
在前面的文章中,我們談到可以藉由混淆矩陣與衡量指標等工具來判斷目前建立出的機器學習模型在應用上是否適當,沒有造成偏見的問題,但是在實務上還有沒有其他更能反映現實狀況的方式,讓我們來據此做出更好的決策? 這邊課程中提出了一種以模擬決策進行與產生結果的方式,來知曉在各種情境下機器學習模型的產出是否符合我們所在意的標準,比如說準確率最高、帶來最高利潤或者是對不同群體來說相對最公平。
後續的模擬結果會以課程中提出的例子為範例,首先簡單說明一下該例子的情境(見圖1):
我們今天將貸放金額給兩個不同的群體(藍色與橘色群體),在預測上會有兩種情況,分別是決定貸款與否決貸款,而在真實值也會有兩種情形,分別是如期還款與無法償還,而貸款與否的判斷依據是根據機器學習模型針對個人所預測出來的一個貸款分數(範圍為0 ~ 100),搭配一個門檻值,藉由貸款分數與門檻值之間的關係來決定是否貸款,比如說貸款分數大於等於門檻值就通過貸款申請,反之則取消。另外在決策的成果上,一個成功的貸款(如決定貸款 + 如期償還)可以帶來300元營收,一個失敗的貸款(如決定貸款 + 無法償還)則會帶來700元的成本。
