昨天提到消失的那些傢伙,關於objcet這些傢伙該怎麼處置呢?繼續看下去!
編碼在機器學習中是相當重要的,而且在一開始的資料處理、整合就必須使用到了,尤其是當我們需要將分類文本特偵轉換成數字時更是需要這項技術。原因是不管我們在做任何的機器學習,不外乎最終目標就是找到那個模型,而先前介紹到的許多方法都是從數學式子開始的,如果你今天給個街道名稱"Pave",或是在做圖片辨識(貓或狗)也給"cat"、"dog",機器根本就不會認識它是什麼,所以這時候我們就要編碼了!以下是常見的編碼方式:
One-Hot代表就是只有其中一個數字是1其餘都是0,可以說是靠位子來判別。
就像是今天要做分類的機器學習,有三個腳色(John,Jason,Jenny)必須要做One-Hot-Encoding,那會變成怎樣呢?
那會變成:
John = [ 1 0 0 ]
Jason = [ 0 1 0 ]
Jenny = [ 0 0 1 ]
實作一下:
import pandas as pd
name = ['John','Jason','Jenny']
df_data = pd.DataFrame(name)
print(df_data)
#以上是基本的建立資料
one_hot_data = pd.get_dummies(df_data)
#Pandas裡面有get_dummies函數,可以直接進行One-Hot Encoding
pd.DataFrame(one_hot_data)
輸出: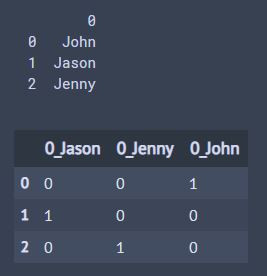
Label Encoding更簡單了,它是直接利用數字去判別!那它會跑出來的數字會是0到n(原本種類-1)舉個例子,跟上面一樣有三個腳色(John,Jason,Jenny),那就會變成:
John = 0
Jason = 1
Jenny = 2
也來實作一下:
import pandas as pd
name = ['John','Jason','Jenny']
df_data = pd.DataFrame(name)
print(df_data)
#以上是基本的建立資料
from sklearn.preprocessing import LabelEncoder #導入LabelEncoder工具
df_data[0] = LabelEncoder().fit_transform(df_data[0])
#LabelEncoder()只能鎖定一行,所以要特別標註是哪行
df_data
輸出: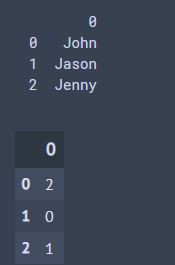
float_data = trian_corr.index #是float或int的的傢伙
all_col = df_train.columns #全部的col
object_data = []
for i in range(len(all_col)): #查找全部的all_col,len(all_col)是長度(要全部找過一遍)
if all_col[i] not in float_data: #如果在float_data裡面沒有,表示它是object幫的
object_data.append(all_col[i]) #不是就加上去
print(len(object_data))
print(object_data)
輸出:
43
['MSZoning', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', 'KitchenQual', 'Functional', 'FireplaceQu', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'PavedDrive', 'PoolQC', 'Fence', 'MiscFeature', 'SaleType', 'SaleCondition']
因為我們只要查看object與售價的相關度,所以把同一行不同種的分開標記就好!
from sklearn.preprocessing import LabelEncoder
#df_train[pd.isnull(df_train)] = 'NaN'
for i in object_data: #將轉換是object的傢伙轉換,從object_data陣列一個一個抓出來改造
df_train[i] = LabelEncoder().fit_transform(df_train[i].factorize()[0])
#pd.factorize()[0]會給nans(缺失值)一個-1的值,若沒寫這個,會造成等號兩邊不等的情況
df_train
輸出: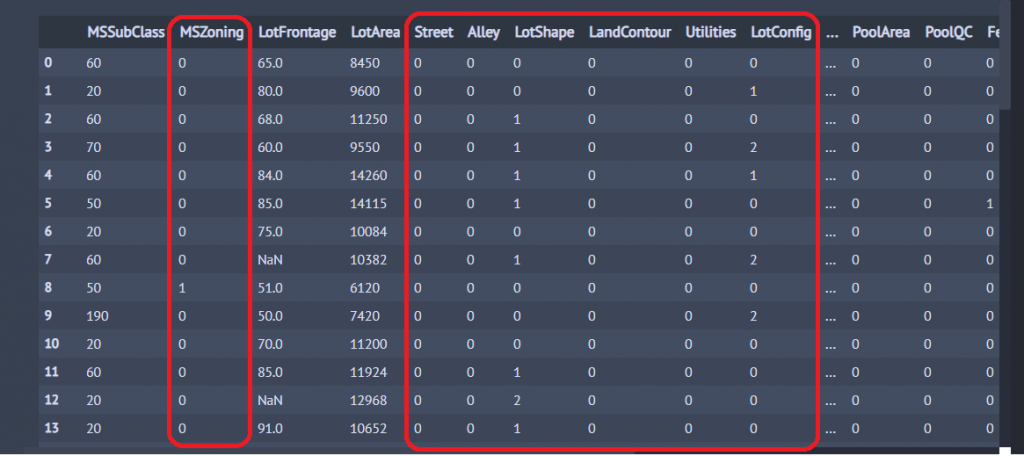
可以看到紅框框原本是object的形式,現在全部變成數字拉~這樣就可以進行相關係數分析了!
