今天我們來討論LSTM的應用,而其中一個最經典的案例就是情感分析(Sentiment Analysis)。而什麼是情感分析呢? 透過NLP或者Deep learning的模型來自動分辨網路上的評論是好還是壞。情感分析已經大量運用於輿情分析或者品牌分析等情境裡。情感分析主要有兩個步驟 1. 斷詞斷句 2. 情感分析模型。今天會使用Kaggle上的資料來跑LSTM。
資料欄位為以下
| 欄位 | 資料集內容 |
|---|---|
| target | 資料Label (negative = 0, neural = 2, positive = 4) |
| ids | ids Tweet |
| date | Tweets時間 |
| flag | Query Content (Ex: NO_QUERY) |
| user | 使用者Tweet |
| text | Tweet內容 |
資料下載的方式主要就是透過Kaggle api來下載
!kaggle datasets download -d kazanova/sentiment140
!unzip sentiment140.zip
(記得要先有kaggle的accout,跟API Token)
接下來就可以讀檔案,以及開始做一些簡單的前處理
sentiment140 = pd.read_csv('training.1600000.processed.noemoticon.csv',encoding='ISO-8859-1',header=None)
sentiment140.head()
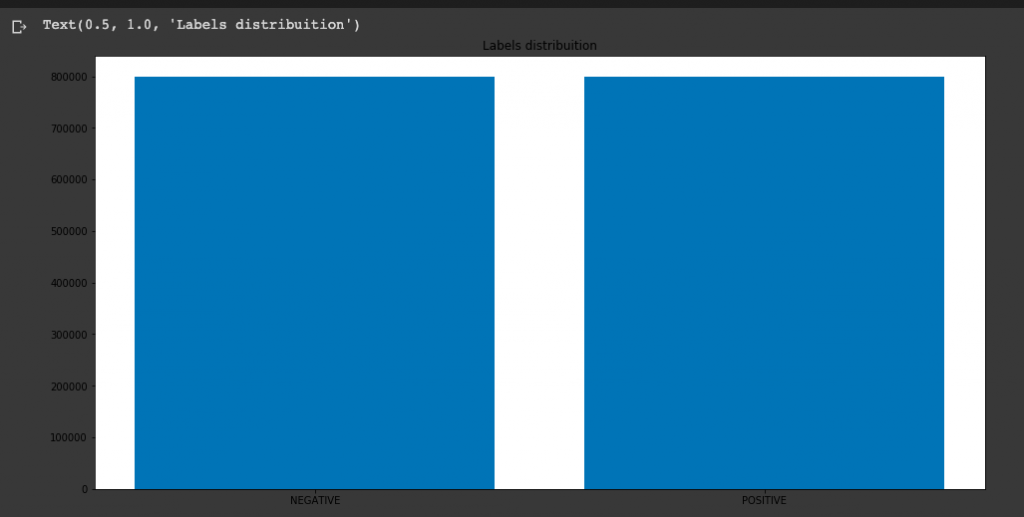
因此,我們可以簡單的的做一些前處理像是Drop不要的欄位,把Label合併,然後簡單的看一下Negative / Positive 資料數量差異
target_cnt = Counter(sentiment140.target)
plt.figure(figsize=(16,8))
plt.bar(target_cnt.keys(), target_cnt.values())
plt.title("Labels distribuition")
接下來就是Stop words的部分,這部分我們使用Natural Language Tool Kit (NLTK) 的python NLP的套件。此外,針對字詞處理的部分,我們也會去做詞幹(stemming)的處理 (Ex: automate , automatic , automation -> automat) 以及移除一些符號等。
nltk.download('stopwords')
stop_words = stopwords.words("english")
stemmer = SnowballStemmer("english")
text_remove = "@\S+|https?:\S+|http?:\S|[^A-Za-z0-9]+"
def preprocess(text, stem=False):
# Remove link,user and special characters
text = re.sub(text_remove, ' ', str(text).lower()).strip()
tokens = []
for token in text.split():
if token not in stop_words:
if stem:
tokens.append(stemmer.stem(token))
else:
tokens.append(token)
return " ".join(tokens)
sentiment140.text = sentiment140.text.apply(lambda x: preprocess(x))
針對Tokenizer的部分,可以直接使用tf.keras裡面的tokenizer
tokenizer = tf.keras.preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(df_train.text)
在train之前,記得要先做文字長度的限制,及padding成同樣長度,一樣可以使用tf.keras的api
x_train = tf.keras.preprocessing.sequence.pad_sequences(tokenizer.texts_to_sequences(df_train.text), maxlen=300)
x_test = tf.keras.preprocessing.sequence.pad_sequences(tokenizer.texts_to_sequences(df_test.text), maxlen=300)
接下來我們可以定義LSTM的Model了~首先會先將定義狀態,並且初始化為0,接下來會放到一個embedding layer來轉換,最後就可以放到LSTM並放到一個Dense層輸出機率。
class Simple_LSTM(keras.Model):
def __init__(self,units):
super(Simple_LSTM, self).__init__()
self.state_0 = [tf.zeros([batchsz,units])]
self.embedding = layers.Embedding(total_words,embedding_len,input_length=300)
self.layer_1 = layers.SimpleRNNCell(units,dropout=0.2)
self.out = layers.Dense(1)
def call(self, inputs, training=None):
x = self.embedding(inputs)
state_0 = self.state_0
for word in tf.unstack(x,axis=1):
out,state_1 = self.layer_1(word,state_0)
state_0 = state_1
x = self.out(out)
prob = tf.sigmoid(x)
return prob
最後可以直接使用api compile model就完成了!
rnn_model = Simple_LSTM(units)
rnn_model.compile(optimizer =keras.optimizers.Adam(1e-3),loss=tf.losses.BinaryCrossentropy(),metrics=['accuracy'])
rnn_model.fit(data,epochs=epochs, validation_data = data_test)
今天討論完LSTM情感分析的應用,明天我們來討論LSTM運用於股票預測的問題~應該是蠻多人想要理解的應用吧 ~