今天要介紹的是時間序列,它是一個隨時間變化的隨機過程,通常是在固定的時間區間上進行分析,例如每天的溫度和降雨量,每月的失業率以及年收入都是時間序列的一種,而分析時間序列資料的工具之一就是線性回歸。讓我們用昨天的例子以時間序列的方式再分析一次,看看有甚麼相異之處。
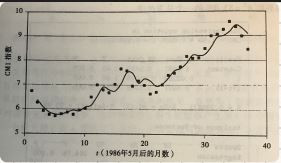
對1986年6月到1989年6月的CM1指數的資料來估計1990年5月的CM1指數
import numpy as np
CM1 = [6.73,6.27,5.93,5.77,5.72,5.8,5.87,5.78,5.96,6.03,6.5,7,6.8,6.68,7.03,7.67,7.59,6.96,7.17,6.99,6.64,6.71,7.01,
7.40,7.49,7.75,8.17,8.09,8.11,8.48,8.99,9.05,9.25,9.57,9.36,8.98,8.44]
t = np.linspace(0, len(CM1)-1, len(CM1))
# 簡單線性回歸
A = []
for i in t:
temp = [1, i]
A.append(temp)
pinv_A = np.linalg.pinv(np.array(A))
coef = pinv_A.dot(np.array(CM1).reshape(len(CM1),1))
print(coef)
# 自回歸
self_A = []
for i in t:
if i == len(t) - 1:
break
temp = [1, i, CM1[int(i)]]
self_A.append(temp)
pinv_self_A = np.linalg.pinv(np.array(self_A))
CM1.pop(0)
self_coef = pinv_self_A.dot(np.array(CM1).reshape(len(CM1),1))
print(self_coef)


 iThome鐵人賽
iThome鐵人賽