import seaborn as sns
trian_corr =df_train.corr() #計算相關係數
print(trian_corr.shape) #查看形狀
plt.subplots(figsize=(30, 10)) # 設置長寬尺寸大小
sns.heatmap(trian_corr, annot=True, vmax=1, cmap="Blues")
輸出: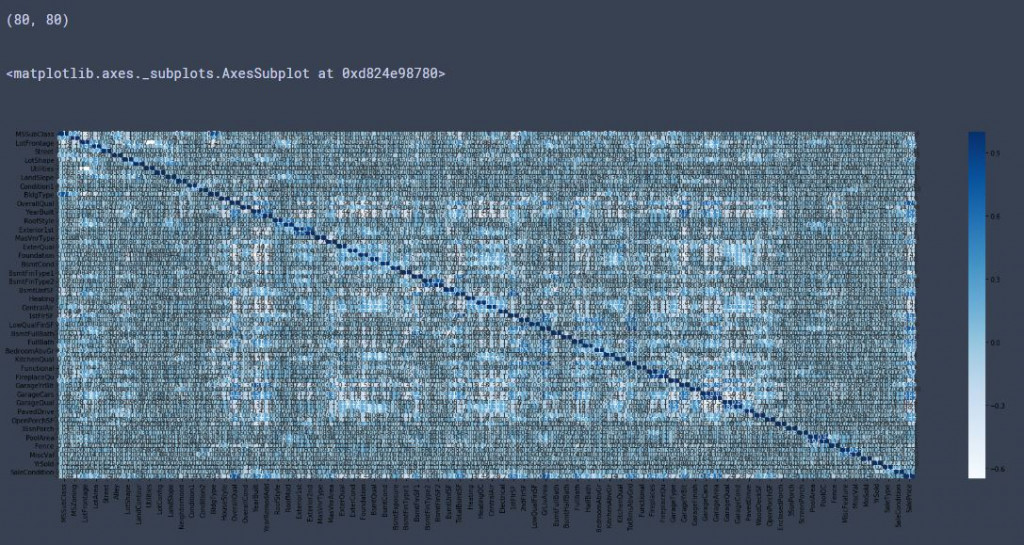
有沒有看到相關係數矩陣形狀變成80*80拉~
然後再一樣找出相關度高點的:
high_corr = trian_corr.index[abs(trian_corr["SalePrice"])>0.6]
#abs是取絕對值的意思
#abs(trian_corr["SalePrice"])>0.6 這句的意思是與SalePrice有關的係數>0.6的判別式,它會輸出True(大於0.6)或是False
#abs(trian_corr["SalePrice"])>0.6 會丟回一堆True和False,放在原本的trian_corr.index[]就會把是大於0.6的傳回去
print(high_corr)
輸出:
Index(['OverallQual', 'TotalBsmtSF', '1stFlrSF', 'GrLivArea', 'GarageCars',
'GarageArea', 'SalePrice'],
dtype='object')
然後你點回去看DAY222,do re mi so~竟然跟原本啥都沒做找到大於0.6的種類一樣,就是那幾行!!!
沒錯沒錯,大失所望嗎?其實還有另一種方法就是快速瀏覽一下object的那些行,你會發現全部object行的種類根本沒幾個,大部分就三個以下,三個以下的種類要怎麼能跟1460筆的Saleprice呈現很大相關度呢?所以當然還是原本float和int幫最容易影響囉!
今天真是耗了滿大的力氣去完成這篇壓,可能最後你會罵髒話 ,但是這樣做才可以順便了解編碼這回事~明天會開始對資料進行捨棄、以及些相關處理,繼續努力!
,但是這樣做才可以順便了解編碼這回事~明天會開始對資料進行捨棄、以及些相關處理,繼續努力!


 iThome鐵人賽
iThome鐵人賽