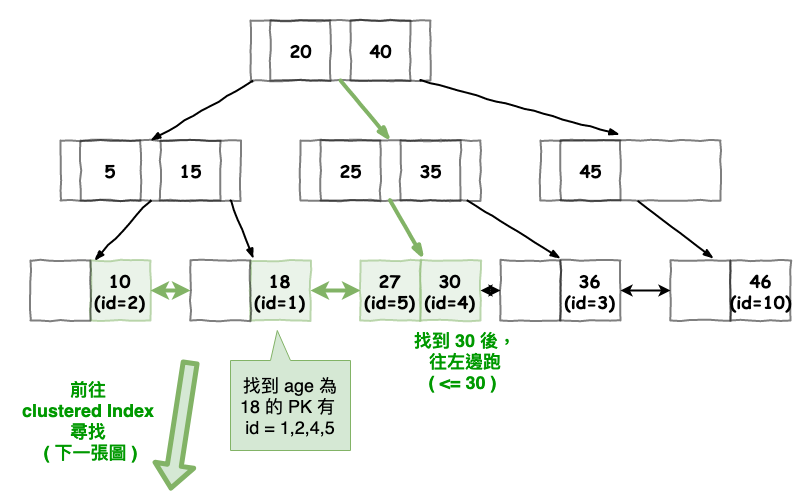
圖 7 : 範例 2 至 secondary index 尋找範例索引圖
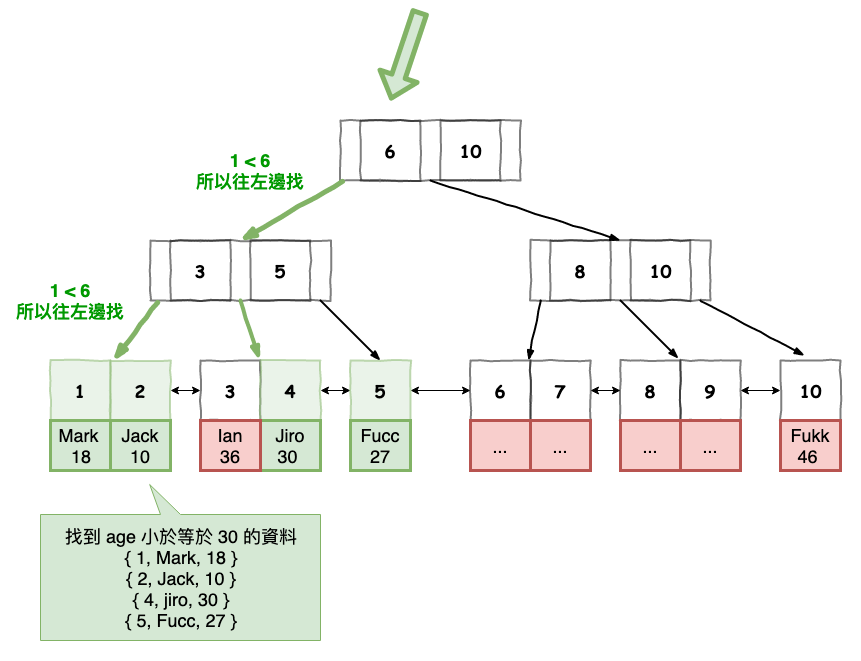
圖 8 : 範例 2 之後去 clustered Index 尋找圖
在 InnoDB 中,它有提供的索引基本上分為兩大類 :
其中 clustered Index 代表包含這原始資料行,而 secondary Index 就是咱們實際上所能建立與使用的索引。
其中 Secondary Index 又分為以下幾類 :
基本上你自已加了一個 secondary Index,那它預設就是個覆蓋索引,而它有一個特點就在於 :
它可以從 secondary Index 直接取得到索引欄位的資料,不用回到 clustered Index 抓資料。
就設咱們有以下的表
| id (PK) | name | age |
|---|---|---|
| 1 | Mark | 18 |
| 2 | Jack | 10 |
| 3 | Ian | 36 |
| 4 | Jiro | 30 |
| 5 | Fucc | 27 |
| ... | ... | ... |
| 10 | Fukk | 46 |
然後你執行了以下的建立索引指令。
ALTER TABLE table ADD INDEX age_index(age)
那它會建立以下的 secondary index 的 b+ 樹,如下,事實上就和上面的圖一樣,我有點懶的在畫一張,請見諒。
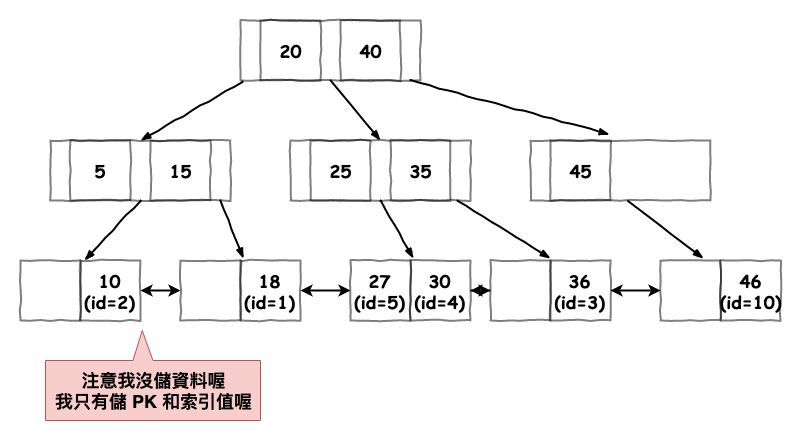
圖 9 : secondary Index 索引樹
然後你這時進行以下查詢,注意咱們只抓 age 這個欄位:
SLEECT age FROM Table WHERE age <= 30
這時它的查詢路徑如下圖,你會發現它只會去 secondary index 找到資料後,就回傳,而不會在像前幾個範例一樣,還需要去 clustered Index 抓所有資料。
