當今天層數越疊越深,若不做任何的處理機制,準確度其實是會越來越糟糕!因為當疊層數疊超過一個層數,會發生像Gradient vanishing或者說Degradation problem的問題。今天我們來使用TF 2.0來實作ResNet, 2016 年由Kaimei He提出的CNN架構,從VGG進一步的去修改,而他所提出的架構,可以讓層數達到非常深,且較不容易發生Gradient vanishing或者說Degradation problem的問題。過去,當深度學習層數變深的時候,會導致學習能力下降,結果沒辦法再繼續improve下去。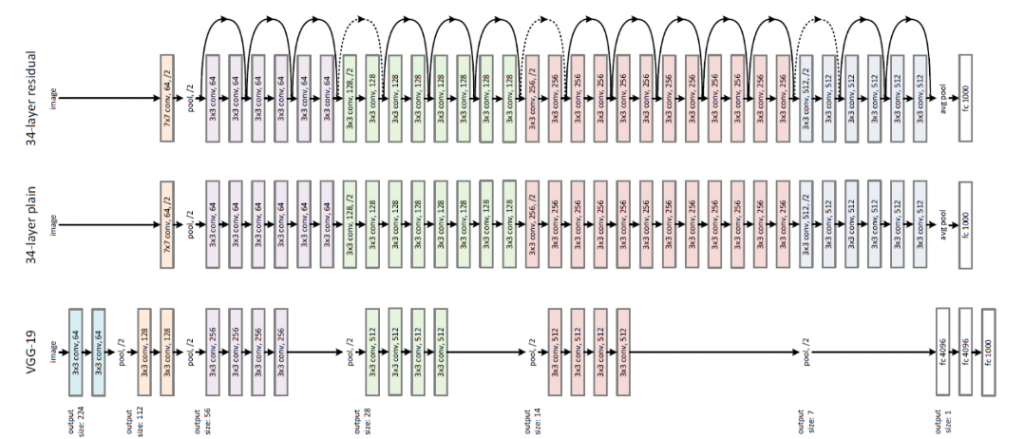
source
而ResNet中,最重要的就是使用了identity transform。簡單來說就是一個捷徑!這個捷徑會跳過當層,直接成為下兩層的 activation function 的input。而這個就為一個Residual Block的結構。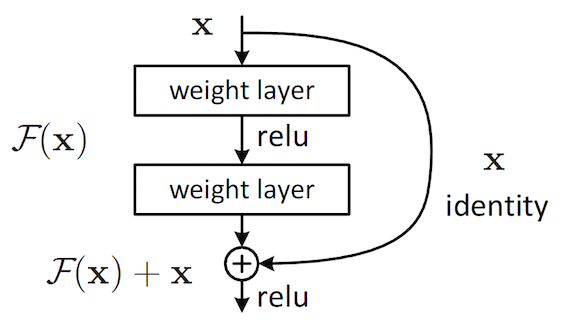
source
在實作的時候,直接的相加會有維度上不一致的問題,因次會有兩種解決方法,1. 用zero padding增加維度,然後downsampling (strides =2的pooling),這樣不會增加參數 2. 就是用 1X1 Conv來projection,這個方法的話就會增加參數。
下圖為ResNet的架構圖,而當初比賽就是使用152層的Model來使用。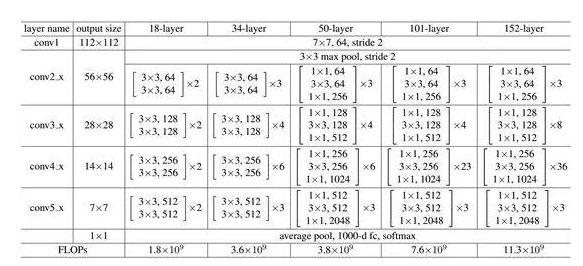
接下來,我們就來實作ResNet - 18
接下來我們來簡單實作CNN - ResNet 18,程式都是可以改成34或者其他更深的Model,這次也是使用CIFAR 10,這樣大家比較起來也比較好比較模型的差異。這次我們就直接跳過讀資料等等api,直接看重要的Residual Block跟ResNet!
主要的話就是要通過Convolution -> BatchNormalization -> Activation (Relu),然後重複一層。
接下來就是Shortcut的部分,這邊我們選擇使用1X1的Convolution來維持大小。Call function就是做一個forwarding的部分!
class ResBlock(layers.Layer):
def __init__(self, filter_nums, strides=1, residual_path=False):
super(ResBlock, self).__init__()
self.conv_1 = layers.Conv2D(filter_nums,(3,3),strides=strides,padding='same')
self.bn_1 = layers.BatchNormalization()
self.act_relu = layers.Activation('relu')
self.conv_2 = layers.Conv2D(filter_nums,(3,3),strides=1,padding='same')
self.bn_2 = layers.BatchNormalization()
if strides !=1:
self.block = Sequential()
self.block.add(layers.Conv2D(filter_nums,(1,1),strides=strides))
else:
self.block = lambda x:x
def call(self, inputs, training=None):
x = self.conv_1(inputs)
x = self.bn_1(x, training=training)
x = self.act_relu(x)
x = self.conv_2(x)
x = self.bn_2(x,training=training)
identity = self.block(inputs)
outputs = layers.add([x,identity])
outputs = tf.nn.relu(outputs)
return outputs
這邊的部分其實就是把他疊起來,透過一層一層的定義,以及用一個for迴圈來stack Residual Block
class ResNet(keras.Model):
def __init__(self,layers_dims,nums_class=10):
super(ResNet,self).__init__()
self.model = Sequential([layers.Conv2D(64,(3,3),strides=(1,1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPooling2D(pool_size=(2,2),strides=(1,1),padding='same')])
self.layer_1 = self.ResNet_build(64,layers_dims[0])
self.layer_2 = self.ResNet_build(128,layers_dims[1],strides=2)
self.layer_3 = self.ResNet_build(256,layers_dims[2],strides=2)
self.layer_4 = self.ResNet_build(512,layers_dims[3],strides=2)
self.avg_pool = layers.GlobalAveragePooling2D()
self.fc_model = layers.Dense(nums_class)
def call(self, inputs, training=None):
x = self.model(inputs)
x = self.layer_1(x)
x = self.layer_2(x)
x = self.layer_3(x)
x = self.layer_4(x)
x = self.avg_pool(x)
x = self.fc_model(x)
return x
def ResNet_build(self,filter_nums,block_nums,strides=1):
build_model = Sequential()
build_model.add(ResBlock(filter_nums,strides))
for _ in range(1,block_nums):
build_model.add(ResBlock(filter_nums,strides=1))
return build_model
接下來在train跟test的部分跟直接就一樣,大家可以參考Colab的程式!
看完了一些CNN重要的模型,接下來來看另一個Deep learning重要的模型RNN!
針對RNN我們會來玩情感分析跟股票預測~感謝大家漫長的閱讀。
除此之外,大家記得把Colab的GPU開起來train,速度會快很多~且也可以跑得動


