參考資料:
1. 基於python語言使用OpenCV搭配dlib實作人臉偵測與辨識
2. MTCNN算法及代码笔记
3. 人脸识别:FaceNet论文详解
#人臉辨識大致可分成以下四個主要的步驟:
• 人臉偵測mtcnn(Multi-task Cascaded Convolutional Networks)、opencv、dlib解說
#MTCNN
先祭上(目前看過最短的)論文: https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf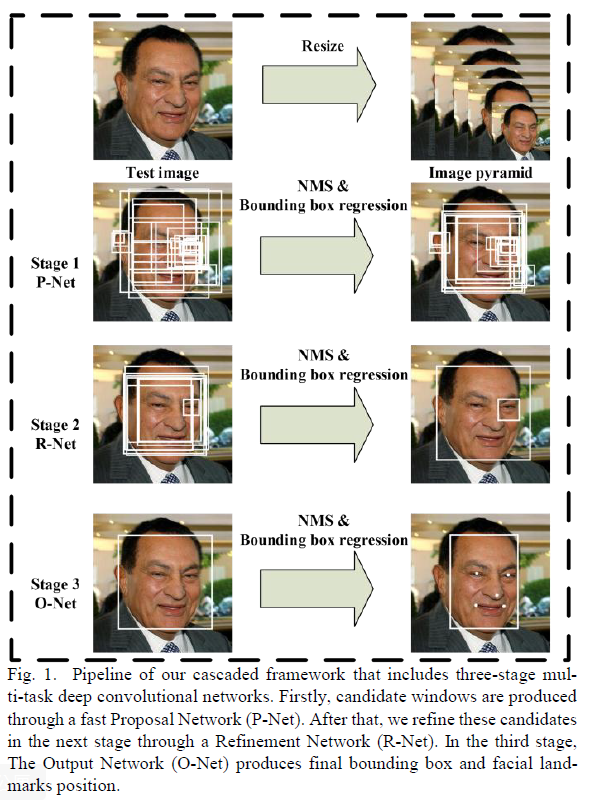
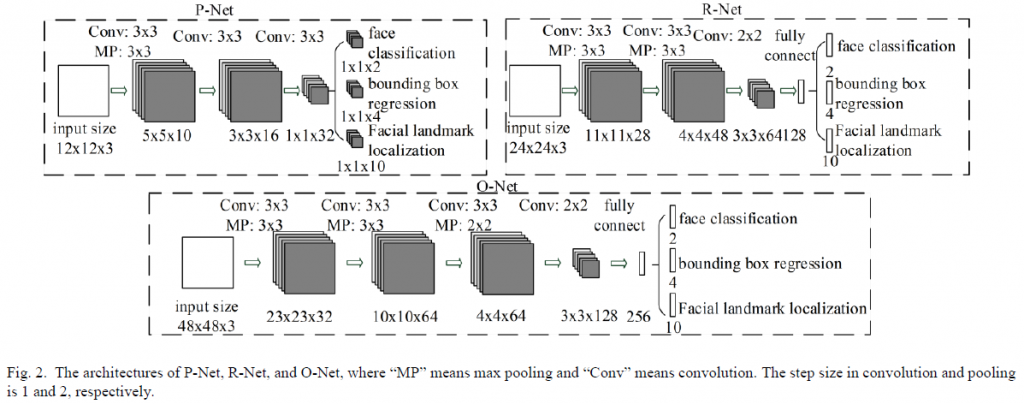
Cascaded了三個子網路為:Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net),這3個stage對人臉的處理是按照一種由粗到細的方式。
首先,P-Net主要用來生成一些候選框(bounding box);
然後R-Net主要用來去除大量的非人臉框;
最後O-Net也是去除非人臉但還增加了landmark位置的回歸。
#OpenCV的全名是Open Source Computer Vision Library,是一個跨平台的影像函式庫,OpenCV可用於開發即時影像處理。pip install numpypip install matplotlibpip install opencv-python
#Dlib是一套使用C++語言所編寫的函式庫,主要可應用在機器學習、影像處理,以及影像辨識等等,他開源而且免費,基於BSD授權條款。pip install numpypip install scipypip install scikit-imagepip install dlib
• 資料前處理:人臉轉換、對齊與裁剪…
#LFW資料集是一個常見的人臉資料集,歷史非常悠久。LFW資料集中收錄了5749位公眾人物的人臉影像,總共有超過一萬三千多張影像檔案。但大部份公眾人物的影像都只有一張,只有1680位有超過一張照片,而極少數有超過10張照片。網站: http://vis-www.cs.umass.edu/lfw
#以指令來說,我們利用Tensorflow的Facenet模型
1)經過偵測、對齊 & 裁剪後的人臉圖像目錄,來取得人臉類別(ImageClass)的列表與圖像路徑;
過濾: 取得每個人臉圖像的路徑與標籤 (>=5)
2)載入Facenet,開始處理人臉特徵向量...