注意它沒有至 clustered Index 抓所有資料,因為 query 只要取索引值。
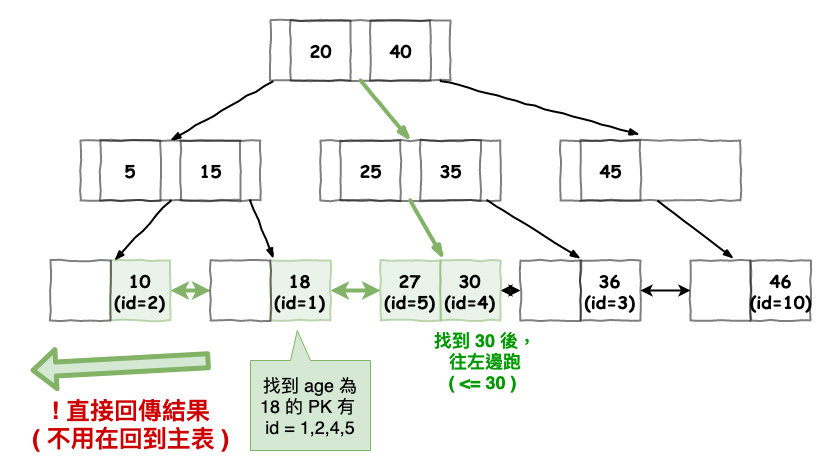
圖 10 : 覆蓋索引搜尋範例圖
連合索引就是可以將兩個欄位組合在一起,建立一個索引表。
假設咱們有以下的資料表。
| id ( PK ) | name | age | power |
|---|---|---|---|
| 1 | Mark | 18 | 100 |
| 2 | Jack | 10 | 10 |
| 3 | Ian | 36 | 10 |
| 4 | Jiro | 30 | 20 |
| 5 | Fucc | 27 | 30 |
| 6 | Mark | 46 | 200 |
然後執行建立連合索引的指令。
create index idx_age_name on table(age,name);
它這時就會建成以下 b+ 樹。由於受限於圖案大小,將這顆樹會縮成 2 層的高度,不然好難畫……
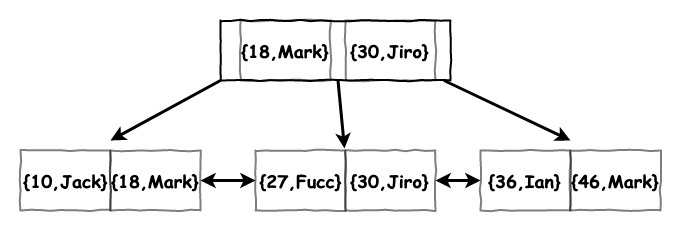
圖 11 : 連合索引範例
然後你這時進行以下查詢,注意咱們只抓 age 這個欄位:
SLEECT name,age FROM db.Table WHERE age <= 20 AND name = 'Mark'
這時它的運行路徑如下圖,它會透過 secondary Index 找到 age <= 20 且 name 為 Mark 的 pk,然後這時因為我們是只要 name 與 age 兩個索引欄位資料,因此就如同覆蓋索引一樣,在 secondary index 就可處理完。
注意雖然我們在最上層就找到了,但是那個只是索引值,而不是可以拿來用的,b+樹它一定會跑到最下面。
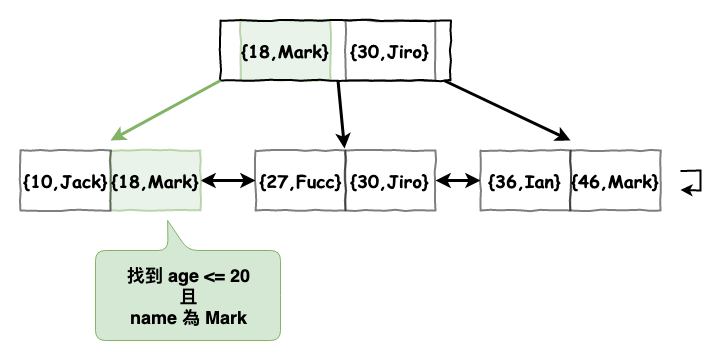
圖 12 : 連合索引搜尋範例
咱們接下來看一下不正確的使用,會讓連合索引失效。
咱們下了以下的 sql,但這一段不會跑連合索引,而是會執行全部掃描。
