前面幾篇文章咱們已經學習完了資料層性能相關的知識,而接下來這篇文章,咱們要來學習,如何進一步的讓系統可以做更多的事情。
資料庫單機性能優化到最後,仍然還是逃不過性能的貧頸,但這並不是說單機優化沒有意義,因為單機如果沒有將它優化好,而直接開機器來增加性能,那只能說是拿錢堆起來的性能,而且可能會出問題。
那要如何在增加性能呢 ? 這時通常會使用以下的策略 :
緩存
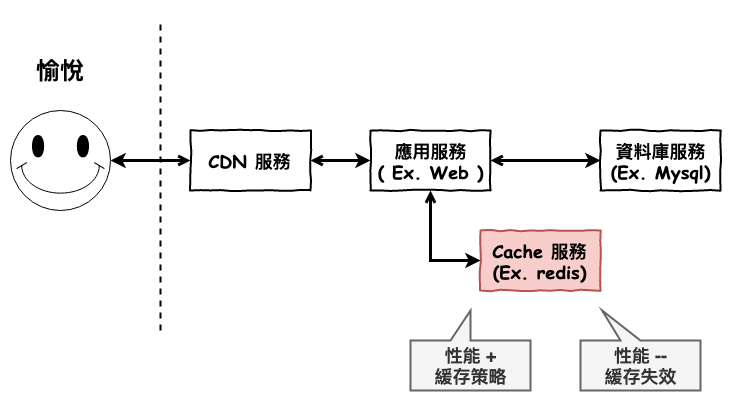
也就是說架構會變的如上圖 1 所示,在 mysql 前面會多增加一個緩存服務,這個服務我們通常會選擇用 redis。當資料在緩存服務有時直接回傳,沒有則去資料庫服務取得。
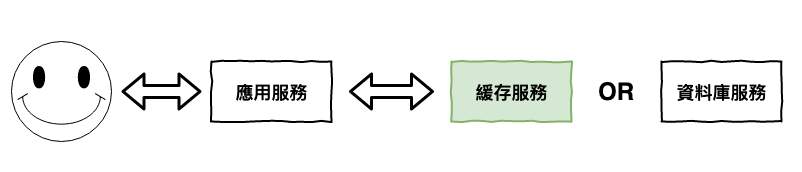
圖 1 : 加入緩存服務圖
在開始緩存策略前,咱們要先來研究一下基本的緩存服務『 redis 』。
本篇文章分為以下幾個章節 :
首先咱們簡單的介紹一下 redis 是啥 ?
簡單的說它算是一種資料庫,redis 是將所有的資料存在『 記憶體 』中,而 mysql 則是將主要資料存在『 硬碟中 』。
它適合當緩存服務的重點就在於儲『 記憶體 』。
而它適合當緩存服務的重點就在於這裡,它將資料儲放在記憶體,因此操作速度非常的快,咱們來簡單複習一下儲硬碟和記憶體取資料的差異,如下圖 2 所示,mysql 讀取資料,基本上要運行 3 次的拷貝,而 redis 則只需要 1 次 ( 每條線就是一次拷貝 )。
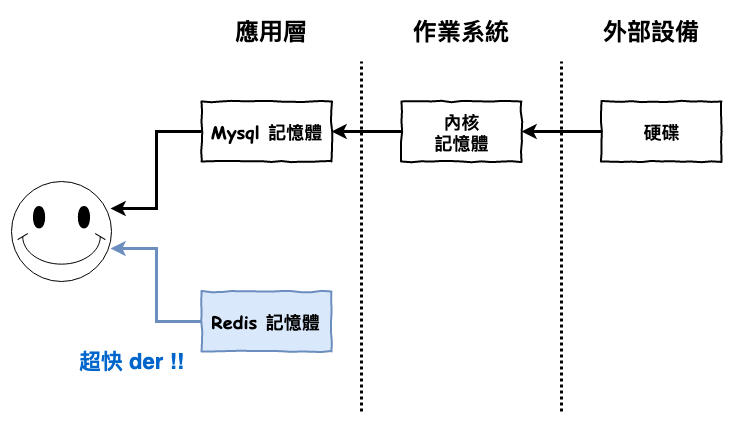
圖 2 : redis vs mysql 讀取資料比較
接下來看一下 redis 的架構,如下圖,基本上它是屬於單線程非阻塞 i/o 架構,也就是咱們之前文章所說的類型,詳細非阻塞 i/o 說明,請到那篇文章看看。
30-07 之應用層的 I/O 優化 - 非阻塞 I/O 模型 Reactor
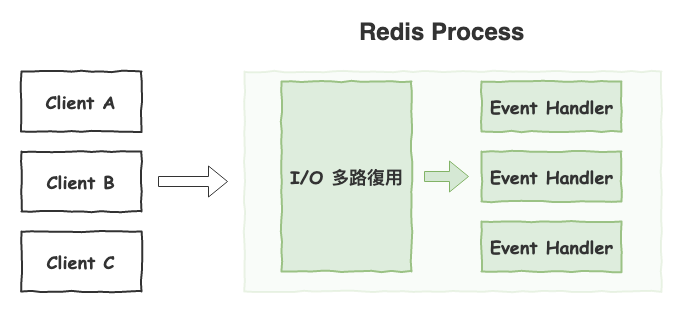
圖 3 : redis 的架構
問個問題 ~ 為什麼 redis 要選單線程的架構呢 ?