• 人臉特徵擷取(使用FaceNet的模型與演算法)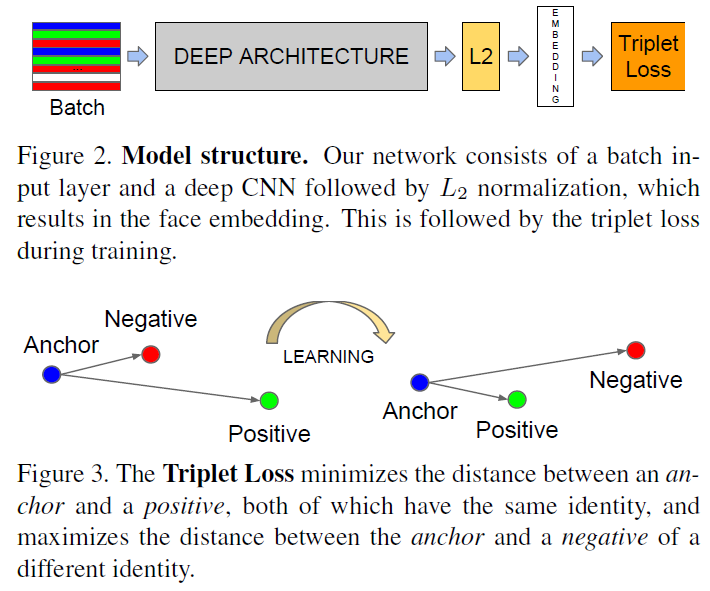
FaceNet並沒有用傳統的softmax的方式去進行分類學習,然後抽取其中某一層作為特徵,而是(Triplet Loss)直接進行端對端學習一個從圖像到歐式空間的編碼方法,然後基於這個編碼再做人臉識別、人臉驗證和人臉聚類等。
#如圖所示:Deep Architecture就是卷積神經網絡去掉sofmax後的結構,經過L2的歸一化,然後得到特徵表示,基於這個特徵表示計算三元組損失。
#所謂的三元組就是圖示那三顆(anchor, pos, neg)
假設: x和p是同一類,x和n是不同類。那麼目標是使得anchor和pos的距離 '小於' anchor和neg的距離。
#總之,
大部份其它的演算法是: 先輸出高維度特徵向量,然後用PCA等降維,再用分類器分類。
而FaceNet直接使用基於三元組的LMNN(最大邊界近鄰分類)的損失函數訓練神經網絡,網絡直接輸出為128維度的向量空間。
• 人臉特徵比對 (使用LinearSVC的分類演算法)
#是一種SVM,而做SVM前最重要的是要對數據做標準化處理!
因為SVM算法中的'計算Margin距離',如果數據點在'不同的維度上'的量綱不同,會使得距離的計算'有問題'。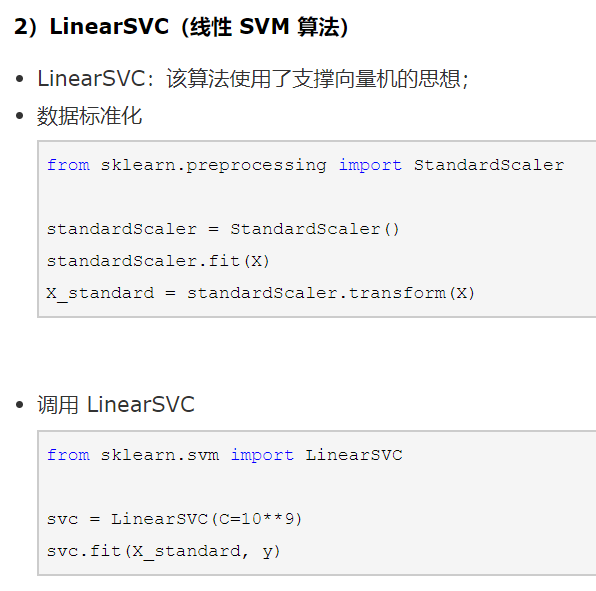
Then
#最後附上適合這篇的github
1. cryer/face_recognition
2. erhwenkuo/deep-learning-with-keras-notebooks