SLEECT name FROM db.Table WHERE name = 'Mark'
因為你看看下圖,它要如何的找 name = 'Mark',之前有說過索引基本上是以二分法的概念,也就是看看目標在那個區間 ( ex. 左邊或右邊 ),然後在決定去某個區間找。而下圖它的區間都是以 age 來畫分,因此要用 name 來找就會失效。
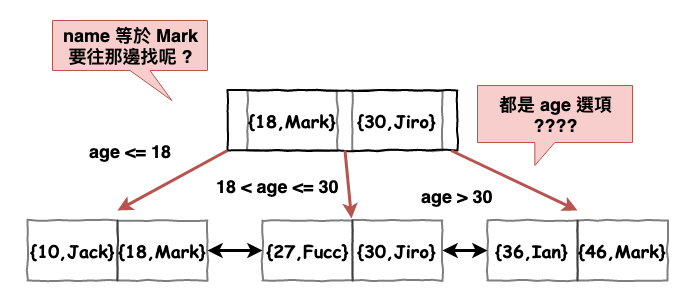
圖 13 : 連合索引失效範例
以索引 { age , name } 情況來看。
WHERE age = 20 => OK !
WHERE age = 20 AND name = 'Mark' => OK !
WHERE name = 'Mark' => No !!!
只後還有一些細節會在之後的文章中詳細的進行總整理。
前綴索引就是指在個長長的字串欄位上的『 前幾個字 』就上索引。
ALTER TABLE xxx ADD KEY (Field(n))
n : 指前幾個字
假設咱們有以下資料表,然後咱們 name 比較特別的會在每個的人名字前面加一個 tag,例如 A-Mark 那個 A。這裡只是先示範前綴索引,就先不探討為什麼不要多一個欄位來放 tag 這問題。
| id (PK) | name | age |
|:--:|:-----:|:---:|:---:|
| 1 | A-Mark | 18 |
| 2 | B-Jack | 10 |
| 3 | C-Ian | 36 |
| 4 | E-Jiro | 30 |
| 5 | D-Fucc | 27 |
| 6 | C-Mark | 46 |
然後咱們執行以下指令來建立前綴索引。
ALTER TABLE xxx ADD INDEX index_tag (name(1))
然後他會建立出以下的 b+ 樹。
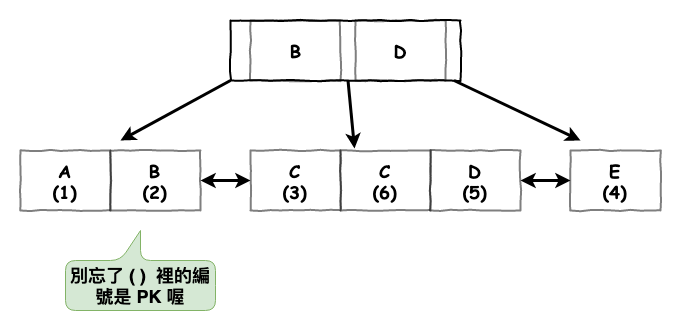
圖 14 : 前綴索引範例
要使用前綴索引查詢,只有以下兩種才能。