會選這種架構的主要原因在於 :
redis 不多 cpu 運算,而是比較多 i/o (網路) 處理。
有用過 redis 的友人應該都知道,咱們使用 redis 時後,大部份就是指定某個 key 然後來抓取資料。
redis> GET {key}
它幾乎不會像 mysql 那樣會有一些很複雜的運算啥的操作,它就只是單純的指定 key 然後拿取,因此這種情況下,它如果選擇用多線線來處理多 i/o 情境下反而會有以下的缺點 :
因此因為這些些原因,redis 才選擇這種單線程非阻塞 i/o 架構。
redis 有沒有前幾篇 mysql 的一致性難題呢 ?
30-15 之資料庫層的難題 - 單機『 故障 』一致性難題
30-16 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 1 )
30-17 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 2 )
嚴格來說少了非常的多。
先說一下『 並行 』的難題。這個在 redis 中是沒這煩腦的。
主要的原因在於 :
redis 它是 single process 且 single thread 架構,所有它沒有並行的問題
這事實上也代表這 redis 的事務有 acid 中的 :
隔離性
acid 中的隔離性所代表的意思為,多個事務『 並行 』執行時,不會相互的影響到對方,而當 redis 的結構為單進程時,就代表所有的事務只能『 串行 』處理,所以它當然有這個特性。
圖 3 : redis 的事務執行圖
那另一個固障不一致性難題呢 ?
這個問題事實上還是有的。
首先 redis 中也有提供『 事務 』這一種概念,然後接下來咱們來看看固障各種情境。
這種情況如下圖 4 所示,也就是第二個操作失敗了。
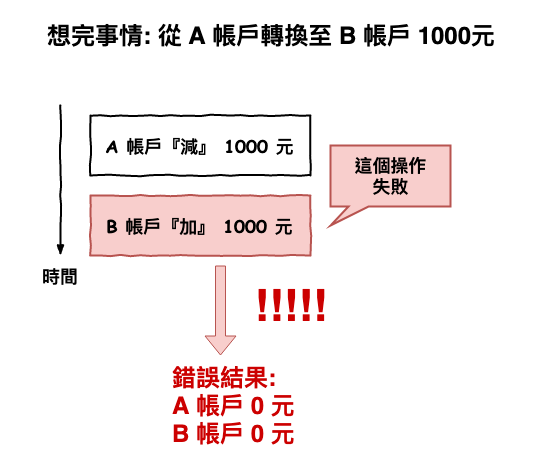
圖 4 : 某項操作故障導致不一致
在 mysql 的文章中,咱們有提到它的解決方法為 :
事務 + undo log
所以當 mysql 第二個操作出了問題,它可以使用 undo log 來回復資料庫。
而在 redis 中它也有提供事務,它的使用方式如下 :
MULTI
SET A-Account "0"
SET B-Account "1000"
SET C-Account "1000"
EXEC
上面指令,它在 redis 實際上的運行流程如下。事實上就只是將操作寫入到 redis 的隊列中,然後 exec 時在一個一個執行,這樣也代表同一個時間,只會此事務的所有操作,中間不會有其它事務的操作。
MULTI ( 開始事務 )
SET A-Account "0" ( 加入隊列 )
SET B-Account "1000" ( 加入隊列 )
SET C-Account "1000" ( 加入隊列 )
EXEC ( 執行隊列操作 )
但這裡咱們就要來想想一件事情。
redis 執行 exec 後,在執行第二個 set 指定失敗會怎麼樣呢 ?