以下列出模擬在各種不同的情境下所會產生的結果:
根據以上之模擬結果,我們可以基於組織力求達成的目標來挑選適當之決策門檻,比如說如果我們在意的是利潤極大化,就可能會較傾向選擇情境2。但是如果今天我們要達成的目標是在總利潤足夠的情況下,對各不同群體來說也是相對公平的,就會選擇情境3,因為比起情境2來說,情境3對於不同群體而言,於會如期償還貸款的人來說,有同樣的比率通過貸款,是個較為公平的決策情境。
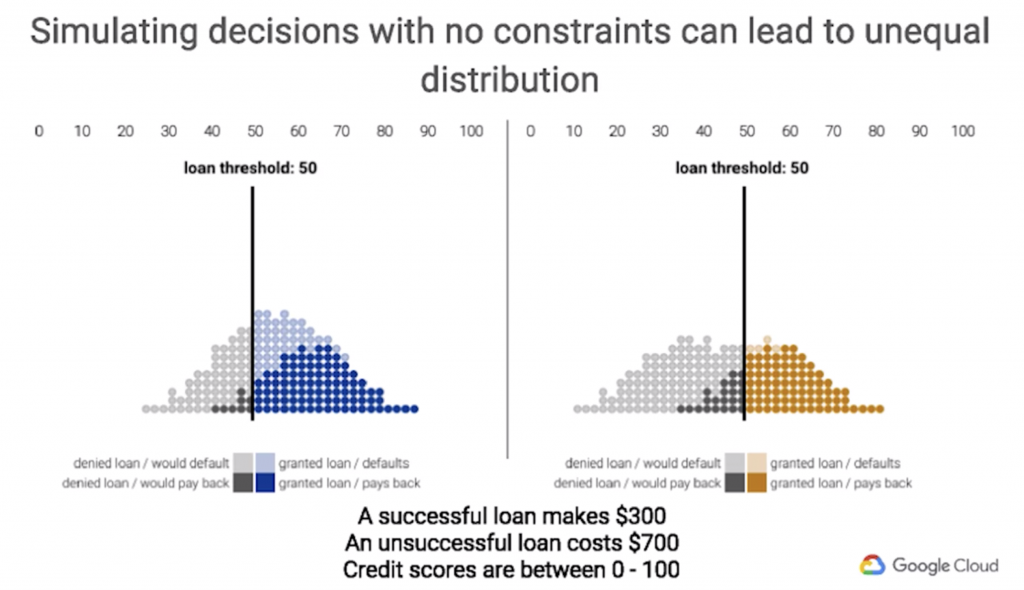
圖1
Source: Coursera - How Google does Machine Learning
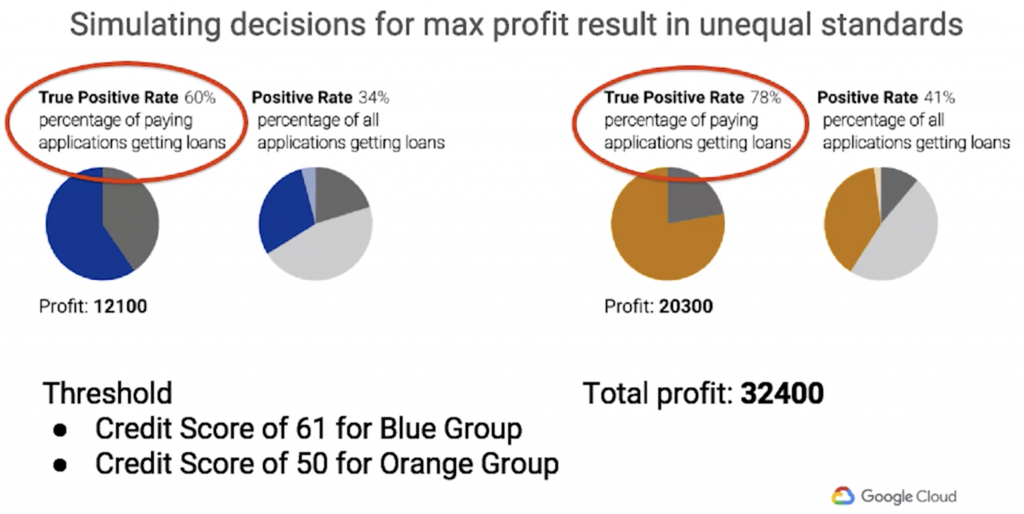
圖2
Source: Coursera - How Google does Machine Learning
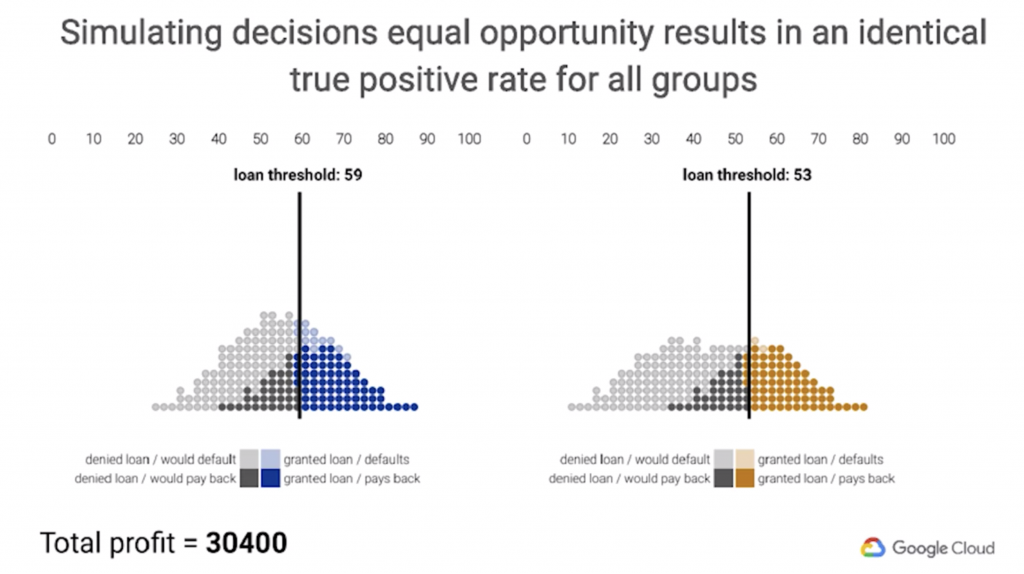
圖3
Source: Coursera - How Google does Machine Learning

 iThome鐵人賽
iThome鐵人賽