參考資料:
1. 深度學習-物件偵測:You Only Look Once (YOLO)
2. YOLO(You Only Look Once)算法详解
3. YOLO Object Detection with OpenCV and Python
• 使用OpenCV進行影像預處理(通道轉換、標準化、資料增加…)
在終端 pip install opencv-python
#查看引入OpenCV庫時是否報錯import cv2
#查看安裝的版本cv2.__version__
然後知道一些基本可以做的事情例如:
參考:9段代碼詳解圖像變換神操作,一文看懂OpenCV
#先注意: opencv默認讀取的圖片矩陣是BGR格式(不是RGB)
• CNN model實作解說
#完全不懂是要CNN實做啥,但我想就是跟YOLO有關吧?所以
下圖為YOLO論文內的所用的CNN架構
[AI#4]卷積神經網路(CNN)
YOLO的卷積網路架構是來自GoogleNet的模型,YOLO的網路有24卷積層(convolutional layer)和2層全連結層(fully connected layer),和GoogleNet不同的地方在於作者在某些3×3的卷積層前面用1×1的卷積層來減少filter數量
• 主題式物件辨識(object detection)
#YOLO物件偵測怎麼做的
YOLO在物件偵測部分基本上就是將圖拆成很多個grid cell,然後在每個grid cell進行2個bounding box的預測和屬於哪個類別的機率預測,最後用閾值和NMS (Non-Maximum Suppression) 的方式得到結果。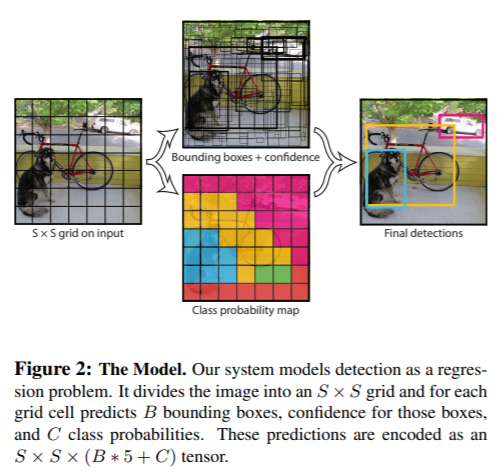
• 影像Lable方法解說
首先在終端安裝pyqt conda install pyqt=5
然後,Label軟體我們使用的是LabelImg
從 https://github.com/tzutalin/labelImg 下載並執行該軟體。剛執行時畫面是空的,請按「Open Dir」、「Change Save Dir」選擇剛剛建立的images以及labels資料夾,接下來便可從下窗格中選擇要label的相片,「按下Create RectBox」便可開始label。
#或使用指令步驟:git clone https://github.com/tzutalin/labelImgcd lableimgpython lableimg.py
該pip install就pip
#使用快捷鍵
W-->建立Bounding box
A-->上一張
D-->下一張
Ctril+S-->存XML檔
• YOLO模型教學
首先祭上官網: https://pjreddie.com/darknet/yolo/
再祭上論文: You Only Look Once: Unified, Real-Time Object Detection
#三個YOLO重要的步驟:

• YOLO模型實作解說
神文: 建立自己的YOLO辨識模型 – 以柑橘辨識為例
接續神文: 如何快速完成YOLO V3訓練與預測