它會執行第三個
對 redis 的事務沒有所謂的『 要麻全完成 』或『 要麻全失敗 』這個概念。
它的事務只是用來保證同一個時間內只會執行該事務的操作,而不會被其它事務所影響。
所以這也代表 redis 的事務它事實上沒有所謂的原子性,因為它沒有保證事務內全部完成,或全部不完成。
redis 事務沒有所謂的『 原子性 』
這裡簡單在提一下,但如果是在發送隊列時出錯,那就整個事務不會處理,所以這裡就有『 全部不完成 』這點,但整體而言,它還是沒辦法包證全部都有『 全部完成 』與『 全部不完成 』這個原子特性。
這個問題在 mysql 的問題是如下圖 5 所示,在事務提交以後,寫到緩衝區後,如果機器炸了,那資料會移失的。
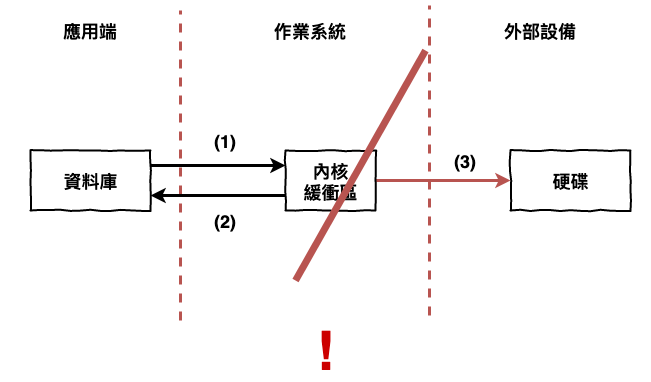
圖 5 : mysql 單機故障導致一致性問題。
那 redis 由於都是存在應用層的記憶體中,那這樣 redis 服務重開不是就炸了 ?
嗯對,基本觀念沒有錯,任何的應用程式,如果重開了,那記憶體裡的資料是會不見沒錯,所以 redis 它有提供兩個持久化機制,如下 :
簡單的說它是一個『 自動 』或『 手動 』的將記憶體資料,保存到硬碟的 dump.rdb 去。當 redis 重開時,它會將硬碟 dump.rdb 資料拷貝到記憶體中。
RDB 的預設自動條件如下 :
只是上述一個條件有中,就會將記憶體中的資料寫到硬碟去。會有這種預設主要是因為拷貝到硬碟對 redis 是很吃資源的事情,所以不太可能每一秒就拷貝到硬碟一次,所以這也帶出了它的缺點 :
RDB 如果要復原,那不太可能是前幾秒的事情,最低也只能回復到 1 分鐘前 ( 如果有觸發條件的話 )
簡單的說,它會將『 寫 』的操作,記錄到日誌中 ( 有點像 mysql undo ),當 redis 重啟時,就使用這個日誌來回復。
這個機制預設基本上『 每秒 』寫入到日誌上,而所謂的日誌就是指寫到硬碟,某些方面你可以想成它是用性能來換取,回復資料一致性較高的策略。
不 ! 沒有 !
因為你即使 redis 事務提交了,但根據 rdb 與 aof 上面的說明,你仍然還是會有一小段的資料會消失。
所以它仍然會發生上圖 5 的問題。
所以以 acid 特性來看 :
redis 它沒有持久性,因為它沒辦法保證事務『 提交 』後,資料有保存下來
從這章節的幾個段落可以得知,redis 雖然有『 事務 』,但這個事務事實上沒有符合『 ACID 』特性。
因為它只有符合 :
而以下兩個則沒有符合 :
而前一篇文章也說到事務 acid 的特性公式為 :
一致性 C = 隔離性 I + 原子性 A + 持久性 D
所以這也代表 redis 的事務也沒有符合 acid 的『 一致性 』
~ 小備註 ~
這裡或需有人會說,redis 的有些操作有原子性,嗯沒錯,但我這裡說的是『 事務 』沒有符合原子性。
redis 有提供以下幾種資料結構來進行儲放,而咱們要用的好的要點之一,就是你要知道每一種操作的時間複雜度,然後更進階點就是要理解,為什麼會是這個時間複雜度。
這裡建議看下列這篇文章,它已經整理的很詳細了。
假設你有一個操作如下,這裡以 php 為範例如下,它要執行 set 100 次 :
$client = new Predis\Client();
for ($i = 0; $i < 100; $i++){
$client->set("key:$i", 'test');
