祝大家雙十節快樂!連假愉快!
昨天提及了怎麼處理資料中不是float或者是int的方式,也順便提及encoding的方法,那下一步呢?之前在【Day 21】有提到「驗證集」的概念,它可以幫助我們獲得更好的準確率,讓我們在逼近最佳模型的時候能夠進行評估修正!但是,看了看資料夾(下面這張圖)
啊我的驗證集資料呢!?明顯的,資料提供者並沒有事先幫我們分好,所以我們必須自己切分囉~
來切分JOHN國的10筆資料!
id | price | sqft_living
------------- | ----------
1 | 500000 | 55
2 | 275000 | 27
3 | 360000 | 33
4 | 780000 | 70
5 | 145000 | 13
6 | 280000 | 26
7 | 860000 | 89
8 | 200000 | 21
9 | 90000 | 10
10 | 680000 | 67
import numpy as np
from sklearn.model_selection import train_test_split
x_data = np.array([55,27,33,70,13,26,89,21,10,67])
y_data = np.array([500000,275000,360000,780000,145000,280000,860000,200000,90000,680000])
print("x_data",x_data)
print("y_data",y_data)
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=0)
#X_train,X_test, y_train, y_test = model_selection.train_test_split(train_data,train_target,test_size=0.2, random_state=0)
#train_test_split的括號裡面,1.資料的x那些種類2.y的部分3.test的部分要佔全部資料的多少4.指定一個隨機種子,0的話就是隨機囉
#就是一種隨機切分資料的功能
#隨機種子相同的話,在另一個框框在跑一次一樣的code還是會出現相同的隨機數
print("X_train",X_train)
print("y_train",y_train)
print("X_test",X_test)
print("y_test",y_test)
輸出:
x_data [55 27 33 70 13 26 89 21 10 67]
y_data [500000 275000 360000 780000 145000 280000 860000 200000 90000 680000]
X_train [13 67 27 89 21 70 55 26]
y_train [145000 680000 275000 860000 200000 780000 500000 280000]
X_test [33 10]
y_test [360000 90000]
會看到因為我的test_size設成0.2,所以原本10筆資料被隨機切分成train有8筆,test則是2筆,這樣就切分成功拉!
for i in df_train.columns: #查找原本資料中所有columns
if i not in high_corr: #如果沒有相關係數大於0.6的話
df_train = df_train.drop(i,axis=1) #就把它拔掉
print(df_train)
輸出: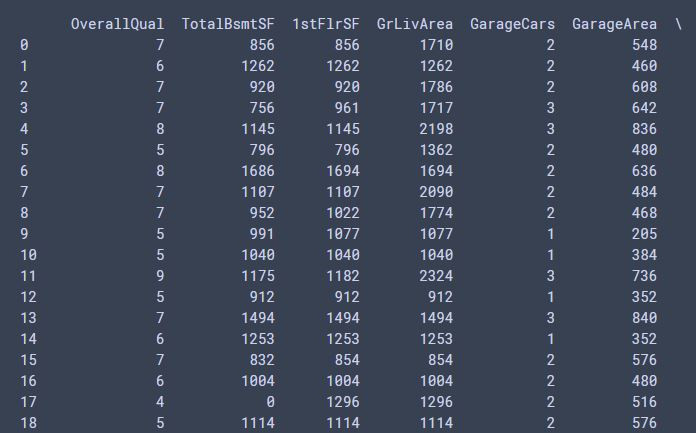
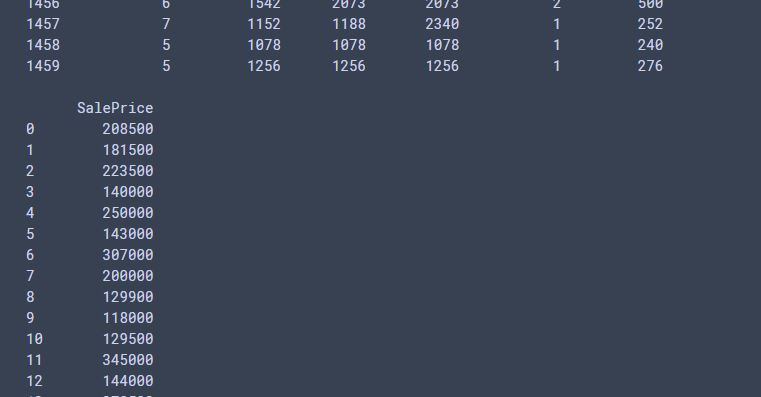
所以剩下的都是和SalePrice相關係數大於0.6的行們
我們要先把SalePrice拿出來當作Y,才能用預測值跟真的Y(SalePrice)比較。什麼什麼,你不知道我在說什麼嗎?可以回去看【Day 06】,可以複習一下基礎的概念哦!那我們就來取出吧!
