
在2000年時,ML研究者因為掌握了電腦運算能力,進而發展出一種集成學習 (Ensenble method)的方法,可以想像如果很多個學習能力較弱的學習者各自進行學習時,得出的結果可能會不大理想,但如果將所有學習者集合在一起,則可以組成一股強大的學習能量,就像是有些人比起自己在家讀書,在補習班或在晚自習跟大家一起學習可以得到更好的學習結果一樣。
接著,深度神經網路(Deep Neural Networks, DNN)不但裡用此種方式進行學習,更透過Dropout之方式,隨機將其中部分之神經元刪除,以此方法讓模型能夠更恰當,以及避免過適化 (Overfitting) ,也就是模型不會經由學習某些極少數特別資料,導致最後產生出了一個幾乎無法應用在其他資料上的分類等,而如果應用此種方式,可以讓過於複雜的問題簡單化,例如客服系統應用此種方式的話,通常可以達到用比較簡單的方式回答客人的複雜問題,而且回答的也的確是客人想了解的內容。
應用集成學習中最有名的演算法之一為隨機森林 (Random Forest) ,在傳統決策樹中,我們會將所有的訓練資料都放進去當作輸入,以訓練出一個決策樹,但這樣一來有時候會造成過適化等問題,因此在隨機森林中,並不會只產生出一個決策樹,而是透過建立出多個決策樹,每個決策樹都是由完整個訓練資料中隨機取出部分資料並訓練而成的,許多棵樹在最後組成一個森林,而最後所產出的輸出並非單一決策樹的結果,而是先取得所有存在這個森林中的決策樹之輸出,並將輸出之眾數做為最後輸出結果,如下圖所示。
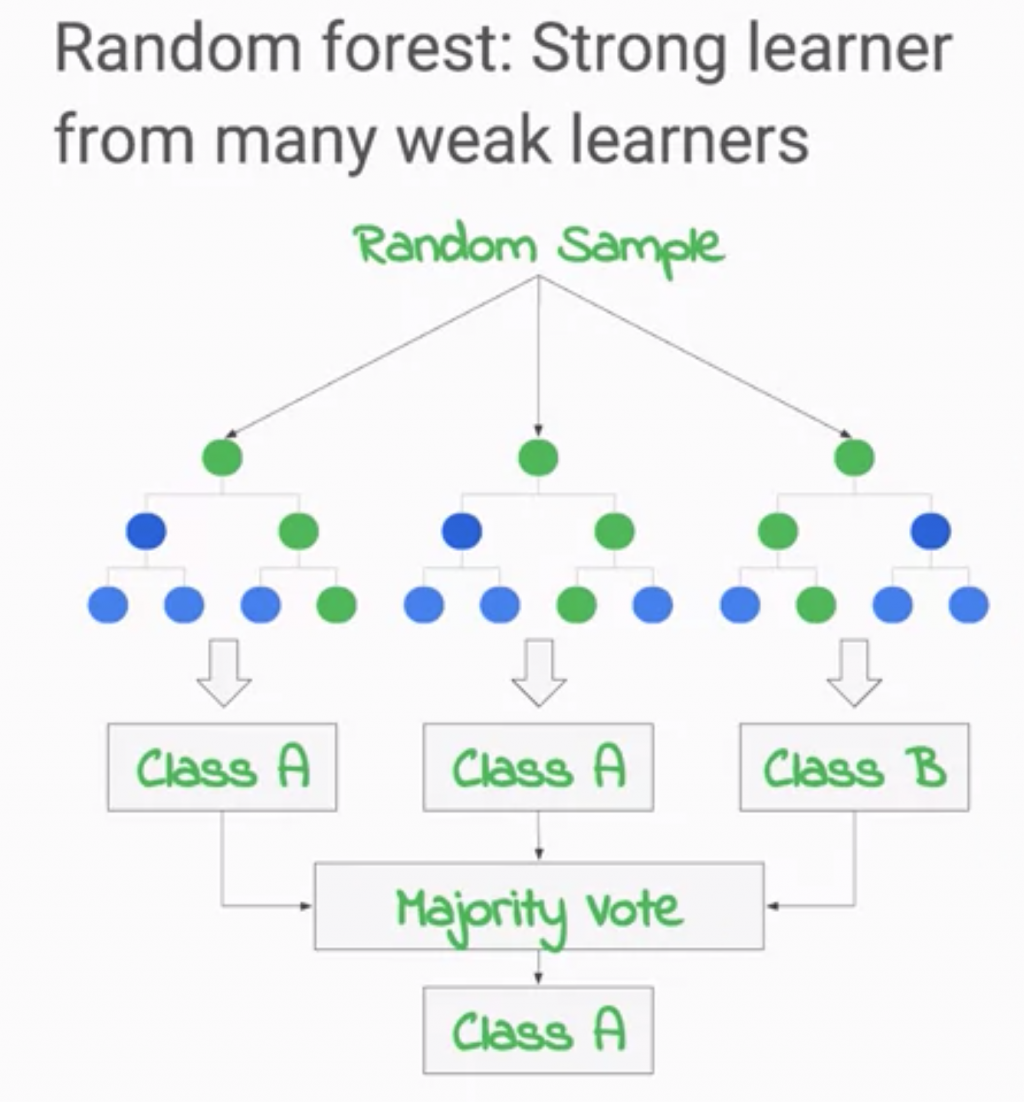
必須要注意的是,森林中的樹並非越多越好,若是樹太多,最後還是可能導致過適化的結果,因此在決定要有多少棵樹的過程中,可以隨時拿測試資料來進行驗證,若輸出之結果以達到標準,則可考量不用再繼續種樹了。