SELECT name FROM table WHERE name = 'C-Ian';
SELECT name FROM table WHERE name like 'C-%';
當我們執行以上查詢 sql 後,它就會如下圖一樣進行查詢。先至 secondary index 再去 compound index。
注意它無法像覆蓋索引只在 secondary Index 就抓取 name ( 因為這顆前綴數 name 不完整 )
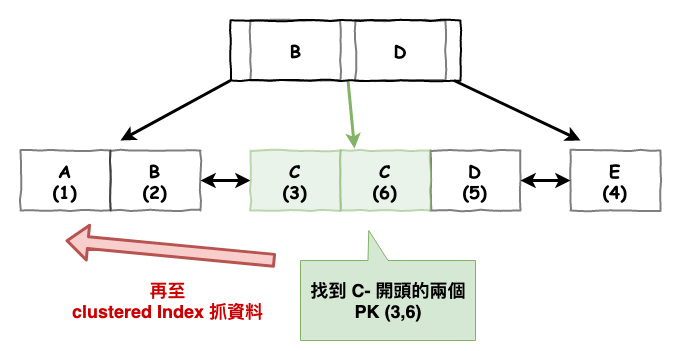
圖 15 : 前綴索引查詢流程流程圖
ALTER TABLE xxx ADD unique(`username`);
這個所產生出來的圖與上面幾個索引都沒差多少,它有幾個重要注意一下 :
就降
這一章咱們介紹了 mysql 中的非常多的索引,咱們簡單的畫一張來理解一下它們的關係,如下圖 16 所示。
首先基本最大的兩個分類為 :
然後大部份的情況下,搜尋流程者是 :
除非你只用 PK 搜尋就只會跑 clustered Index,又或是你用覆蓋索引那它就會只跑 secondary Index。
接下來咱們看一下,可以自已手工建立索甲的的情境下都是所謂的 :
其中下圖 16 中的一般索引,就是咱們直接建立的最簡單索引,如下範例,在上面分類中你沒有看到,為它是直接寫在覆蓋索引中,因為它本來就是覆蓋索引。而下面這圖拉出來只是讓你比較好理解。
ALTER TABLE table ADD INDEX age_index(age)
然後幾種狀況下,『 唯一索引 』與『 連合索引 』都也屬於這一類。
接下來是比較特別一點的 :
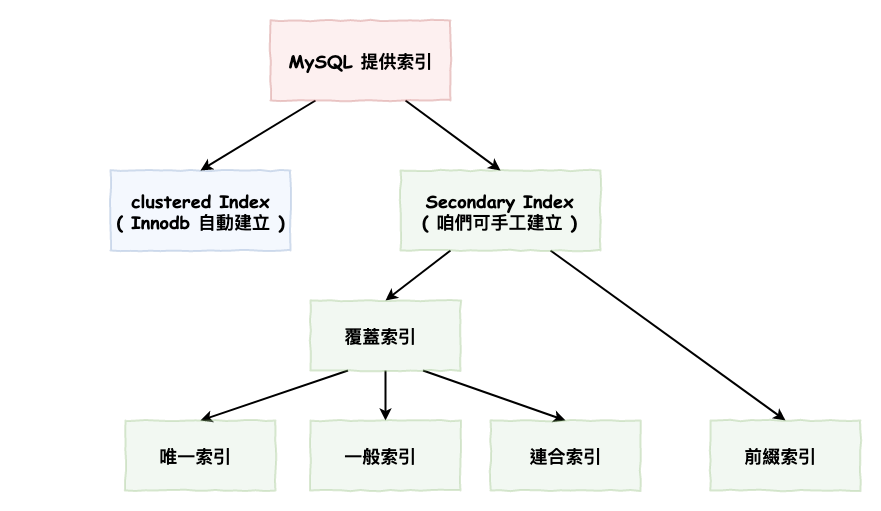
圖 16 : mysql 索引關係圖
謝謝大大精彩的分享,有協助找到一些錯字 ?
連合索引失效 - 索引 { age,name } 找 nmae
應為
連合索引失效 - 索引 { age,name } 找 name
為它是直接寫在覆蓋索引中
因為它是直接寫在覆蓋索引中