train_targets = df_train["SalePrice"].values #把SalePrice這行數值整個拉出來
train_data = df_train.drop(columns=["SalePrice"]) #刪除SalePrice這行
print(train_targets)
print("*"*50)
print(train_data)
輸出: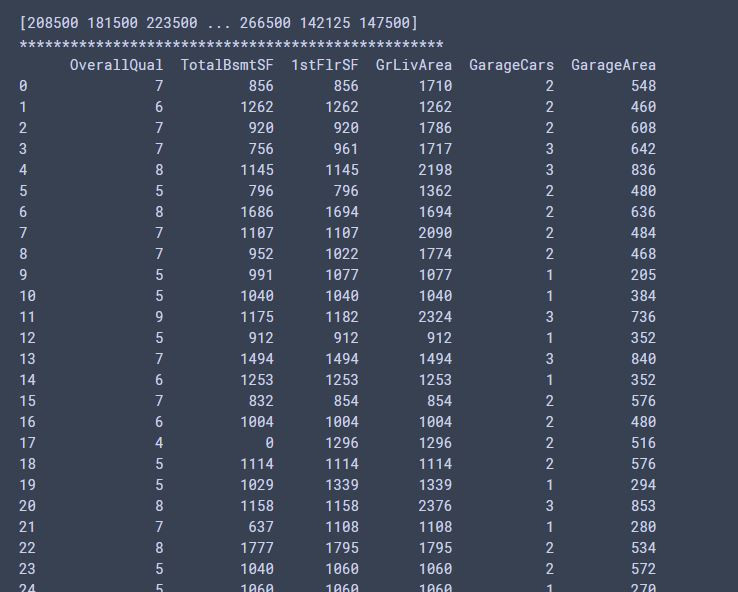
from sklearn.model_selection import train_test_split
X_train,X_validation,Y_trian,Y_validation = train_test_split(train_data, train_targets, test_size=0.2, random_state=0)
#X_train,X_test, y_train, y_test = model_selection.train_test_split(train_data,train_target,test_size=0.2, random_state=0)
#train_test_split的括號裡面,1.資料的x那些種類2.y的部分3.X_test的部分要佔全部資料的多少(我們這裡是驗證集唷)4.指定一個隨機種子,0的話就是隨機囉
#就是一種隨機切分資料的功能
#隨機種子相同的話,在另一個框框在跑一次一樣的code還是會出現相同的隨機數
print(X_train.shape)
print(Y_trian.shape)
print('*'*50)
print(X_validation.shape)
print(Y_validation.shape)
X_train_dataset = X_train.values #取出數值,轉換回list
X_validation_dataset = X_validation.values
print(X_train_dataset)
輸出:
(1168, 6)
(1168,)
**************************************************
(292, 6)
(292,)
[[ 9 1822 1828 1828 3 774]
[ 5 894 894 894 1 308]
[ 5 876 964 964 2 432]
...
[ 6 0 1318 1902 2 539]
[ 7 1374 1557 1557 2 420]
[ 7 1195 1195 1839 2 486]]
明天就要進入資料處理的尾端囉,明天會講述些許的視覺化以及資料標準化的過程!繼續努力囉~


 iThome鐵人賽
iThome鐵人賽