}
那這種情況建議改成使用 pipeline,因為這樣它就只會發『 一條 』指令給 redis,而這時網路的 latency 與傳輸資料就會減少非常多,如下圖 6 所示。
$responses = $client->pipeline(function ($pipe) {
for ($i = 0; $i < 100; $i++) {
$pipe->set("key:$i", 'test');
}
});
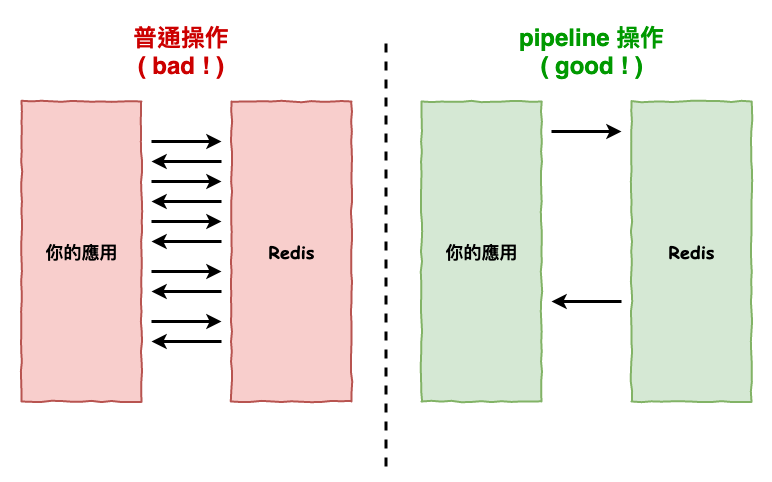
圖 6 : 大量操作情況下,正常操作與 pipeline 比較圖。
redis 有提供一個指令為 keys,它可以幫你找出你要的 pattern 的 key,如下範例。
KEYS { pattern }
Ex.
KEYS /users/*
但是這個指令非常的危險,因為假設資料量很大,然後你一執行這個指令可能要 1 分鐘,那這時就代表這 :
這一分鐘內你的 redis 沒有辦法處理任何請求
事實上這就是單線程架構缺點,當你進行 cpu 操作時間太長,那就會卡住所有的操作。
所以當如果要進行類型這種操作請使用 :
請使用 scan,不要用 keys
因為 scan 是跑一下,讓出來一下,在跑一下,雖然整體查詢時間會拉長,但是至少不會卡住所有操作。
會這樣建議的原因主因在於 :
儘可能讓 key 的數量保持在一定數量
當數量大時,可能會發生以下情況 :
雖然有人會說,咱們在使用時,業務上的操作都會清除 key,例如用戶離線會清,不會有沒清除掉的,但是事情總是沒有想的如此的美好。如果開發時沒考慮到一些特殊情況,又或是沒有注意到忘了處理,你就會發現 redis 變成你不認識的樣子了。
本篇文章介紹了網存服務應用 redis 的一些基本知識與一些使用上的小心得,而事實上這些建議事項與知識都和前面的文章有相關,例如 :
redis 架構,就與下面這一篇文章有關。
30-07 之應用層的 I/O 優化 - 非阻塞 I/O 模型 Reactor
而建議 1 熟細操作時間複雜度,就和下面這篇有。
還有持久化機制 : 就和這一篇有關。
30-15 之資料庫層的難題 - 單機『 故障 』一致性難題
這裡事實上會發現,都是我們之前有學習過的東西,而大部份的系統也都由這些知識建構起來,因此這三十天通了,那事實上你也幾乎可以說通了大部份的系統,這樣你在接下來的學習就會變的非常快,因為它們的基本原理都是相同的東西。
學久了,就會發現系統的知識每一個都是串連起來的。
這個問題在 mysql 的問題是如下圖 5 所示,在事務提交以後,寫到緩衝區後,如果機器炸了,那資料會移失的。
之前的文章有提到,雖然資料會遺失,但下次開啟 mysql 可以使用 redo log 將遺失的部分恢復,這邊也適用嗎?
不太適用喔 ~
首先 mysql 是 commit 已後,將資料寫入到 redo log 後,才回 ack。之後再將資料寫入到『 要實際存資料的地方 』。
而 redis 你可以想成它在 commit 已後,會將資料寫到記憶體中,就回 ack。之後再根據 rdb 或 aof 的機制某一段時間在寫入到某個 log 中。
所以 redis 在 commit 後,寫到記憶中,但還沒寫到 rdb 或 aof 的 log 檔前炸掉,資料還是會掰的,就算重啟也一樣,因為 rdb 或 aof 沒有更新的資料。
清楚了,感謝大大說明。 

