第 11 屆 iThome 鐵人賽
分享至
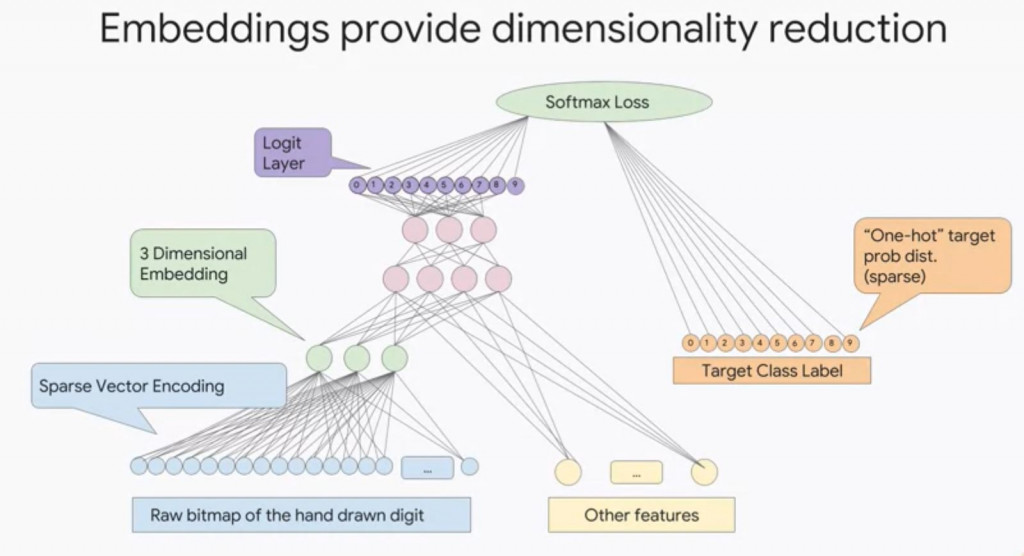
Embedding能降維、處理稀疏數據、協助模型泛化,說是極為強而有力的方法,潛在特徵(Latent Features)也在重複embedding的過程中順應而生,但一如我們得知方法loss function能協助我們優化模型一般,當時會面臨不知做到甚麼地步,隨著不斷的降維又該到何種地步呢?目前由rule of thimb(經驗法則)大概得到的結果是訓練資料開4根的結果
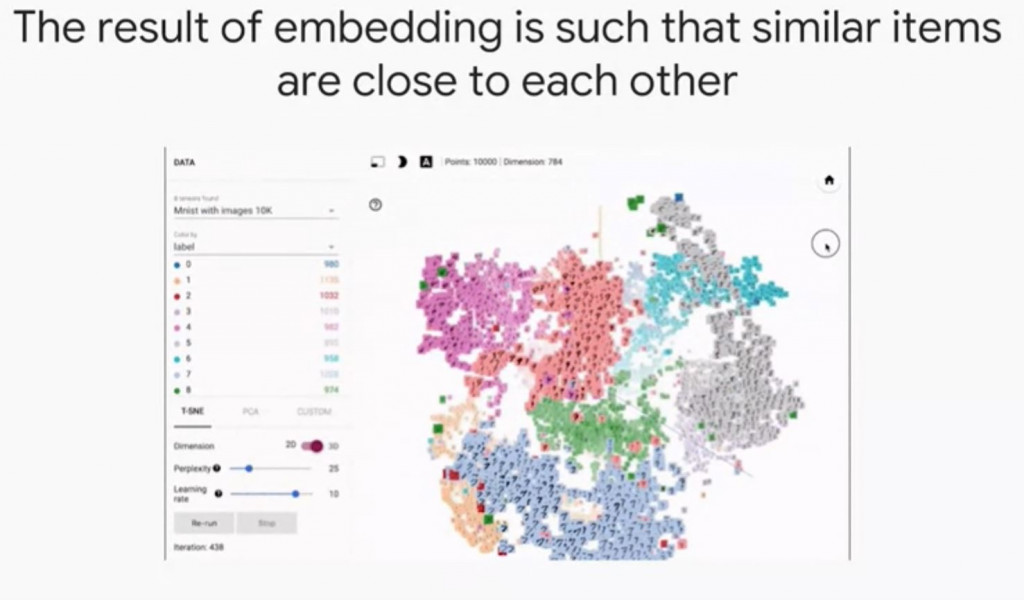
此外Tensor Board提供一個視覺化工具可以以3D方式觀察分群的狀況如圖
IT邦幫忙